数据清洗 去除空格
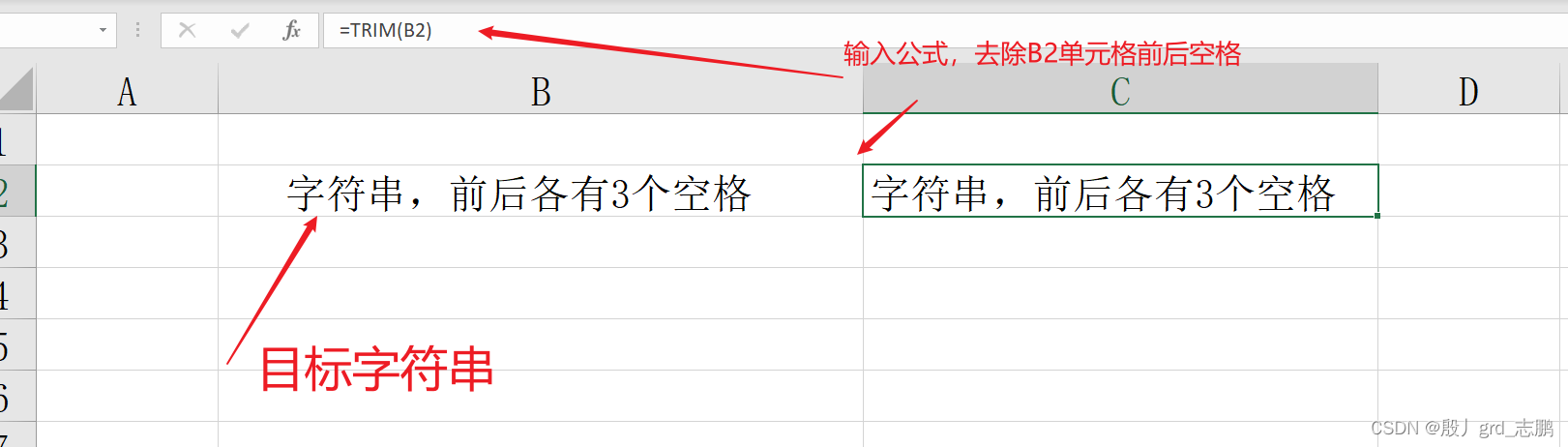
使用trim函数去除两边空格
= trim( text )
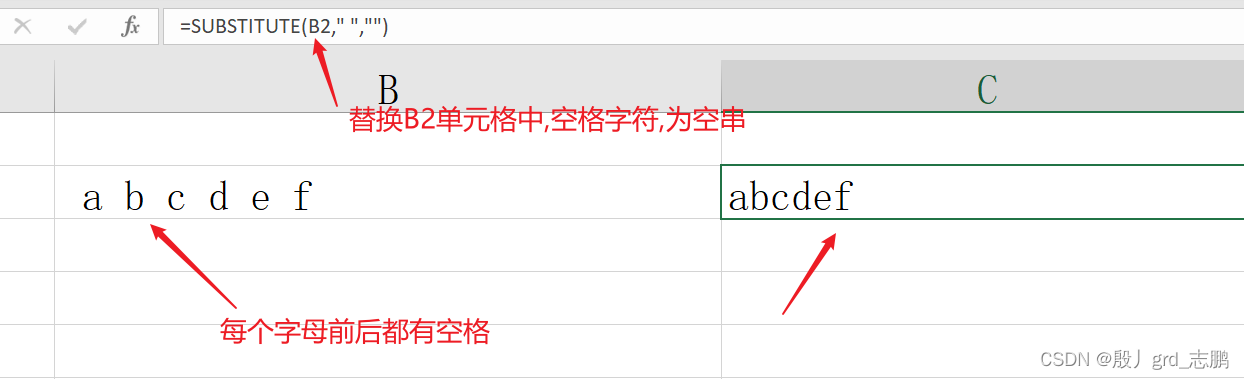
查找替换去除全部空格,选中单元格后按快捷键Ctrl+H即可 substitute函数替换
= substitute( text , old_text, new_text)
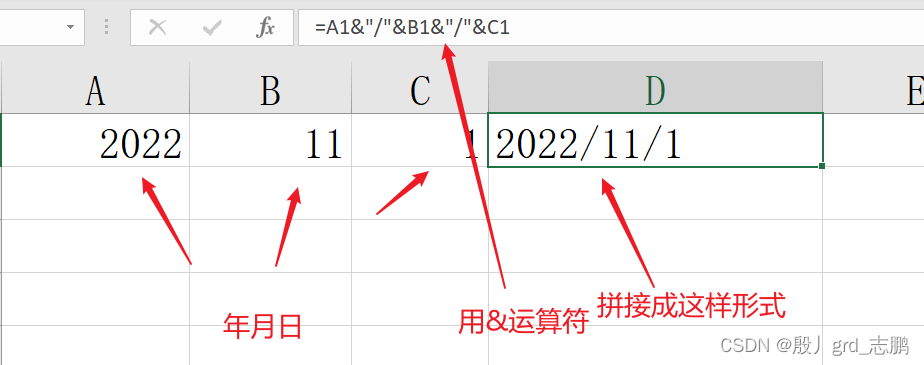
字符串拼接
&:and符号,表示和、与
text1 & text2
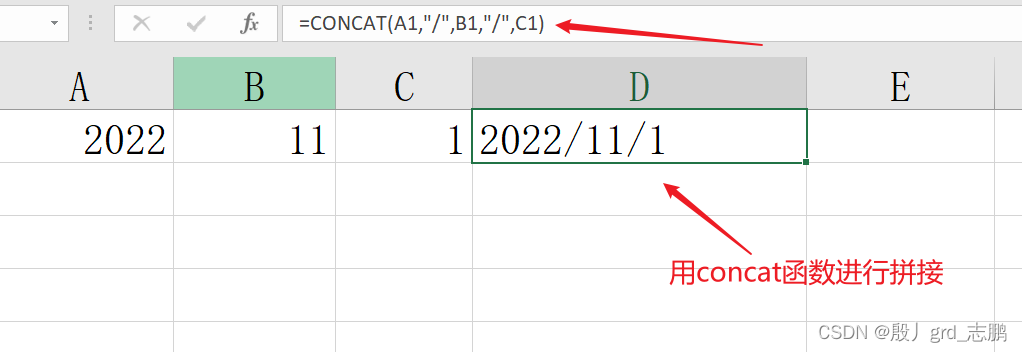
concat函数:拼接指定内容
= concat( text1, [ text2] , . . . )
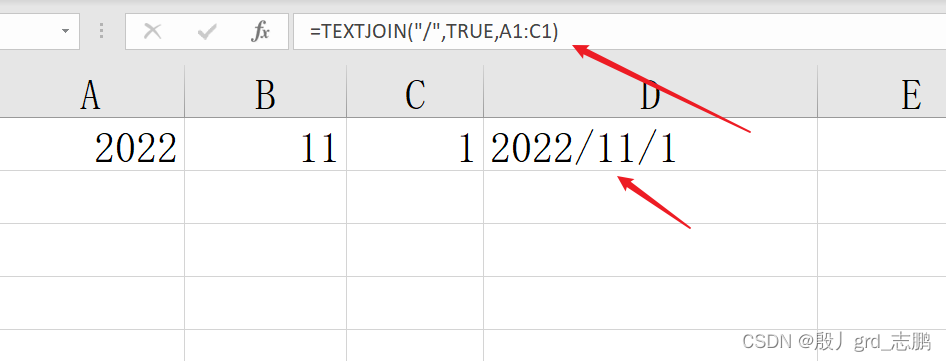
textjoin函数:以指定分隔符拼接
textjoin( 分隔符, TRUE 或False 是否忽略空单元格, 要连接的内容)
字符串截取
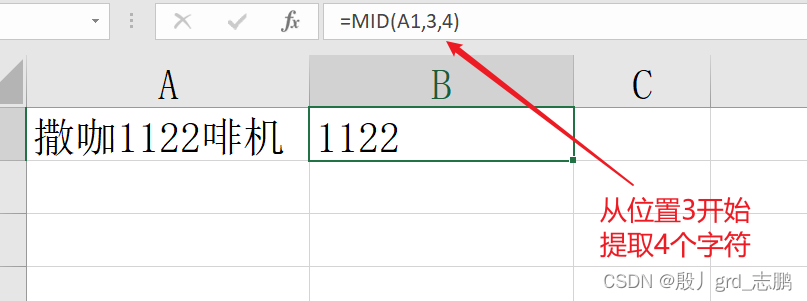
mid函数:提取字符串中间的字符
= mid ( text , start_num, num_chars)
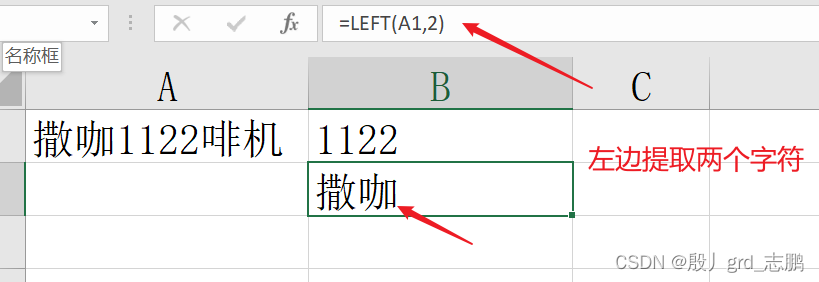
left函数:提取字符串左边的字符
left ( text , [ num_chars] )
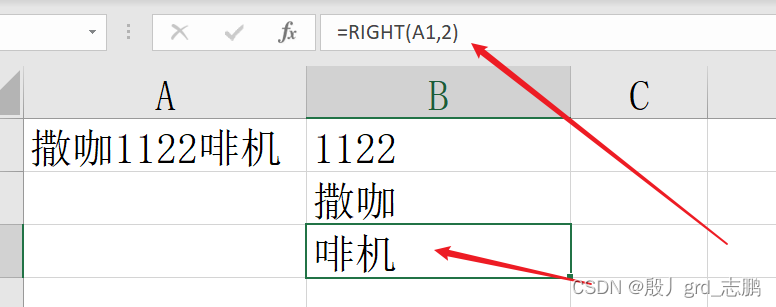
right函数:提取字符串右边的字符
right ( text , [ num_chars] )
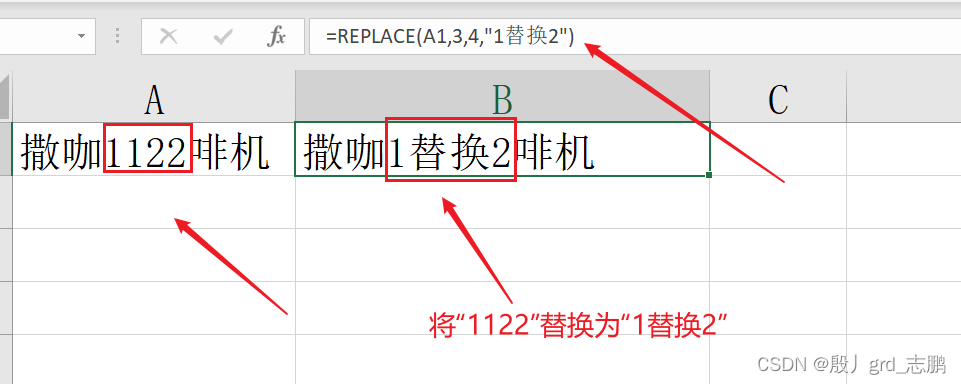
替换函数
replace: 替换字符串中子串
= replace ( text , start_num, num_chars, new_text)
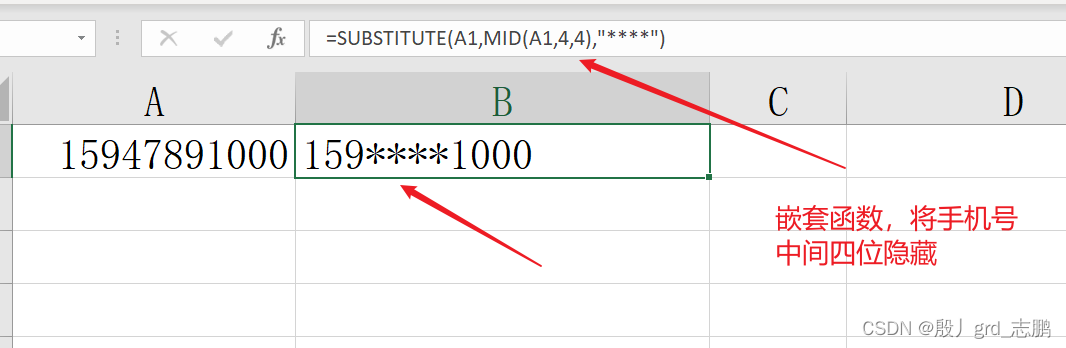
substitute: 替换字符串中子串
= substitute( text , old_text, new_text)
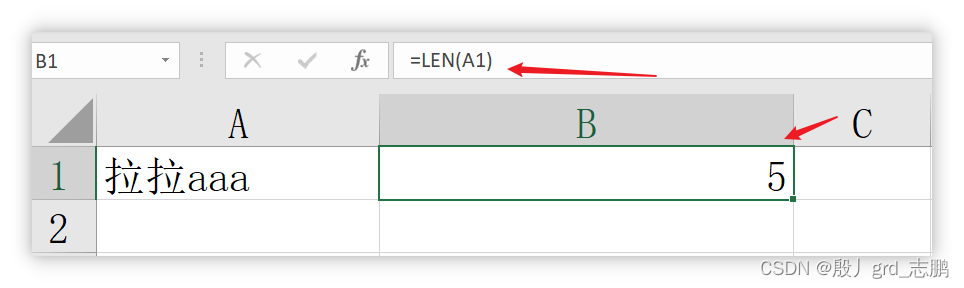
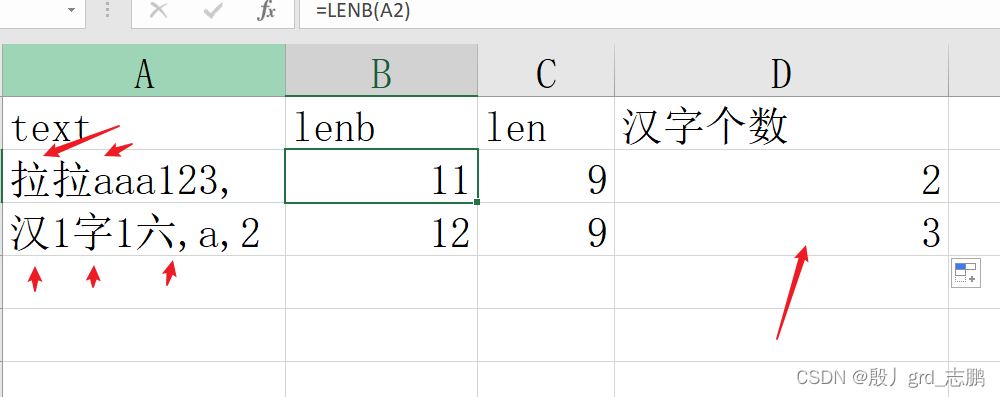
求长度
len函数:返回文本字符串中字符个数,一个中文字符长度计算为1
= len ( text )
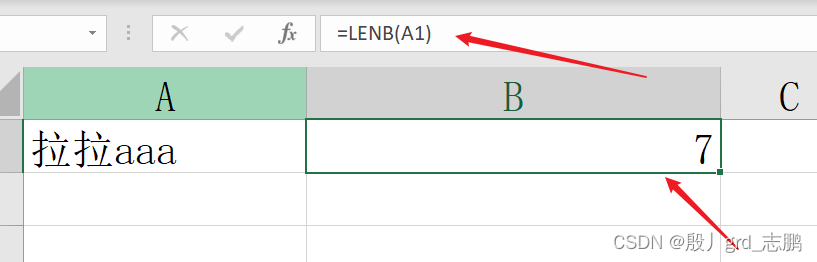
lenb函数:和len唯一不同是,一个中文字符长度算作2
= lenb( text )
求出汉字的个数
因为len函数求的是字符个数,而lenb会在len的基础上,每个汉字额外+1. 所以lenb(text) - len(text) = text中汉字个数
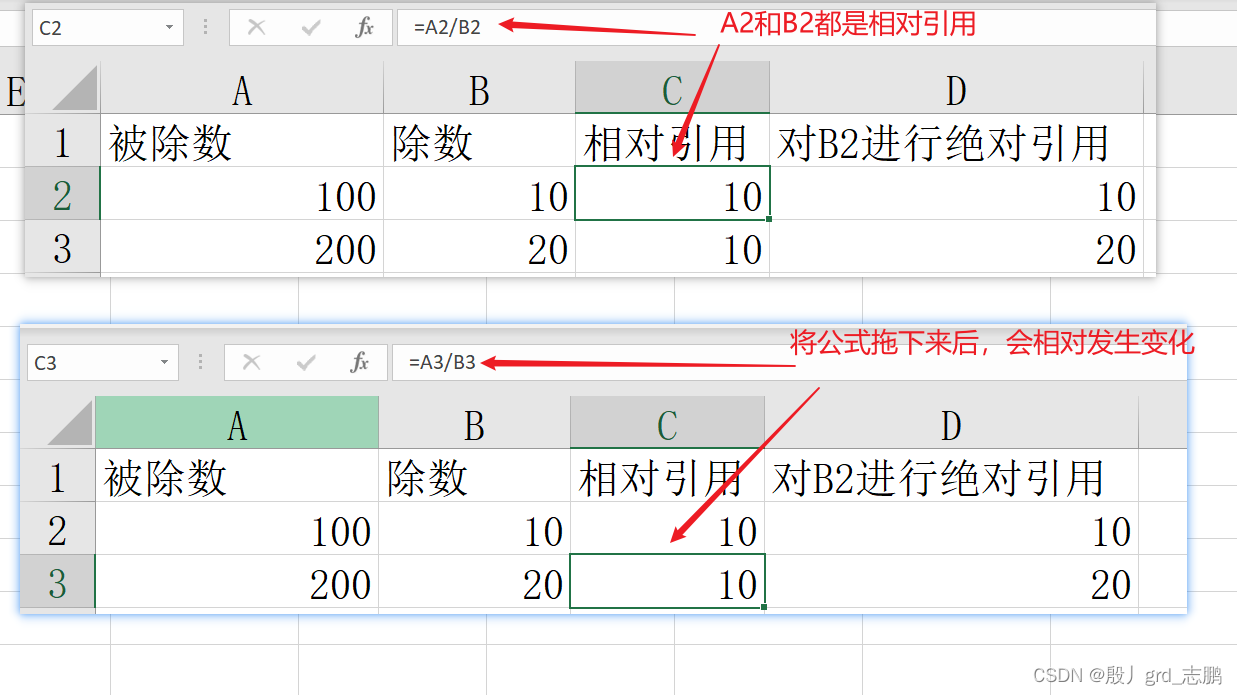
相对引用和绝对引用
相对引用就是公式会随着你位置的变化而自动变化的引用
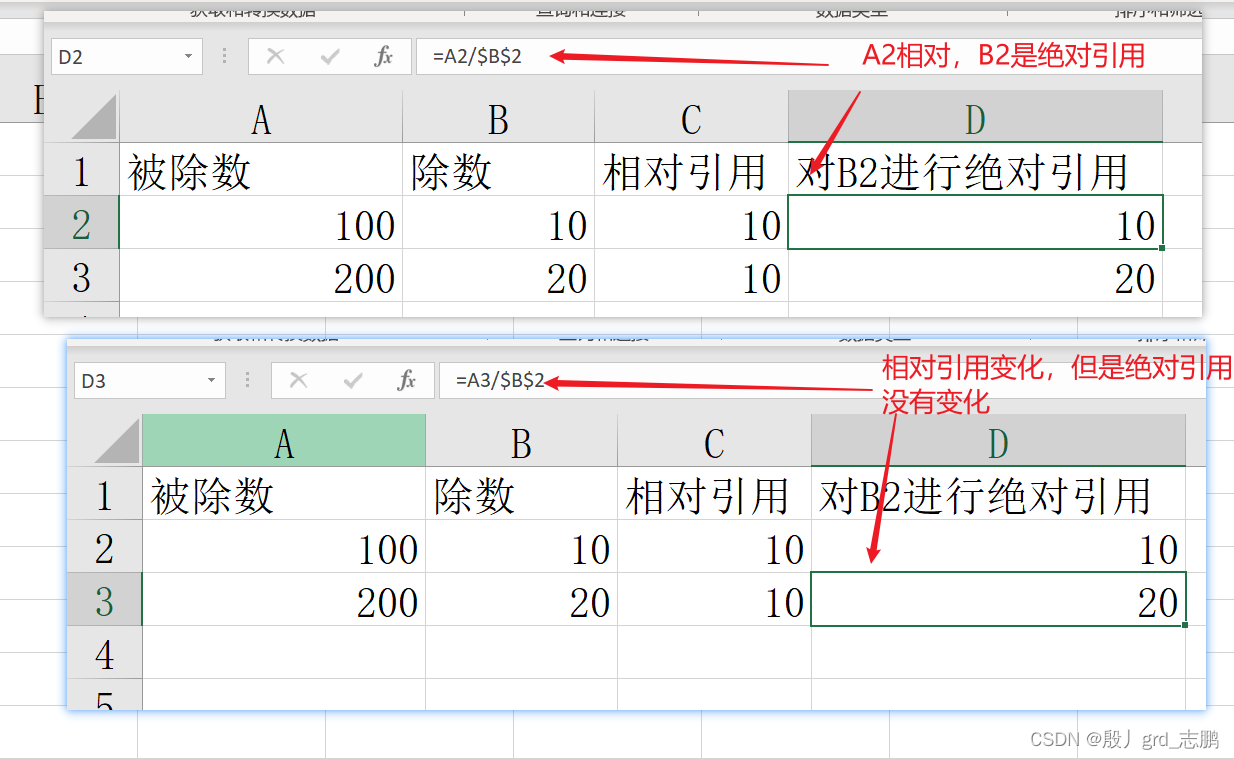
绝对引用就是无论你怎么拖动你的公式,绝对引用的单元格不会相对变动
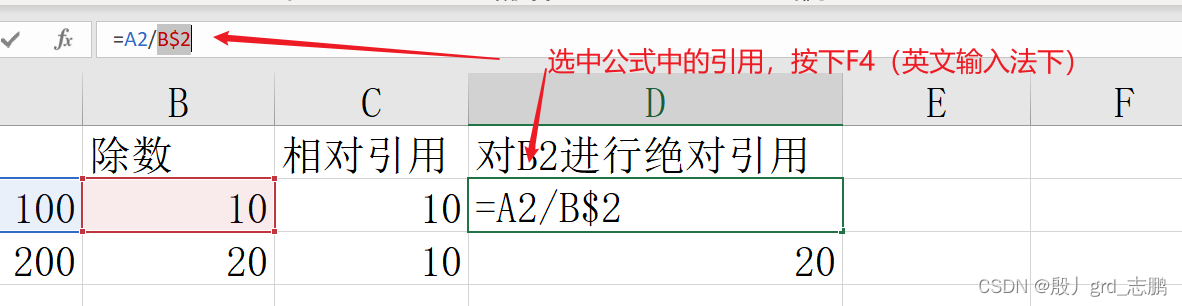
绝对引用的方式就在单元格列号和行号前加上$符号 混合引用只是锁定列,例如$A1,只会锁定A列,行依然会变动。而如果是A$1就是只锁定行,列依然会变动
引用方式切换的快捷键是F4,在公式中对目标引用按下快捷键可以切换引用模式
查找函数和排名排序
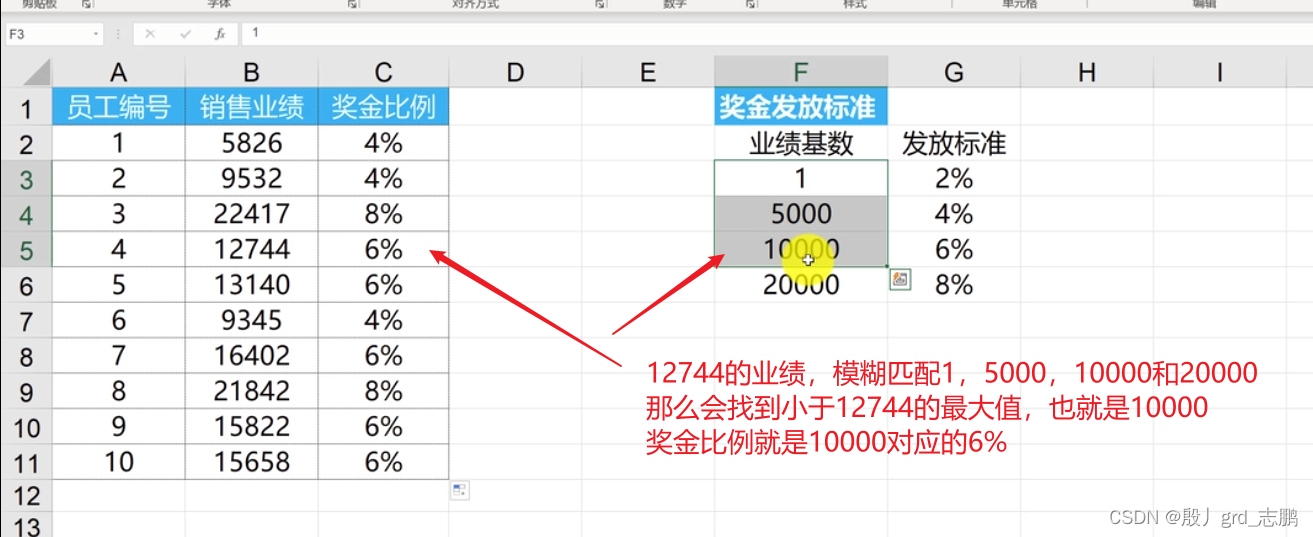
重点:模糊匹配表示近似匹配,会返回小于该数值的最大数值。例如在100,1000,5000,10000,20000里面模糊匹配12000,那么它会返回所有小于12000的值中最大的一个。也就是100,1000,5000,10000,20000里面小于12000的100,1000,5000,10000中的最大值,也就是10000
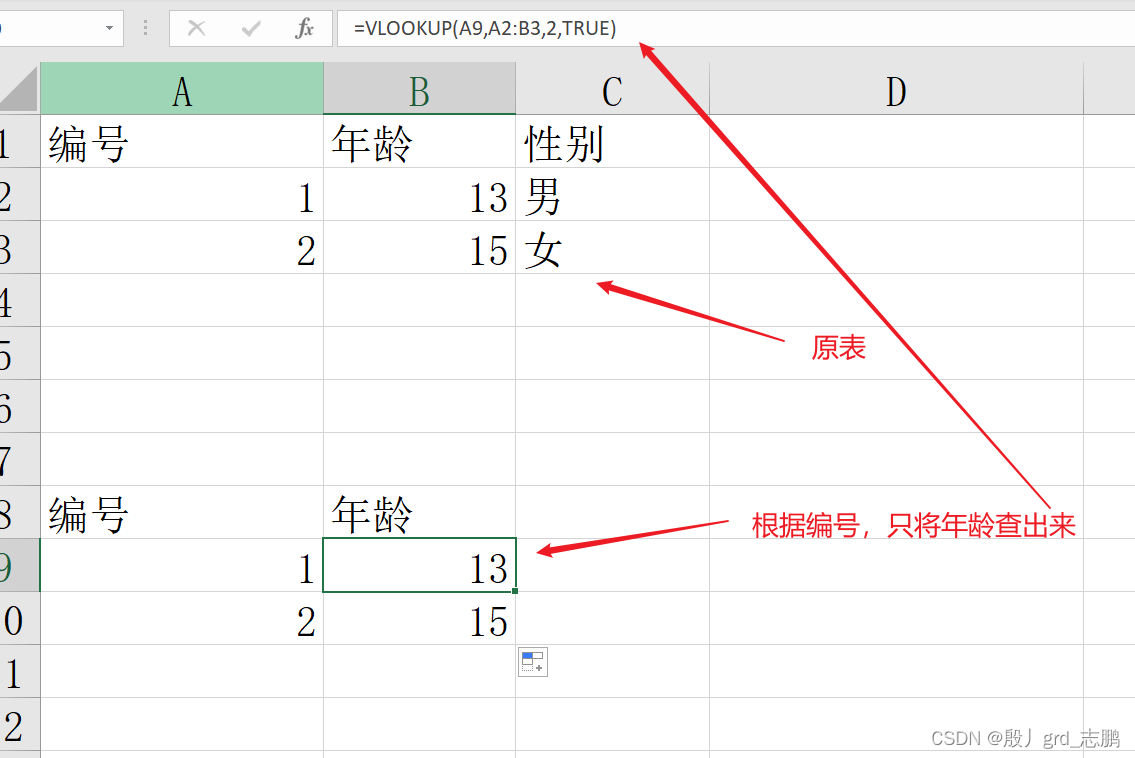
vlookup:纵向查找,搜索表区域首列满足条件的元素,确定待检索单元格在区域中的行序号,再进一步返回选定单元格的值,默认情况下,表以升序排序
vlookup( lookup_value, table_array, col_index_num, range_lookup)
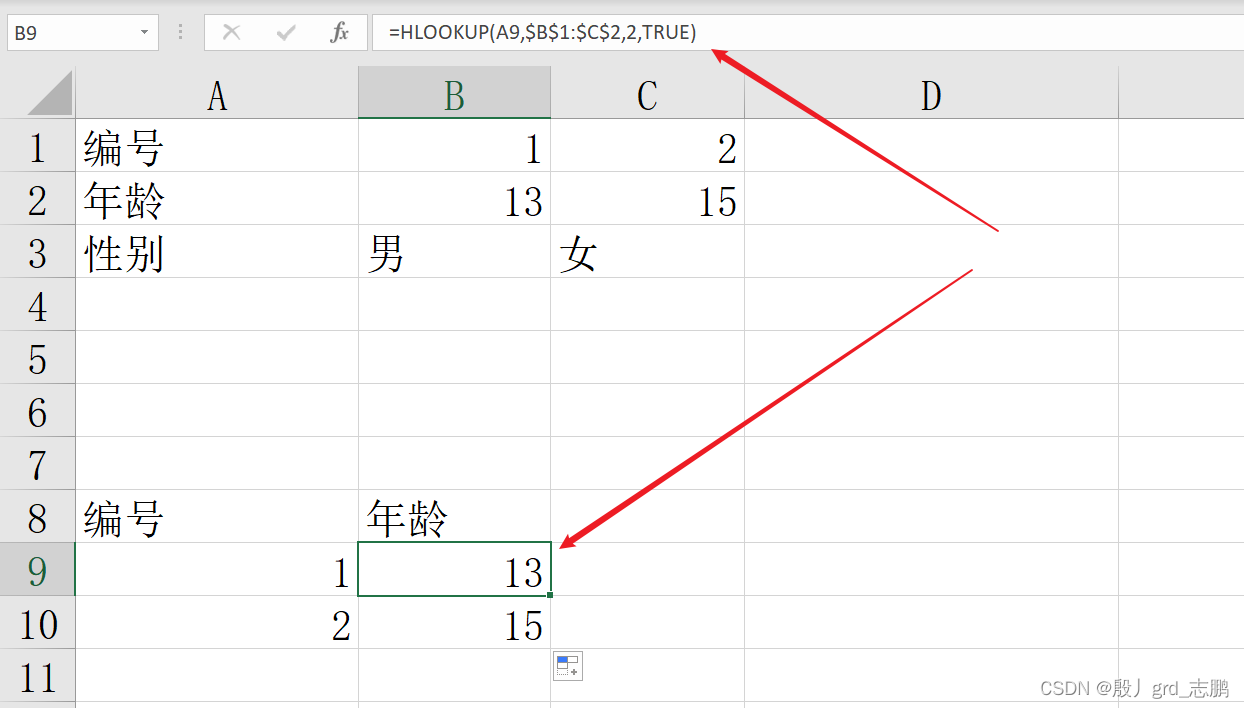
hlookup:横向查找,有些表给的时候和上面的图的表不一样,是横向排列的,因此需要hlookup
hlookup( lookup_value, table_array, row_index_num, [ range_lookup] )
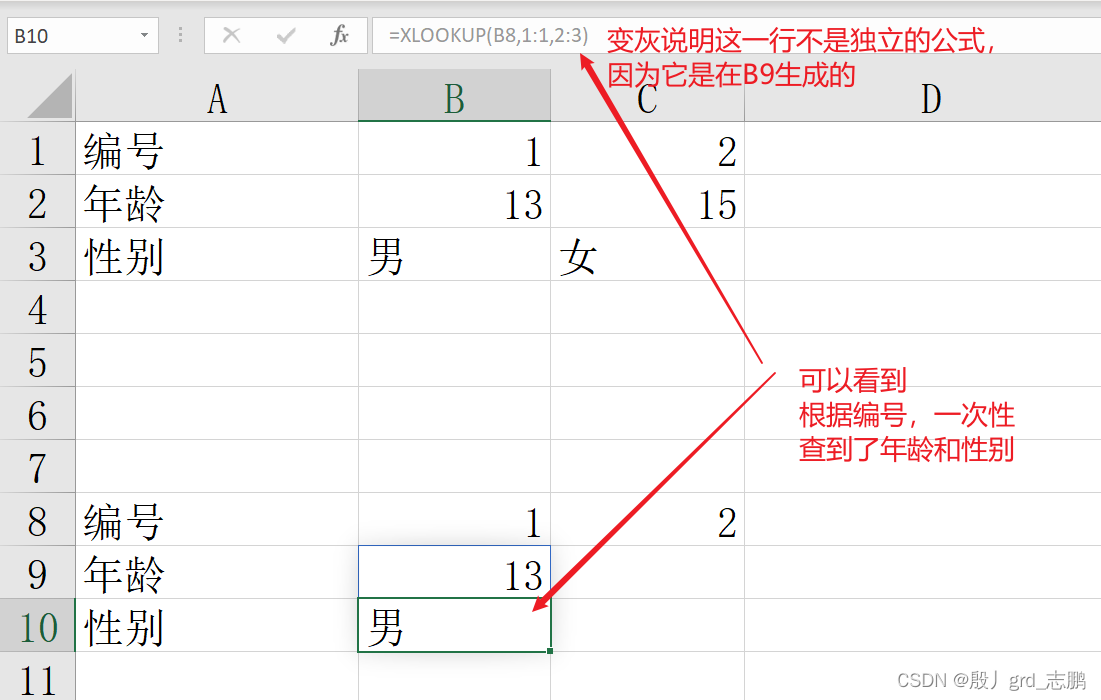
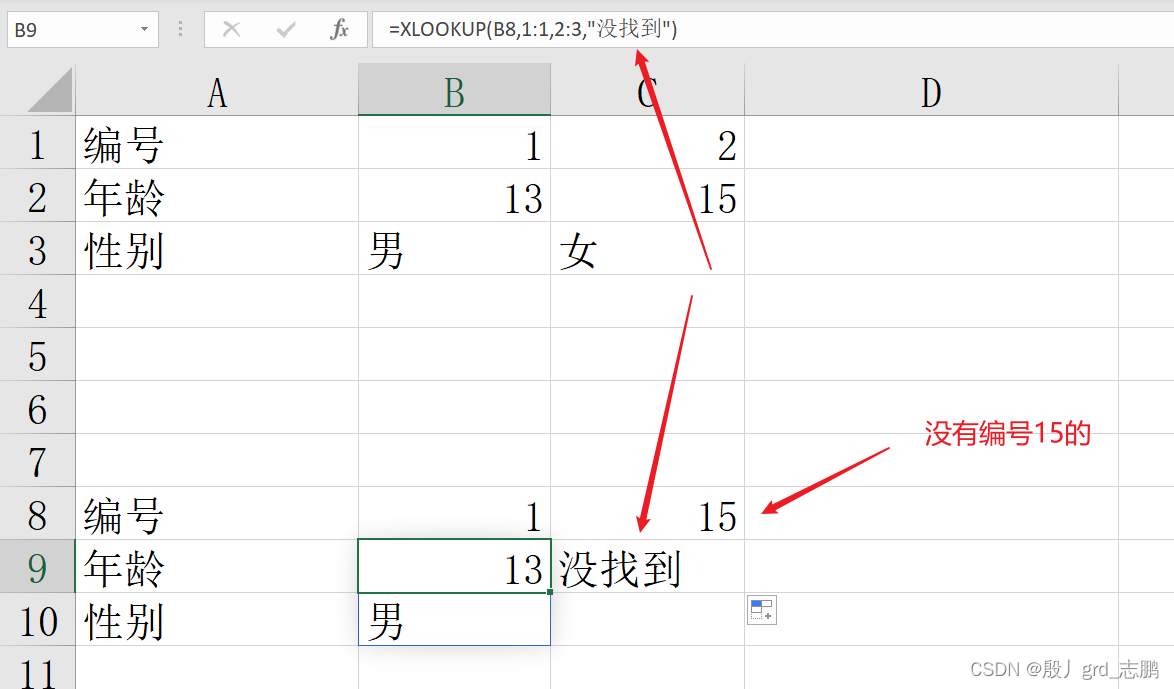
xlookup函数:按行查找表或区域中的东西
多行(列)查找,这里直接演示比较难得行查找 如果找不到,我们可以指定if_not_found参数,在没找到时显示指定值
= xlookup( lookup_value, lookup_array, return_array, [ if_not_found] , [ match_mode] , [ search_mode] )
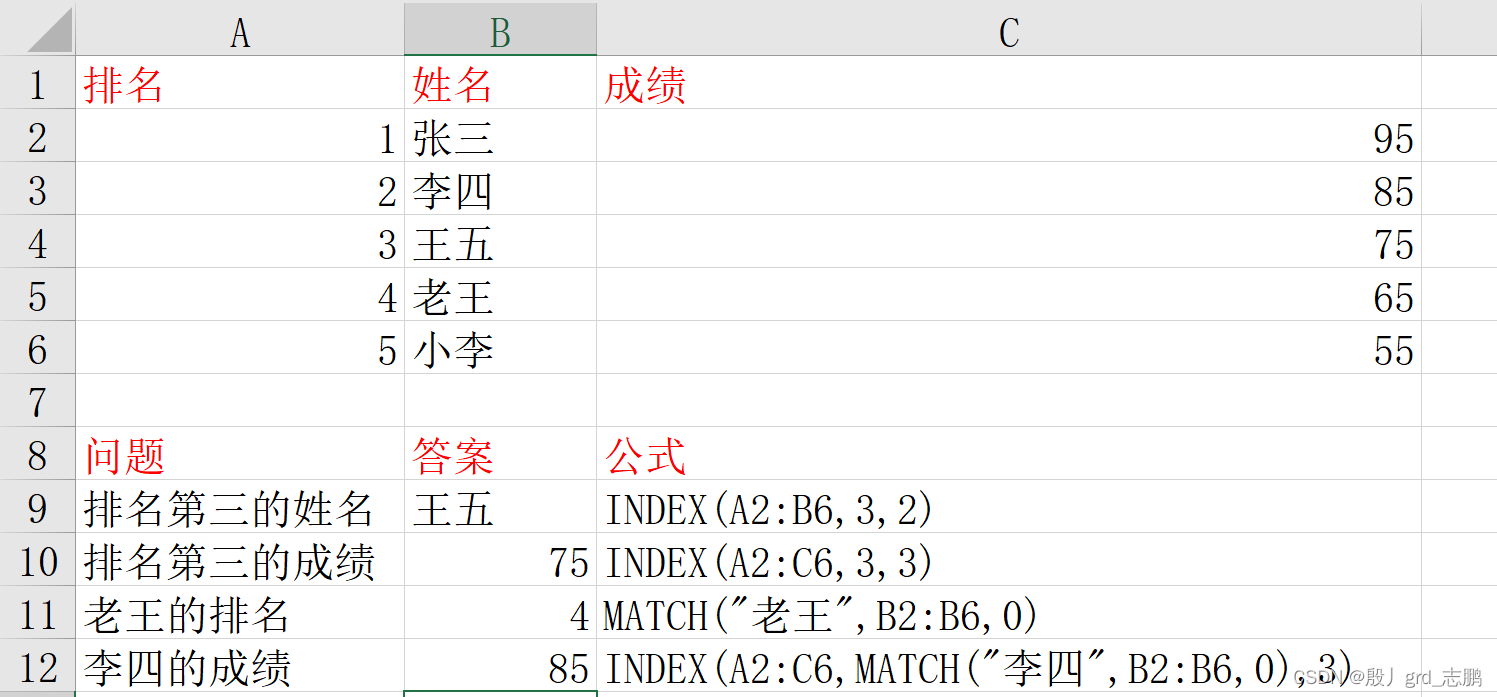
着重掌握index嵌套match的方式,vlookup要求目标字段在第一列,而index和match不限制,要学会如何使用index+match替代vlookup
index函数:根据位置返回单元格的值
index ( array, row_num, [ column_num] )
match函数:根据单元格的值返回位置
match ( lookup_value, lookup_array, [ match_type] )
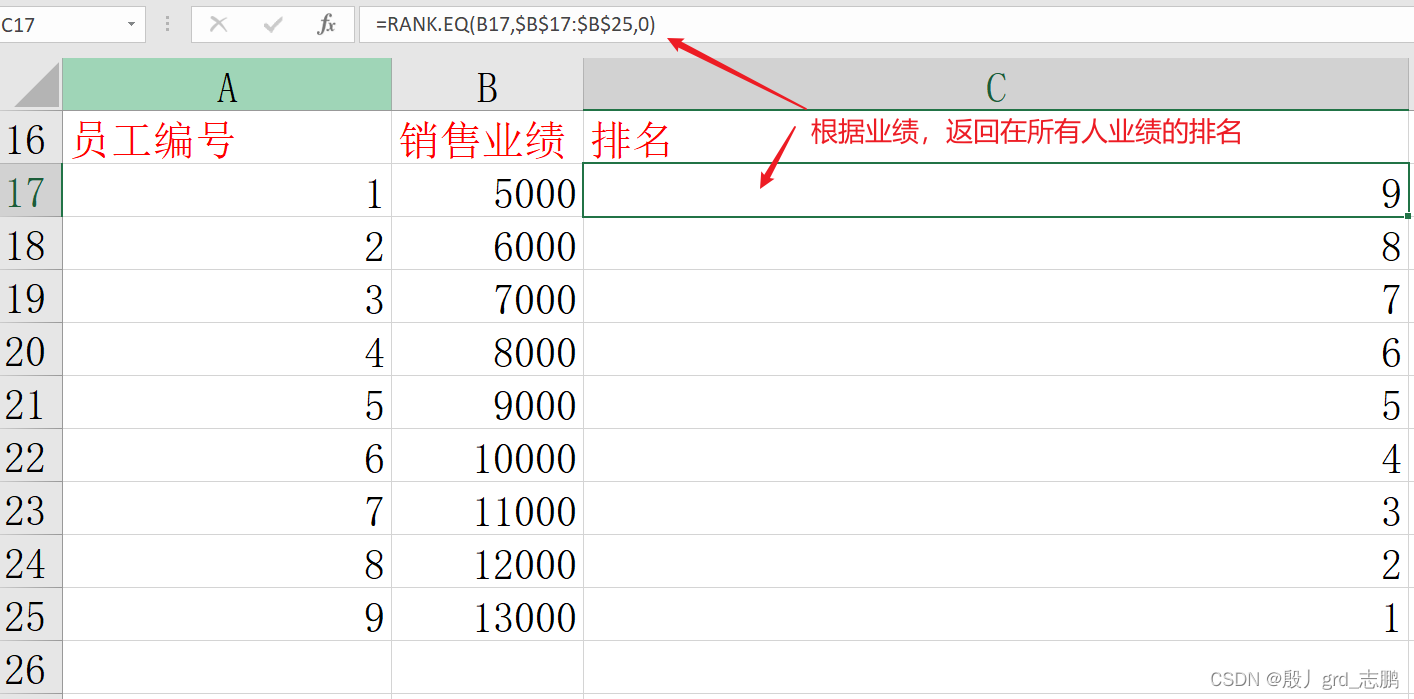
rank函数:返回一列数字的排名
rank.eq:数字相同,排名相同
rank. eq( number, ref, [ order ] )
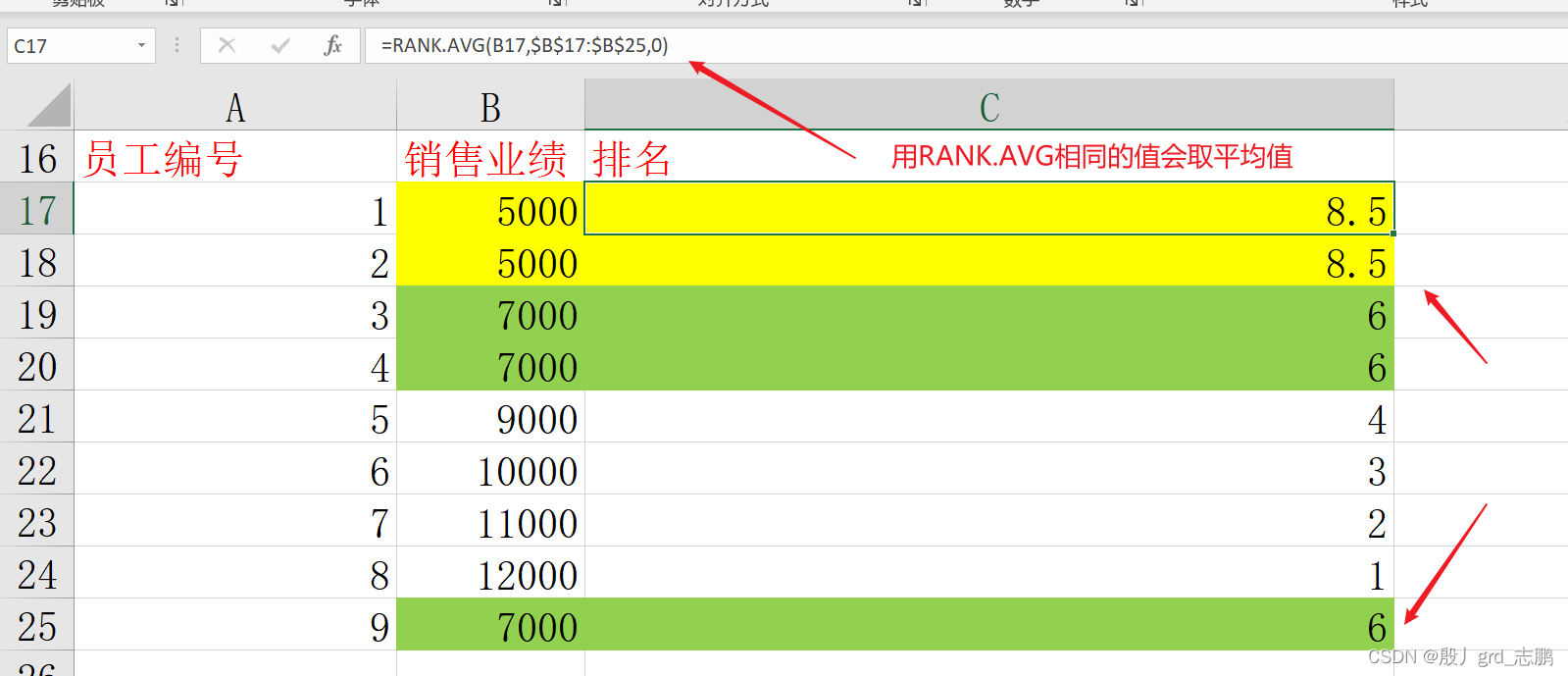
rank.avg:排名相同,取平均
rank. avg ( number, ref, [ order ] )
直接用rank函数排序会出现相同名次的情况 假设现在我们要进行顺位修正,第二个相同排名的自动顺位+1,例如第一个排名第3的就是第三,第二个排名第三的,自动顺位到第4
所以我们现在统计每个排名是第几次重复
知道了第几次重复后,就可以进行顺位了,也就是原rank排名+第几次重复 - 1就是修正后的顺位排名
逻辑运算
用于判断数字或变量之间的逻辑关系
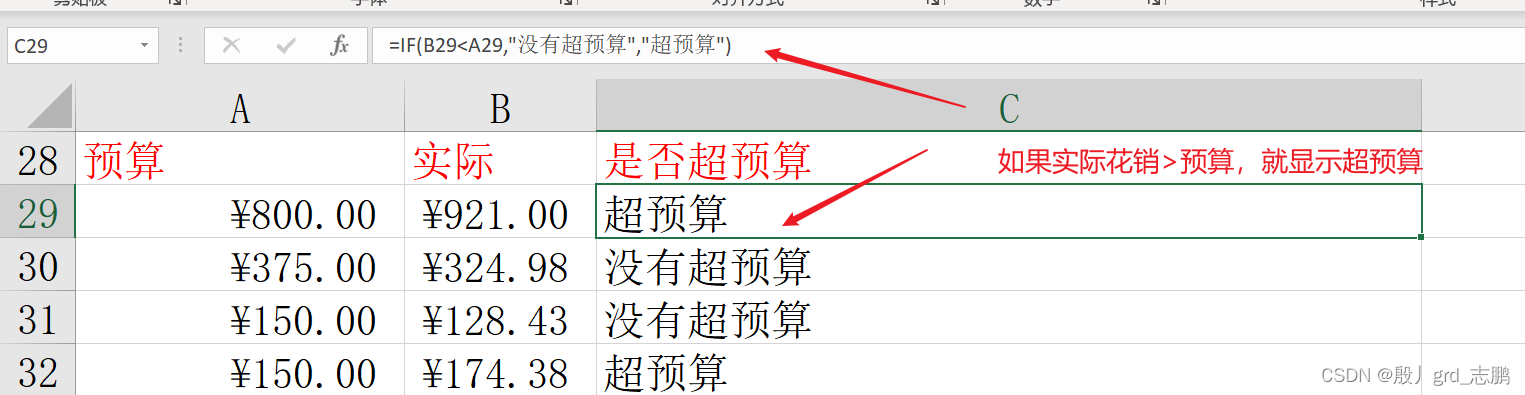
if ( logical_test, value_if_true, [ value_if_false] )
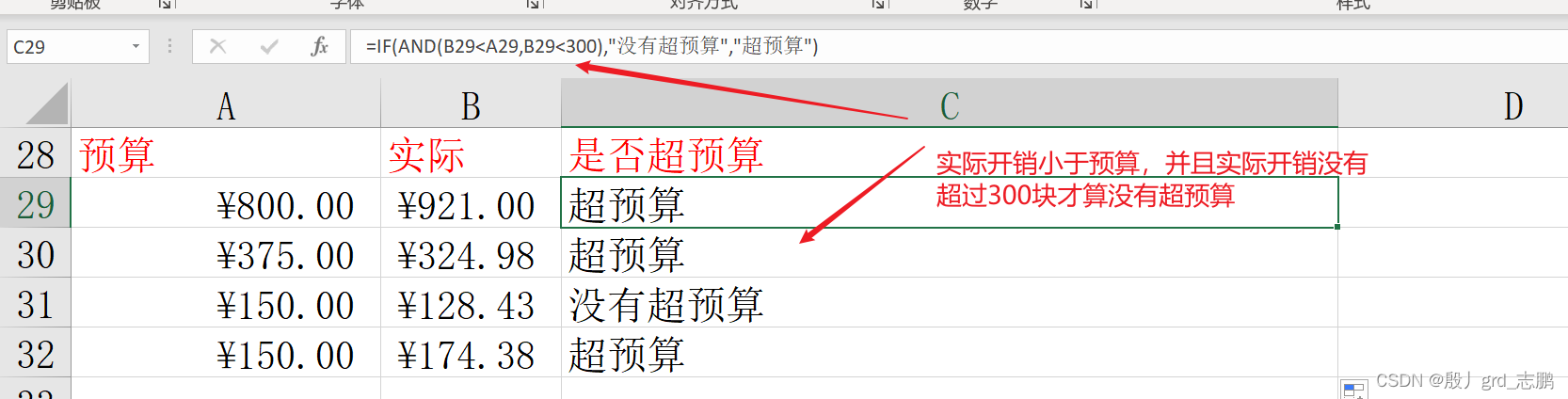
逻辑判断,相当于并且操作。全部参数为True则返回True
AND ( 条件1 , 条件2 , . . . . . )
逻辑判断,相当于或操作,只要一个参数为True,则返回True
OR ( 条件1 , 条件2 , . . . . )
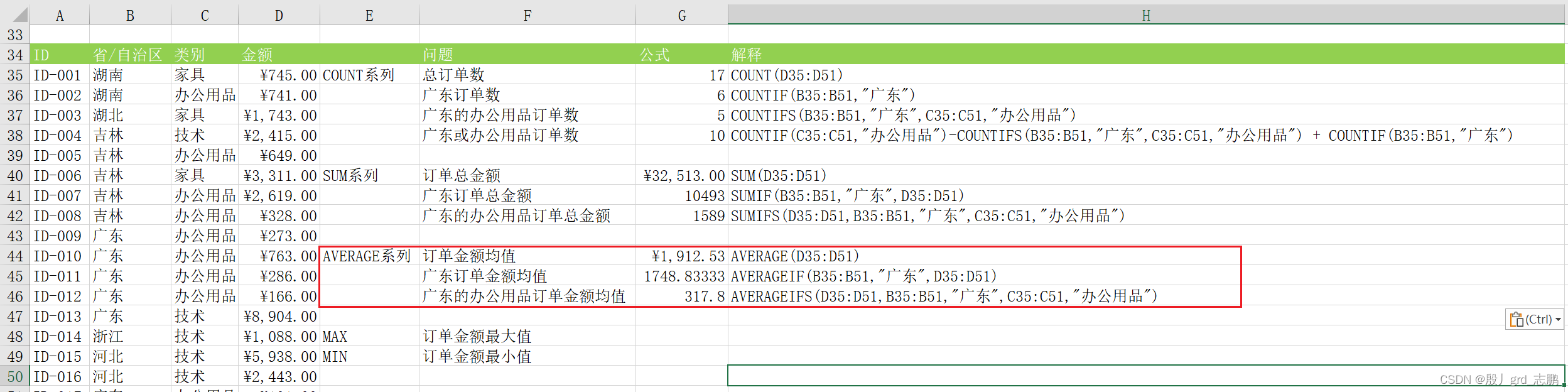
计算统计类 count系列
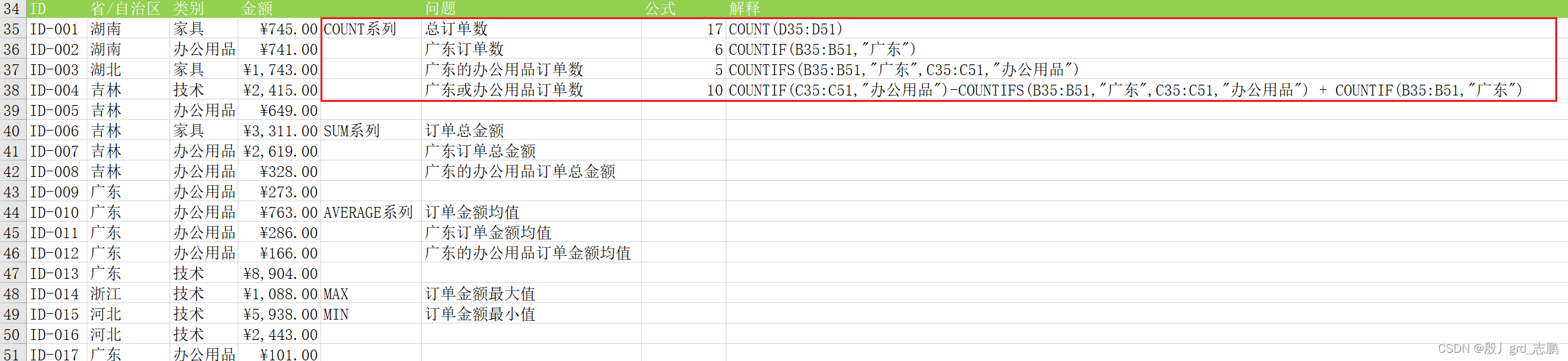
计算包含数字的单元格个数,非数字不统计
count ( value1, [ value2] , . . . )
计算区域非空单元格的个数
counta( value1, [ value2] , . . . )
用于统计满足某个条件的单元格的数量,只能包含一个条件
countif( range, criteria)
计数,多条件统计。也就是可以多个条件统计了
countifs( criteria_range1, criteria1, [ criteria_range2, criteria2] , . . . . )
SUM系列
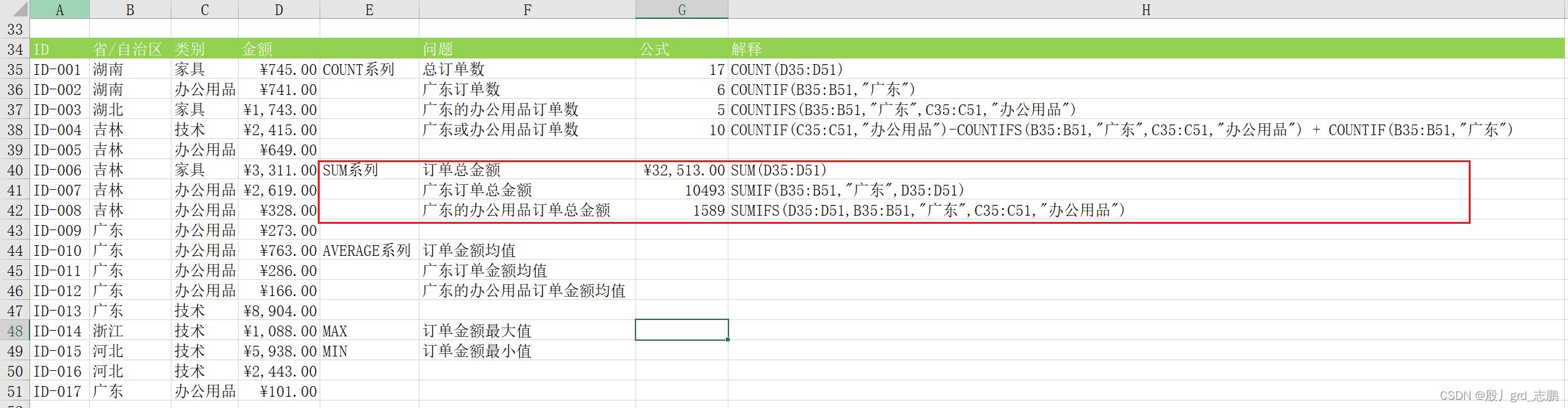
求和,单个值,单元格引用或者区域引用的和
sum ( number1, [ number2] , . . . . )
条件求和,只有满足条件的值才进行求和
sumif( range, criteria, [ sum_range] )
多条件求和
sumifs( sum_range, criteria_range1, criteria1, [ criteria_range2, criteria2] , . . . )
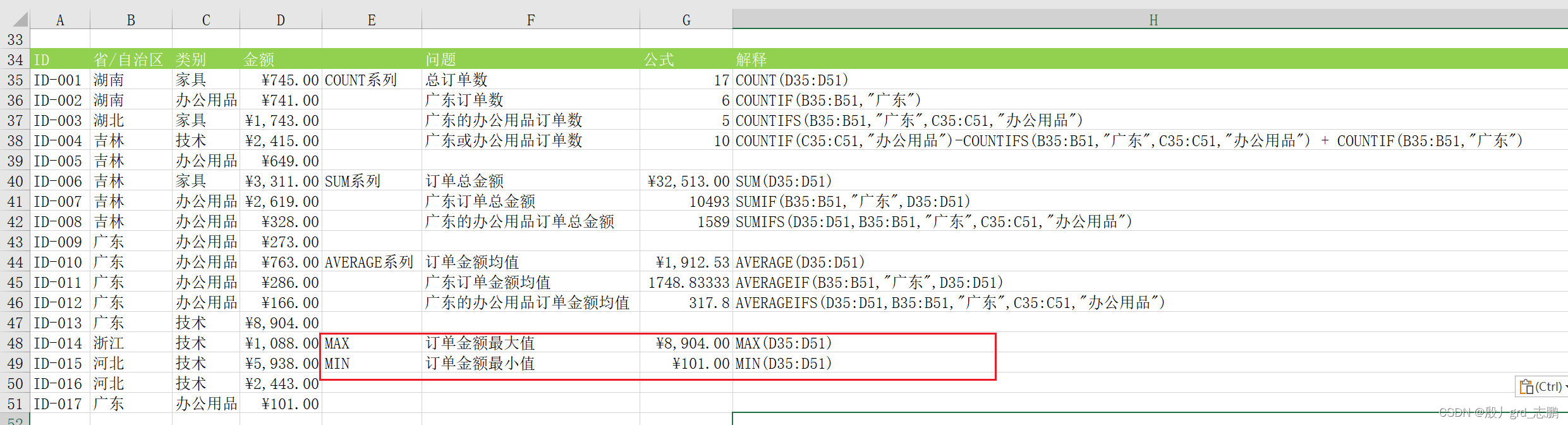
average系列
返回参数平均值(算术平均值)
average( number1, [ number2] , . . . )
返回某个区域内满足给定条件的所有单元格的平均值
averageif( range, criteria, [ average_range] )
返回满足多个条件的所有单元格的平均值
averageifs( average_range, criteria_range1, criteria1, [ criteria_range2, criteria2] , . . . )
MAX和MIN
求最大值
求最小值
substotal
汇总函数,可以求平均值、计数、求和、最大/最小值、标准差、方差等。也就是说,如果你突然忘记了上面介绍的某个函数,这一个汇总函数,可以临时去用它做简单的代替。但它主要作用就对筛选敏感,想要完全替代上面介绍的函数是不可能的,这就是一个汇总函数
substotal( 函数编号, 引用区域)
如果我们不进行筛选,substotal和普通函数结果是一样的 如果进行筛选,substotal的结果是会根据筛选结果发生变化的
时间序列类 时间日期
year:提取日期中的年份
year ( serial_number)
month:提取日期中的月份
month ( serial_number)
day:提取日期中的天数
day ( serial_number)
today():获取当前日期 now():获取当前日期、时间
星期
返回对应于某个日期的一周中的第几天
weekday( serial_number, [ return_type] )
返回特定日期的周数。例如包含1月1日的周为该年的第一周,编号为第一周
weeknum ( serial_number, [ return_type] )
对于2024年7月5号来说,是星期五,那么可以用weekday(2024/7/5,2)来返回5,表示星期5. 对于这一天是2024年第几周,我们用weeknum(2024/7/5,2),来返回27,表示第27周
计算两个日期之间相隔的天数、月数或年数
datedif( start_date, end_date, unit)
2019年11月26日与2022年1月1日相差2年,月数相差25个月,如果是用天来统计是767天 对于年数来说,用公式datedif(2019/11/26,2022/1/1,“Y”)来获取。最后一个参数改成"M"就是月,"D"就是天数
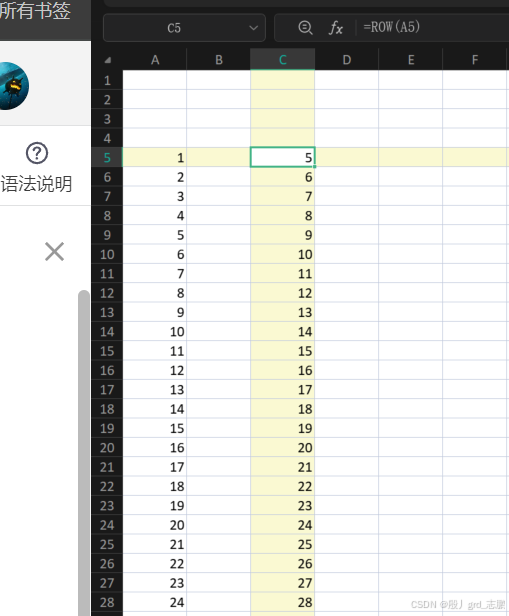
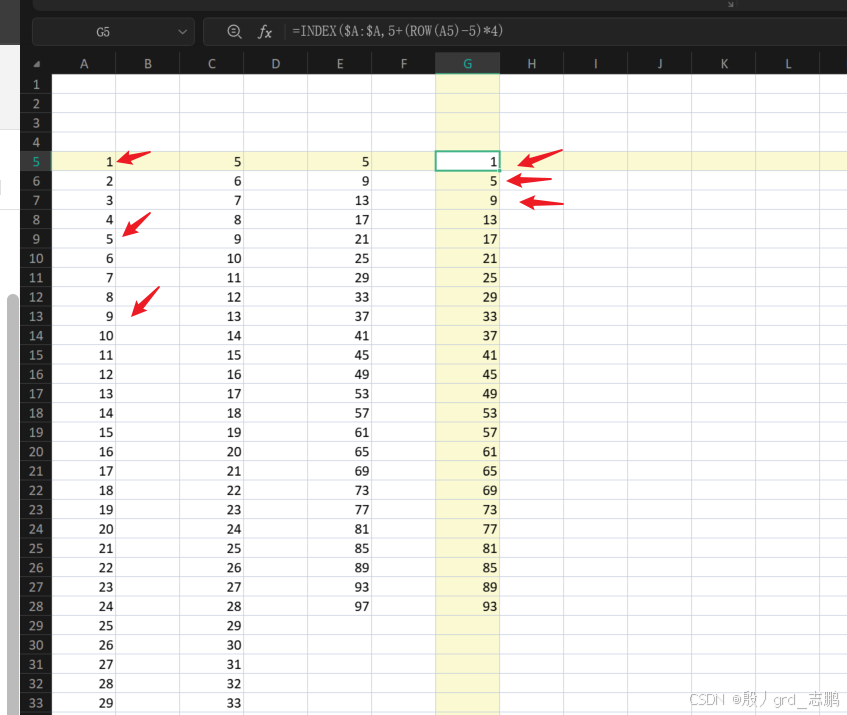
1. 每4行选一次
通过Row函数,它会返回指定位置的行号,例如有一列数据,第一行下标为5
然后每隔4行一次,他们的下标分别是5,9,13,… 只需要通过公式
起始行号
+
(
R
O
W
(
起始行
)
−
起始行号
)
∗
4
起始行号+(ROW(起始行)-起始行号)*4
起始行号 + ( RO W ( 起始行 ) − 起始行号 ) ∗ 4
=
5
+
(
R
O
W
(
A
5
)
−
5
)
∗
4
=5+(ROW(A5)-5)*4
= 5 + ( RO W ( A 5 ) − 5 ) ∗ 4
最后通过index函数就可以根据下标来选择了,但是记住数据区域要锁死行号,就是绝对引用
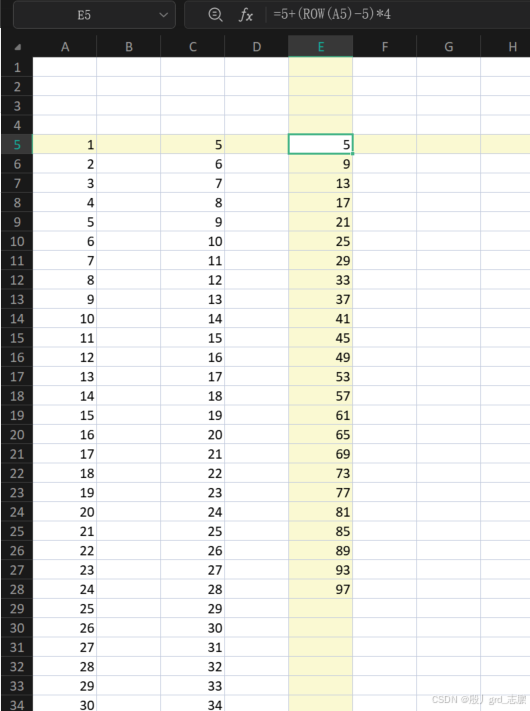
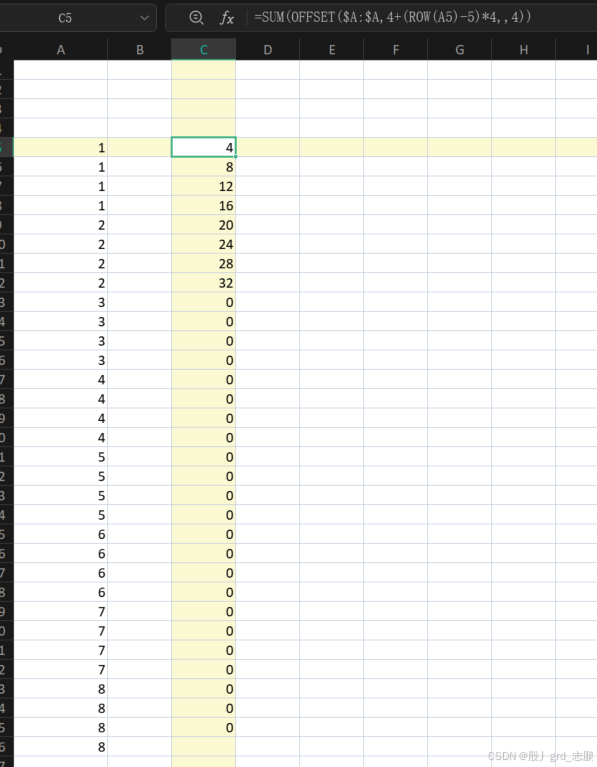
2. 每4行求和
上面知道了如何每4行获取一次下标,那么根据起始下标向下选4行就可以了,通过offset函数
但是要注意,使用offset函数是,公式
起始行号
+
(
R
O
W
(
起始行
)
−
起始行号
)
∗
4
起始行号+(ROW(起始行)-起始行号)*4
起始行号 + ( RO W ( 起始行 ) − 起始行号 ) ∗ 4
(
起始行号
−
1
)
+
(
R
O
W
(
起始行
)
−
起始行号
)
∗
4
(起始行号-1)+(ROW(起始行)-起始行号)*4
( 起始行号 − 1 ) + ( RO W ( 起始行 ) − 起始行号 ) ∗ 4
也就是=
5
+
(
R
O
W
(
A
5
)
−
5
)
∗
4
\textcolor{red}{5}+(ROW(A5)-5)*4
5 + ( RO W ( A 5 ) − 5 ) ∗ 4
=
4
+
(
R
O
W
(
A
5
)
−
5
)
∗
4
=\textcolor{red}4+(ROW(A5)-5)*4
= 4 + ( RO W ( A 5 ) − 5 ) ∗ 4
软件操作技巧 数据透视表 图表 经典图表 柱形图
假设我们有一个KPI指标和实际完成表格,我们要对比每个月份的KPI和实际完成情况。就可以使用对比柱形图
选中数据区域后,插入选项卡——图表菜单——柱形图按钮
选中柱形图中的橙色柱形条(实际完成),右键单击鼠标后,选择设置数据系列格式
将其放在次坐标轴上,两个柱子就重叠了
此时我们发现图表两边的纵轴数值不一样,我们只需要依次双击这两个纵轴,设置坐标轴格式为相同即可
为了区分,我们讲KPI那根蓝色柱子放宽一点,依然是选中蓝色柱子,然后右键,进入设置数据系列格式菜单,然后调整宽度
例如对比每个月各地区销量的情况下,可以用这种。操做方法就是选择数据区域,然后选择堆积柱形图
上图中,我们可以看到柱形图显示的是每个地区各月销量,和我们要求的每个月各地区效率相反,此时只需要点击图表设计选项卡——切换行/列即可
条形图
假设我们的数据有正有负怎么制作合适的条形图呢? 首先我们需要一个辅助列,利用函数Sign,来标识数据的正负。sign函数的作用就是正数返回1,负数返回-1,0返回0
为了方便显示,因为增长率是百分比,所以我们给辅助列乘0.5。然后添加负号,负号的作用是让生成的图表符合我们的预期。然后我们为整个数据包括辅助列生成堆积条形图
我们发现纵轴是倒着排的,如果我们想让公司1排在上面就点击坐标轴,然后右键进入设置坐标轴格式菜单,然后勾选逆序类别
辅助列和纵坐标轴我一般是不让其显示的。我会选择在这一步删掉纵坐标轴,然后将辅助列条形图变为透明
我们选择所有增长率条,设置其数据系列格式,然后选择以互补色代表负值,为其设置颜色
展示数据标签,点击图表,右边会有一个加号,点击加号后勾选数据标签
选中辅助列的所有数据标签,右键单击,设置其格式。首先勾选类别名称,取消勾选值。然后上面三个标签的位置设置为数据标签内,下面两个设置为轴内侧
折线图
折线图很简单,但是坐标轴很容易乱
调整坐标轴格式,我们可以先将单位设置为年
然后将数字的格式代码设置为yyyy表示只显示年
面积图 1. 简化年份,例如2010-2011变成2010-11
设置辅助列,通过right函数,提取年份后两位
创建面积图
选中图表后,点击图表设计选项卡——选择数据按钮,在水平分类轴选择编辑,然后选择我们辅助列。此时横坐标就简化了
选中图表,点击图表设计选项卡——选择数据按钮。在图列项窗口选择添加,
系列值去引用数据,也就是GDP那一列
选择刚刚添加的橙色区域,点击更改图表类型,选中折线图
选中图表,在插入选项卡中选择插入文本框,然后通过公式引用最高点的值
组合图
有时候我们直接使用图表,会因为数据之间跨度不一致而导致有些数据体现不出来。例如下图中同比增长率太小,整条曲线几乎看不出变化
选中图表后,我们选择更改图表类型,选择组合图,将同比增长率放在次坐标轴
当然,我们可以直接选中数据,插入组合图
饼图
当有些数据占比很小时,饼图中几乎就看不到了。此时就需要用复合饼图,或者说子母饼图
点击图表,右上角的加号中,添加数据标签
子饼图如何控制哪些放过去呢?只需要进入设置序列格式菜单,这里选择以值为系列分割依据,并将3%以下的都放在子饼图中
我们可以选择饼图分离,将颜色改为统一一点的,字体颜色需要选中数据标签,去开始选项卡修改
动态图表 基础和offset函数 offset ( reference, rows , cols, [ height] , [ width] )



































































 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











