







 本文深入探讨了G网络(即SR网络)的概念,并详细解释了GAN中D网络的作用。重点介绍了三种不同的权重初始化方法:正态分布初始化、Kaiming初始化和正交初始化,这些方法在PyTorch中实现,并应用于SRResNet、FSRCNN等超分辨率生成模型。
本文深入探讨了G网络(即SR网络)的概念,并详细解释了GAN中D网络的作用。重点介绍了三种不同的权重初始化方法:正态分布初始化、Kaiming初始化和正交初始化,这些方法在PyTorch中实现,并应用于SRResNet、FSRCNN等超分辨率生成模型。
G网络其实就是SR网络,D网络是对抗用的,作为GAN的。在原代码中的network.py可以改变权重初始化的方式(关于代码,请参考博文基于pytorch的FSRCNN)
def weights_init_normal(m, std=0.02):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
init.normal_(m.weight.data, 0.0, std)
if m.bias is not None:
m.bias.data.zero_()
elif classname.find('Linear') != -1:
init.normal_(m.weight.data, 0.0, std)
if m.bias is not None:
m.bias.data.zero_()
elif classname.find('BatchNorm2d') != -1:
init.normal_(m.weight.data, 1.0, std) # BN also uses norm
init.constant_(m.bias.data, 0.0)
def weights_init_kaiming(m, scale=1):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
init.kaiming_normal_(m.weight.data, a=0, mode='fan_in')
m.weight.data *= scale
if m.bias is not None:
m.bias.data.zero_()
elif classname.find('Linear') != -1:
init.kaiming_normal_(m.weight.data, a=0, mode='fan_in')
m.weight.data *= scale
if m.bias is not None:
m.bias.data.zero_()
elif classname.find('BatchNorm2d') != -1:
init.constant_(m.weight.data, 1.0)
init.constant_(m.bias.data, 0.0)
def weights_init_orthogonal(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
init.orthogonal_(m.weight.data, gain=1)
if m.bias is not None:
m.bias.data.zero_()
elif classname.find('Linear') != -1:
init.orthogonal_(m.weight.data, gain=1)
if m.bias is not None:
m.bias.data.zero_()
elif classname.find('BatchNorm2d') != -1:
init.constant_(m.weight.data, 1.0)
init.constant_(m.bias.data, 0.0)
def init_weights(net, init_type='kaiming', scale=1, std=0.02):
# scale for 'kaiming', std for 'normal'.
print('initialization method [{:s}]'.format(init_type))
if init_type == 'normal':
weights_init_normal_ = functools.partial(weights_init_normal, std=std)
net.apply(weights_init_normal_)
elif init_type == 'kaiming':
weights_init_kaiming_ = functools.partial(weights_init_kaiming, scale=scale)
net.apply(weights_init_kaiming_)
elif init_type == 'orthogonal':
net.apply(weights_init_orthogonal)
else:
raise NotImplementedError('initialization method [{:s}] not implemented'.format(init_type))
####################
# define network
####################
# Generator
def define_G(opt):
gpu_ids = opt['gpu_ids']
opt_net = opt['network_G']
which_model = opt_net['which_model_G']#hear decide which model, and thia para is in .json. if you add a new model, this part must be modified
if which_model == 'sr_resnet': # SRResNet
netG = arch.SRResNet(in_nc=opt_net['in_nc'], out_nc=opt_net['out_nc'], nf=opt_net['nf'], \
nb=opt_net['nb'], upscale=opt_net['scale'], norm_type=opt_net['norm_type'], \
act_type='relu', mode=opt_net['mode'], upsample_mode='pixelshuffle')
#############################################################################################################
elif which_model=='fsrcnn':#FSRCNN
netG=arch.FSRCNN(in_nc=opt_net['in_nc'], out_nc=opt_net['out_nc'], nf=opt_net['nf'], \
nb=opt_net['nb'], upscale=opt_net['scale'], norm_type=opt_net['norm_type'], \
act_type='relu', mode=opt_net['mode'], upsample_mode='pixelshuffle')
#############################################################################################################
elif which_model == 'sft_arch': # SFT-GAN
netG = sft_arch.SFT_Net()
elif which_model == 'RRDB_net': # RRDB
netG = arch.RRDBNet(in_nc=opt_net['in_nc'], out_nc=opt_net['out_nc'], nf=opt_net['nf'],
nb=opt_net['nb'], gc=opt_net['gc'], upscale=opt_net['scale'], norm_type=opt_net['norm_type'],
act_type='leakyrelu', mode=opt_net['mode'], upsample_mode='upconv')
else:
raise NotImplementedError('Generator model [{:s}] not recognized'.format(which_model))
if opt['is_train']:
init_weights(netG, init_type='kaiming', scale=0.1)###the weight initing. you can change this to change the method of init_weight
if gpu_ids:
assert torch.cuda.is_available()
netG = nn.DataParallel(netG)
return netG
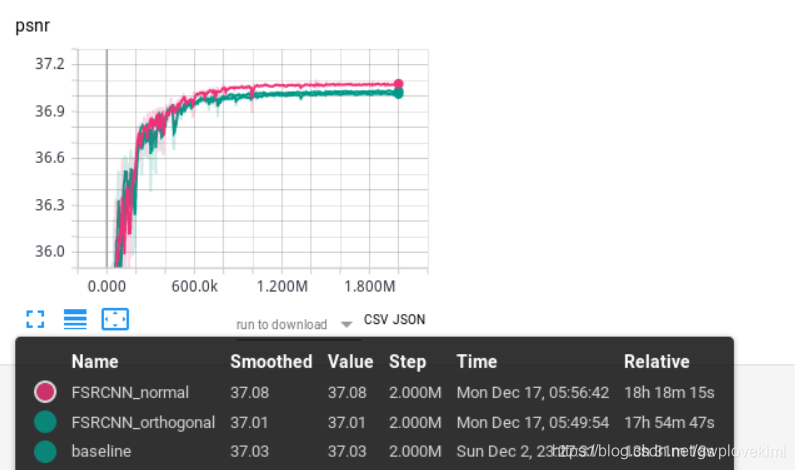
之前做的都是kaiming权重初始化,现在试试其他两种:
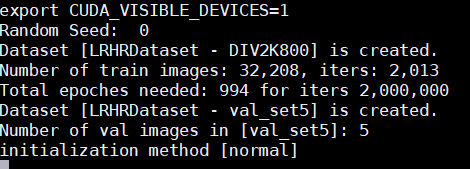
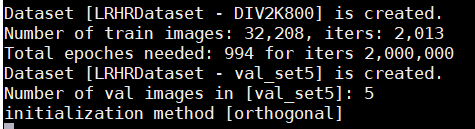
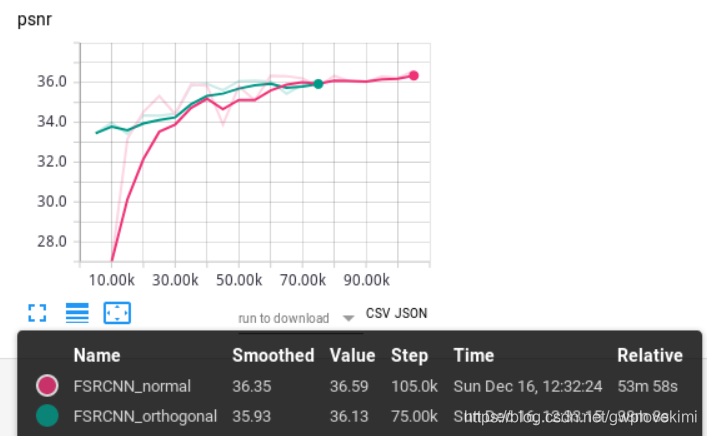
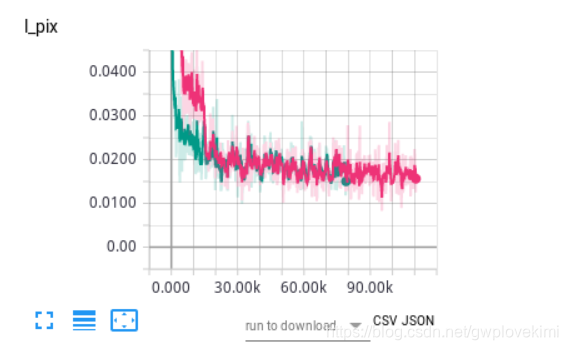
结果如下图所示
关于pytorch中的init
https://www.pytorchtutorial.com/docs/package_references/nn_init/(官网)
https://blog.youkuaiyun.com/qq_19598705/article/details/80396047

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









