




 本文介绍了sklearn库中的K-Means聚类算法,重点讲解了n_clusters参数,它是K-Means中必须指定的参数,用于设定要分成的类别数量。通常需要根据数据分布探索合适的n_clusters值。通过创建带标签的数据集并观察,可以发现当n_clusters设为4时,SSE收敛效果最佳,这与数据集的实际情况相吻合。
本文介绍了sklearn库中的K-Means聚类算法,重点讲解了n_clusters参数,它是K-Means中必须指定的参数,用于设定要分成的类别数量。通常需要根据数据分布探索合适的n_clusters值。通过创建带标签的数据集并观察,可以发现当n_clusters设为4时,SSE收敛效果最佳,这与数据集的实际情况相吻合。
K-Means类的格式
sklearn.cluster.KMeans (n_clusters=8, init=’k-means++’, n_init=10, max_iter=300, tol=0.0001, precompute_distances=’auto’, verbose=0, random_state=None, copy_x=True, n_jobs=None, algorithm=’auto’)
重要参数:n_clusters
n_clusters是K-Means中的k,告诉模型要分几类。是K-Means当中唯一必填的参数,默认为8类,但通常聚类结果会是一个小于8的结果。通常,在开始聚类之前,并不知道n_clusters究竟是多少,因此要对它进行探索。
当拿到一个数据集,如果可能的话,希望能够通过绘图先观察一下这个数据集的数据分布,以此来为聚类时输入的n_clusters做一个参考。
首先,创建一个有标签的数据集。
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
#自己创建数据集
X, y = make_blobs(n_samples=500,n_features=2,centers=4,random_state=1)
#看一下点的分布情况
color = ["red","pink","orange","gray"]
for i in range(4):
plt.scatter(X[y==i, 0], X[y==i, 1]
,marker='o' #点的形状
,s=8 #点的⼤大⼩小
,c=color[i]
)
plt.show()
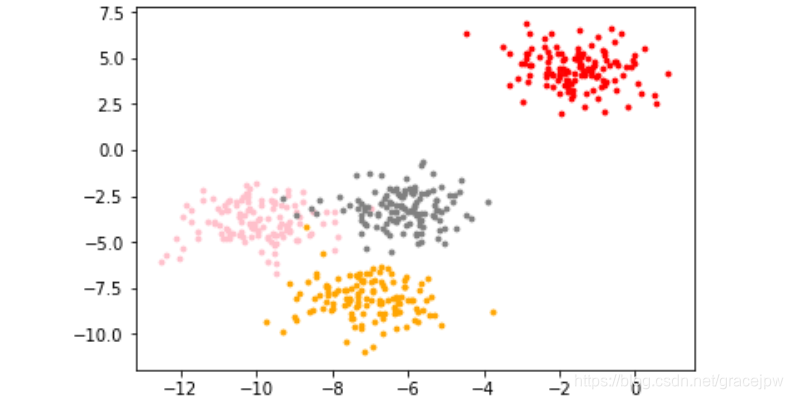
基于这个分布,使用K-Means聚类。首先,猜测一下,这个数据中有几簇?
from sklearn.cluster import KMeans
#先用k=3试试
n_clusters = 3
cluster = KMeans(n_clusters=n_clusters, random_state=0).fit(X)
#重要属性labels_,查看聚好的类别,每个样本所对应的类
y_pred = cluster.labels_
y_pred
array([0, 0, 2, 1, 2, 1, 2, 2, 2, 2, 0, 0, 2 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









