




 本文探讨了决策树在模型选择中面临的欠拟合与过拟合问题,解释了过拟合和欠拟合的概念,并通过图示说明。文章强调了防止过拟合的重要性,介绍了通过交叉验证判断过拟合的方法。最后,详细阐述了决策树剪枝的原理,包括预剪枝和后剪枝策略,以提升决策树的泛化能力。
本文探讨了决策树在模型选择中面临的欠拟合与过拟合问题,解释了过拟合和欠拟合的概念,并通过图示说明。文章强调了防止过拟合的重要性,介绍了通过交叉验证判断过拟合的方法。最后,详细阐述了决策树剪枝的原理,包括预剪枝和后剪枝策略,以提升决策树的泛化能力。
欠拟合与过拟合
当假设空间中含有不同复杂度的模型时,就要面临模型选择(model selection)的问题。我们希望获得的是在新样本上能表现得很好的学习器。为了达到这个目的,我们应该从训练样本中尽可能学到适用于所有潜在样本的"普遍规律",我们认为假设空间存在这种"真"模型,那么所选择的模型应该逼近真模型的。
拟合度可简单理解为模型对于数据集背后客观规律的掌握程度,模型对于给定数据集如果拟合度较差,则对规律的捕捉不完全,用作分类和预测时可能准确率不高,换句话说,当模型把训练样本学得"太好"了的时候,很可能已经把训练样本自身的一些特点当作了所有潜在样本的普遍性质,这时候所选的模型的复杂度往往会比真模型更高,这样就会导致泛化性能下降。这种现象称为过拟合(overfitting)。可以说,模型选择旨在避免过拟合并提高模型的预测能力。
与过拟合相对的是欠拟合(underfitting),是指模型学习能力低下,导致对训练样本的一般性质尚未学好。
图中虚线表示不可约误差,对应所有方法的最低测试均方误差;
无论什么样的数据和方法,自由度上升,训练均方误差将降低;


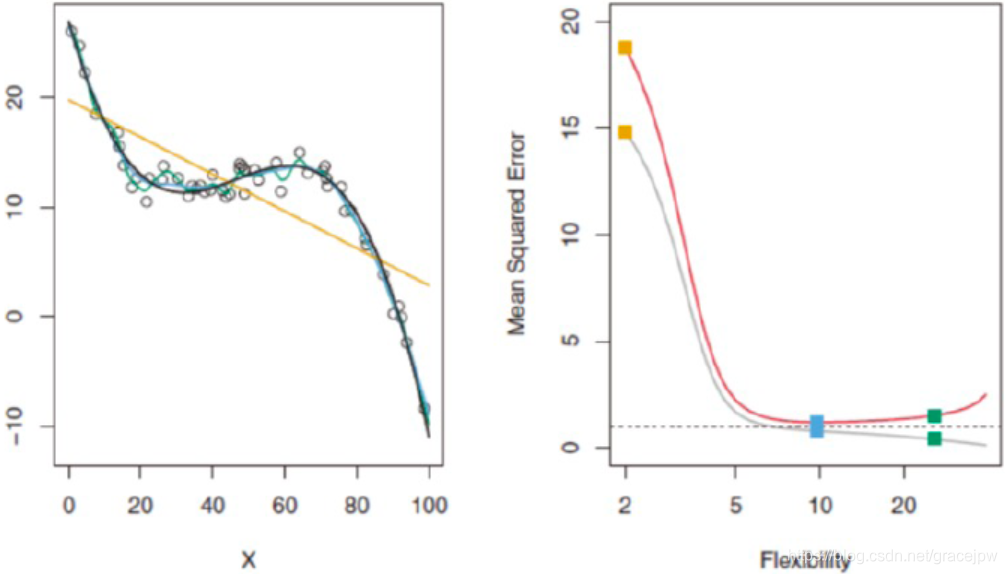
从图中我们可以看出,对于复杂数据,低阶多项式往往是欠拟合的状态,而高阶多项式则过分捕捉噪声数据的分布规律。
而噪声之所以被称作噪声,是因为其分布本身毫无规律可言,或者其分布规律律毫无价值,因此,就算高阶多项式在当前训练数据集上拟合度很高,但其捕捉到的无用规律无法推广到新的数据集上。因
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2696
2696

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









