







对于链表的优缺点,我们对比数组可以说出一些,但在随机存储的情况下,我们会选择链表来处理,而我们使用双向链表时,经常会定义成如下形式:
struct list_node {
TYPE data;
struct list_node *prev,*next;
};相对应的链表结构如下:

对于该数据结构定义,存在一个局限,整个结构中只能有一个双向循环链表,而不能存在多个,并且链表的操作只能针对该数据结构操作,没能通用,而在Linux Kernel(下面以3.0.8版本为例)中则把链表与数据域分开了,实现通用链表结构及操作,其定义存在于include/linux/types.h文件中,形式如下:
struct list_head {
struct list_head *next, *prev;
};上面是通用链表的结构,而利用该定义,我们可以把我们常用的双向链表定义为如下形式:
struct list_node {
TYPE data;
struct list_head list;
};相应的链表结构如下:
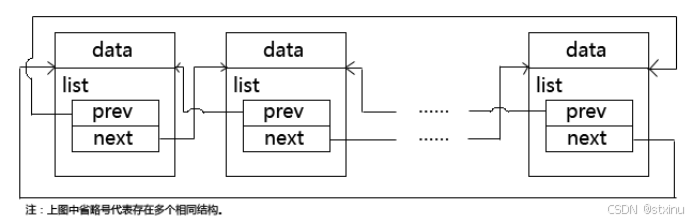
从图中可以看出,其链表只是通过list_head这个结构体连接起来,这样就只能对链表结构操作了?那么data要如何操作呢?这就是linux 通用链表的技巧所在了,把链表独立出来,而不用去管其数据是什么,链表的操作得到了统一。我们继续往下分析,来体验linux的算法之美。
在linux内核源码的include/linux/list.h文件中包含了链表的操作,首先我们先来看看如何通过list_head的地址来找到包含它的结构体元素的首地址,在list.h文件中有如下的宏:
#define list_entry(ptr, type, member) \
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











