







 这篇博客利用威斯康辛大学的乳腺癌诊断数据集,通过决策树或随机森林算法进行分析,探讨肿瘤发病可能性。数据集包含30个特征,涉及细胞核的均值、标准差和最大值。文章介绍了特征意义,并进行了初步的数据总结和特征关系探讨,最后展示了使用sklearn库进行数据加载和五折交叉验证的代码实现。
这篇博客利用威斯康辛大学的乳腺癌诊断数据集,通过决策树或随机森林算法进行分析,探讨肿瘤发病可能性。数据集包含30个特征,涉及细胞核的均值、标准差和最大值。文章介绍了特征意义,并进行了初步的数据总结和特征关系探讨,最后展示了使用sklearn库进行数据加载和五折交叉验证的代码实现。
仅供自己学习使用!!!
这篇博客先对数据集做一些介绍
参考链接:http://docode.techyoung.cn/breast_cancer_wisconsin.html
乳腺癌的早期诊断意义重大!
数据集:威斯康辛大学关于乳腺癌诊断数据集
链接:https://archive.ics.uci.edu/ml/datasets/Breast+Cancer+Wisconsin+%28Diagnostic%29

数据集共有30个特征,前10个特征是样本图像中细胞核特征值的平均值:

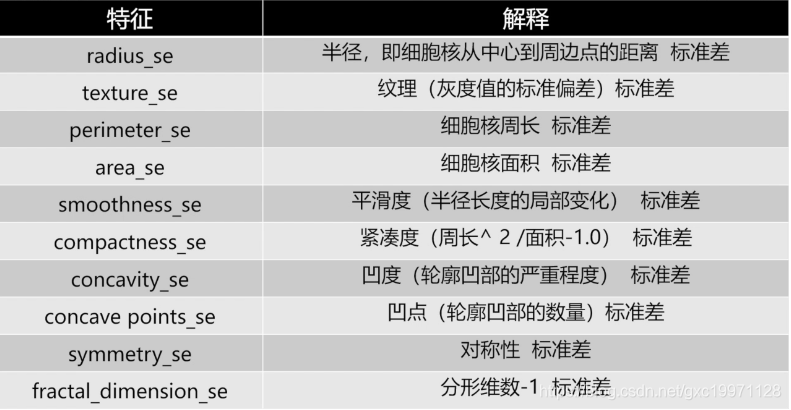
第11到第20个特征为样本图像中细胞核特征值的标准差,反映的是在一个样本图像中不同细胞核在各个特征数值上的波动情况:
第21到30个特征为样本图像中细胞核特征值的最大值,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1769
1769

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









