




 Facebook骨干网络故障源于误操作测试命令,导致DNS通告失效和全球服务中断。文章深入分析测试不当、隔离不足和网络设计缺陷,强调生产环境测试严谨性和网络冗余的重要性。
Facebook骨干网络故障源于误操作测试命令,导致DNS通告失效和全球服务中断。文章深入分析测试不当、隔离不足和网络设计缺陷,强调生产环境测试严谨性和网络冗余的重要性。
前言
简单总结一下FB的整个故障成因。FB的骨干网络架构由很多数据中心和一些基础网络设施所构成,它们之间使用BGP作为路由协议通告路由。故障发生当天,工程师执行了一条测试骨干吞吐能力的命令,结果把整个骨干网络设施嗝屁了。本来这只是第一层故障,数据中心和基础设施内部无法通信,对外服务还是正常的。但却导致其中一项网络基础设施:DNS服务器组因无法访问其它数据中心,而把自己的BGP路由通告失效了。由于全球其它权威DNS所在的网络供应商根据BGP路由通告使FB的DNS路由失效。因此外界需要根据FB的域名解释数据中心地址时也无法访问FB的DNS,也就无法访问任何以域名为基础的数据中心。这就是第二层故障。更要命的是,由于FB工程师远程维护骨干网络设备也需要用到本身的基础设施,因此远程维护也失败了。
 https://engineering.fb.com/2021/10/05/networking-traffic/outage-details/
https://engineering.fb.com/2021/10/05/networking-traffic/outage-details/本文部分内容为根据上文自行脑补,不一定与实际情况一致,敬请见谅
正文
上述是FB工程师给出的review。非常有意思的是,这次程序员成功甩锅给了网络工程师,因为这次出问题的,竟然是因为一条日常维护用的测试命令。
our engineers often need to take part of the backbone offline for maintenance
a command was issued with the intention to assess the availability of global backbone capacity, which unintentionally took down all the connections in our backbone network, effectively disconnecting Facebook data centers globally.
根据官方说法,这条命令是为了让部分骨干网络下线,目的是用于测试整个骨干网的承载能力,而他们经常这么做(??)。令人遗憾的是,这条命令意外地导致了整个骨干网连接中断,使得所有数据中心和基础设施之间连接中断。本应该被审计软件阻止的,却又因为审计软件出现了Bug而无法发现此错误。从而产生了不可预估的结果。
对于FB这次的业务下线故障分析,我想从两个方面说起。一个是测试,另一个是网络设计。
首先谈谈测试的问题。对于生产网络而言,测试是必须的,但也是谨慎的。在业务运行中严禁任何有未知影响的测试!这是网络维护最基本的要求。产生影响是未知的,是属于应急演练的范畴,这不单是运维部门独立承担的。因此,每一项测试任务都要求测试人员对测试对象、测试条件、测试流程和测试结果有绝对充分的认识。
对于测试对象,要做到把测试对象与网络中其它不相关环境作隔离。一方面可以确保测试结果的准确性,另一方面可控制测试影响范围。这一次FB对骨干网络承载能力的测试,测试的对象应该是骨干网络设备之间的流量,但测试中并没有排除骨干中DNS服务器通告路由的因素,从而导致了整个业务的崩溃。可见FB对测试对象与非测试对象之间并没有做到完全的隔离。
对于测试条件,必须根据测试对象严格设置。如果测试对象只是某一段骨干的承载能力,测试条件所产生的荷载不应大于该段网络理论承载的最大值,过载影响不应该延申至骨干其它地方;如果对象是整个骨干的承载能力,则测试条件要足够覆盖整个骨干,但不延伸到非骨干网络,例如数据中心和基础设施内部。这一次FB的测试条件是使部分链路下线,但运行结果使整个骨干链路下线,显然测试条件是有明显问题的。
对于测试流程,就是要充分考虑测试前、测试中、测试后,业务流量被干扰的各种情况和对策,例如链路失效这种类型的测试,应该有:
- 测试前给业务流量准备合适的备用链路;
- 测试中要有相应的手段保证业务正常;
- 测试后没有制定严格的撤销流程,确保全网恢复成测试前状态。
这一次FB的测试明显没有做好测试流程的准备,测试前没有备用骨干,测试中业务下线也没有恢复手段,测试后也无法撤销测试命令带来的影响。
对于测试结果,测试的结果应该是可以产生改善生产环境的结论的,这里就不细说了。至少这一次,FB应该对严重故障的整体的应急预案做深刻检讨了。包括故障应该如何定位,工程师要怎么抵达现场,抵达后怎么操作设备,业务上怎么应对,这些都是实实在在可以总结的。
最后还应该有相应的审计行为,当然由于FB认为本次故障中自动审计出现了Bug,导致不能及时阻止测试所产生的影响,这也算是应急预案的失效,只能从应急预案的制定和实施等方面作检讨了。
接着谈网络设计层面的问题。
FB这次故障,根据官方说法涉及到网络参考模型两个层面的问题,第一个是网络层的路由问题,第二个是应用层的DNS域名解释问题。
首先介绍一下正常情况下,这两个层面的运行情况。
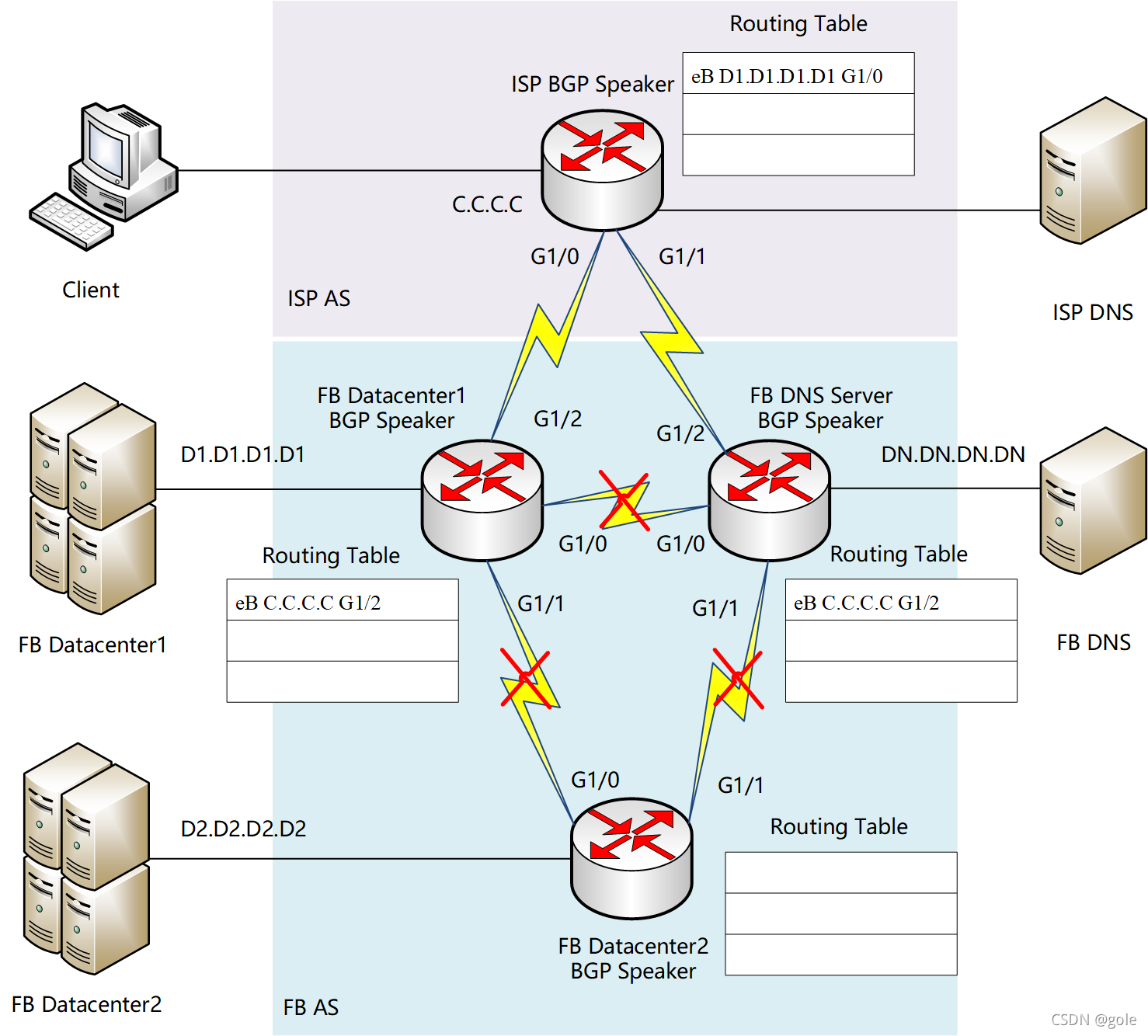
在网络层面上,ISP的Client要访问FB的DataCenter,必须知道对方的IP地址。在INTERNET中,ISP、FB各自管理自己的网络区域,称为自治区域(AS)。各自AS内交换路由信息使用内部网关协议(IGP),例如RIP,OSPF等;AS之间交换路由信息使用外部网关协议(EGP),目前最为广泛的就是BGP路由协议。正常情况下,ISP所在的边界路由器(称为BGP Speaker)与 FB DC所在AS的BGP Speaker建立eBGP邻接关系。FB因为多个DC都与外部建立eBGP邻接关系,为了使BGP可以管理这些路由信息,所以DC之间、DC与基础设施之间建立AS内的BGP邻接关系,即iBGP邻接关系。
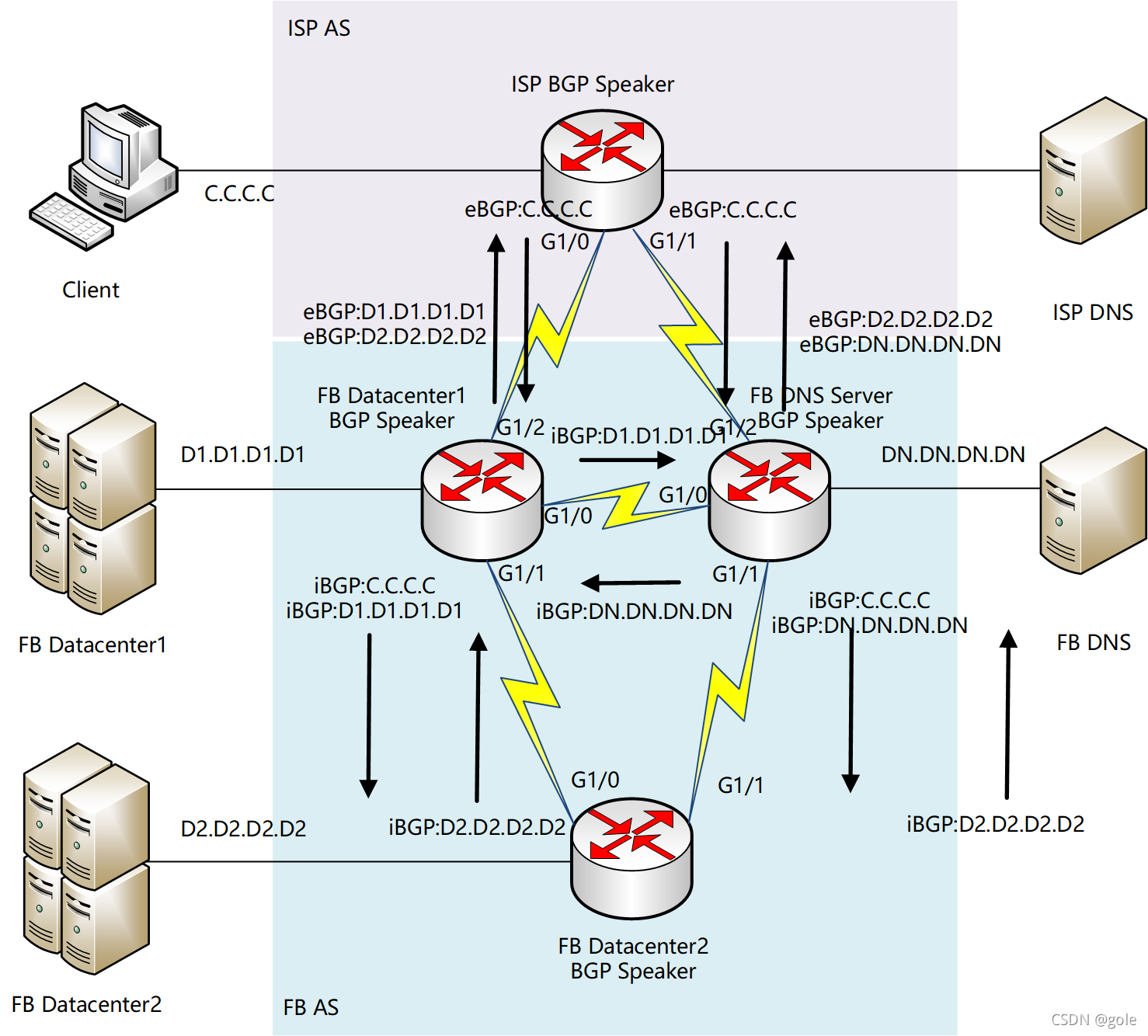
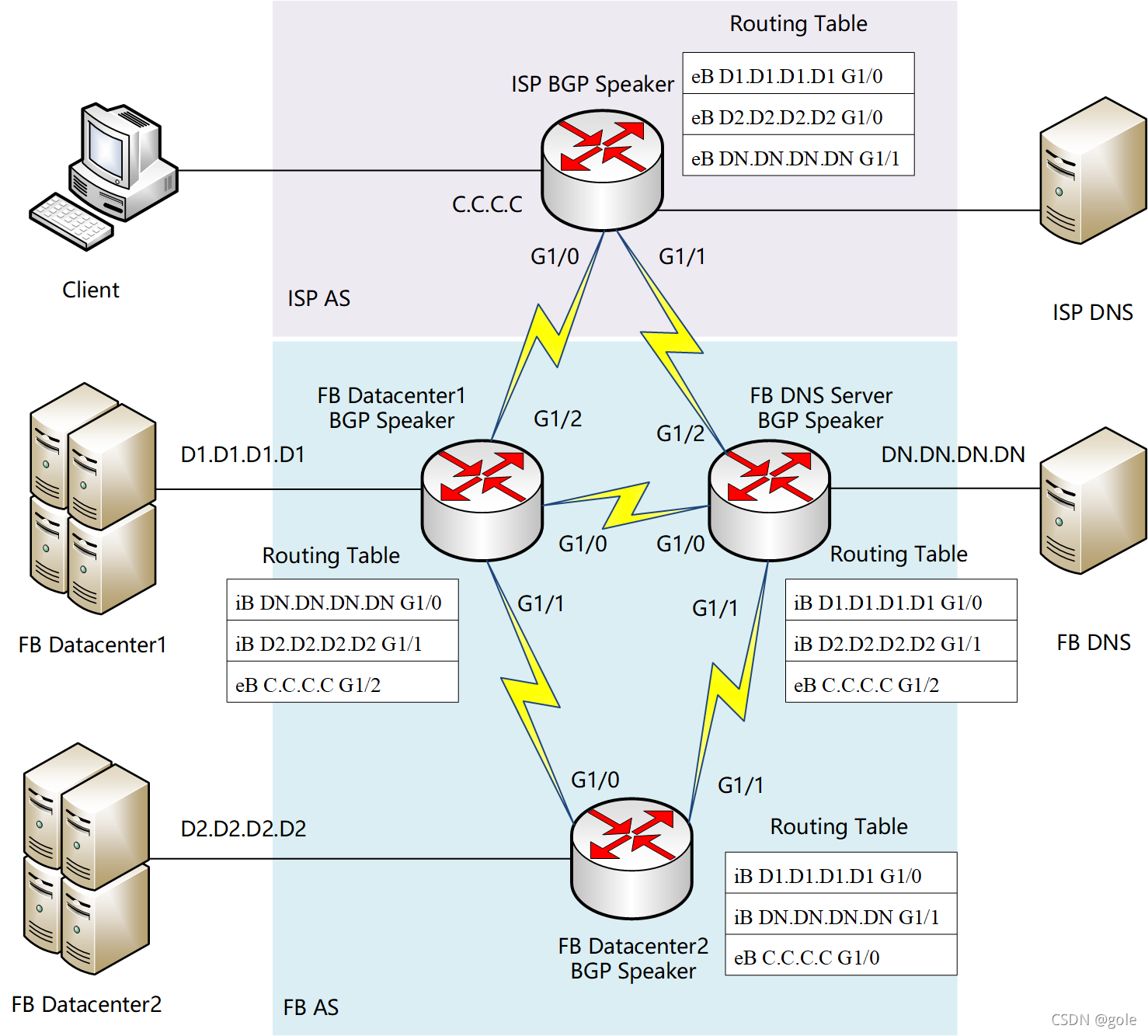
FB内部的DC1、DC2、DNS的BGP Speaker通过iBGP交换各自路由,再由DC1的BGP Speaker和ISP的BGP Speaker相互交换路由。最终各BGP Speaker里,通过eBGP学习到的使用eB标记,通过iBGP学习到的使用iB标记。在全网路由稳定的时候,各路由器BGP信息收敛,形成下图状态:
 接着是应用层面,假设一个全新的客户端Client要访问FB应用服务(假设是www.fb.com)。Client通过浏览器产生www.fb.com的https数据。这些数据在封装至TCP/IP协议栈的网络层停止下来,因为没有目的地IP地址。因此Client的网络处理暂时处于等待状态,并由OS首先向客户DNS发出正向查询:“www.fb.com的IP地址是什么?”这里的客户DNS一般由ISP提供。一般情况下,ISP DNS也不知道www.fb.com对应的IP地址是什么。这时它们有两种处理方式,如果它们配置有权威DNS,就会把正向查询转发给权威DNS继续查询;如果不知道www.fb.com的地址,但是知道fb.com权威DNS的IP地址(这是FB向域名服务商注册的,假设为DN.DN.DN.DN),就会把查询转发至DN.DN.DN.DN。注意,这里需要ISP路由器的路由表里包含有FB DNS的路由条目DN.DN.DN.DN。
接着是应用层面,假设一个全新的客户端Client要访问FB应用服务(假设是www.fb.com)。Client通过浏览器产生www.fb.com的https数据。这些数据在封装至TCP/IP协议栈的网络层停止下来,因为没有目的地IP地址。因此Client的网络处理暂时处于等待状态,并由OS首先向客户DNS发出正向查询:“www.fb.com的IP地址是什么?”这里的客户DNS一般由ISP提供。一般情况下,ISP DNS也不知道www.fb.com对应的IP地址是什么。这时它们有两种处理方式,如果它们配置有权威DNS,就会把正向查询转发给权威DNS继续查询;如果不知道www.fb.com的地址,但是知道fb.com权威DNS的IP地址(这是FB向域名服务商注册的,假设为DN.DN.DN.DN),就会把查询转发至DN.DN.DN.DN。注意,这里需要ISP路由器的路由表里包含有FB DNS的路由条目DN.DN.DN.DN。 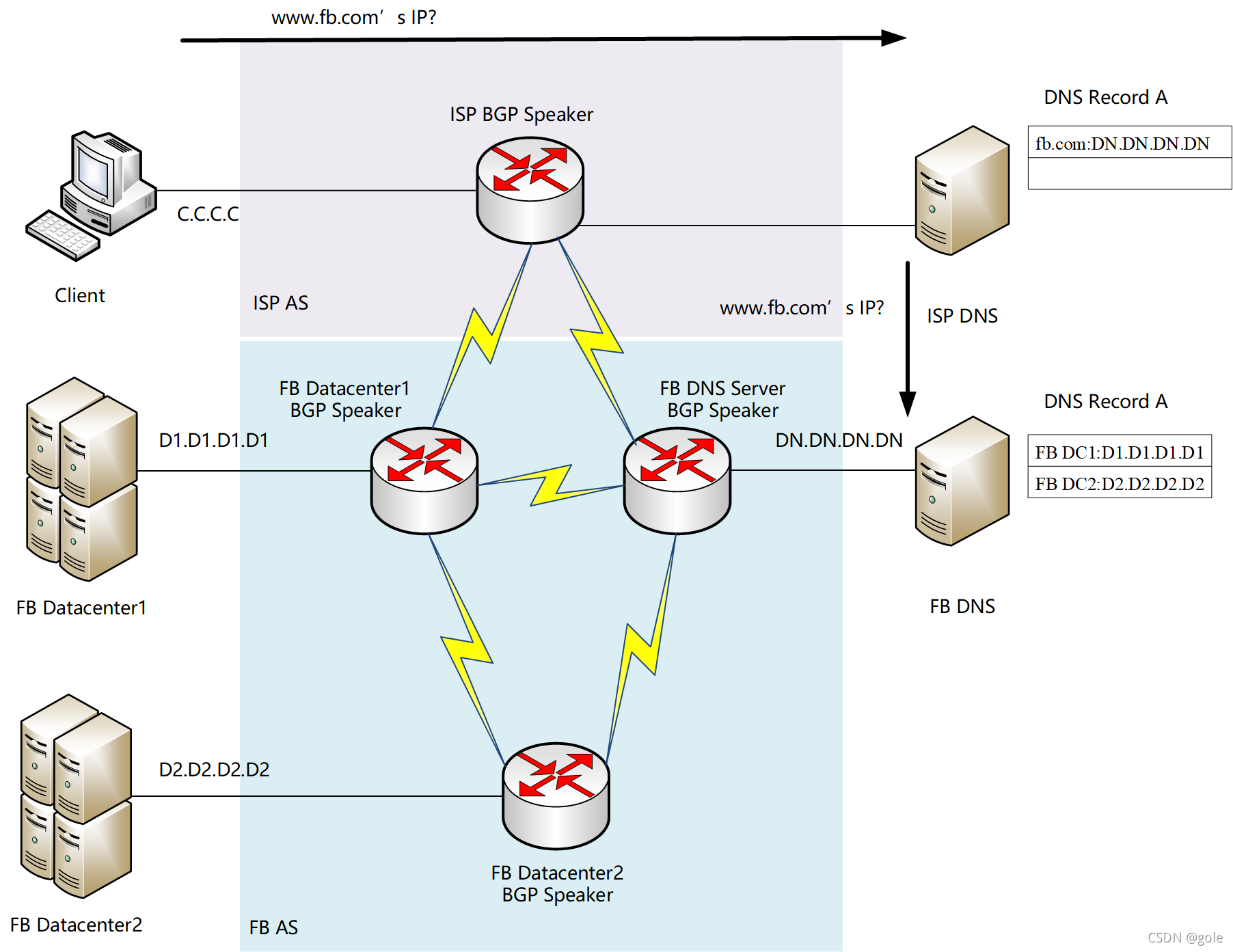
FB的DNS配置有响应策略,分析从哪些源地址产生的DNS正向查询,应返回哪个DC(图里的DC1)的IP地址(D1.D1.D1.D1)。这样子,查询过的DNS会缓存并返回这条DNS记录A(www.fb.com D1.D1.D1.D1),一直应答到Client。这时Client的https数据可以在网络层继续封装,目的地址为D1.D1.D1.D1,并发送至FB DC1。这时候应用就可以正常通信了。
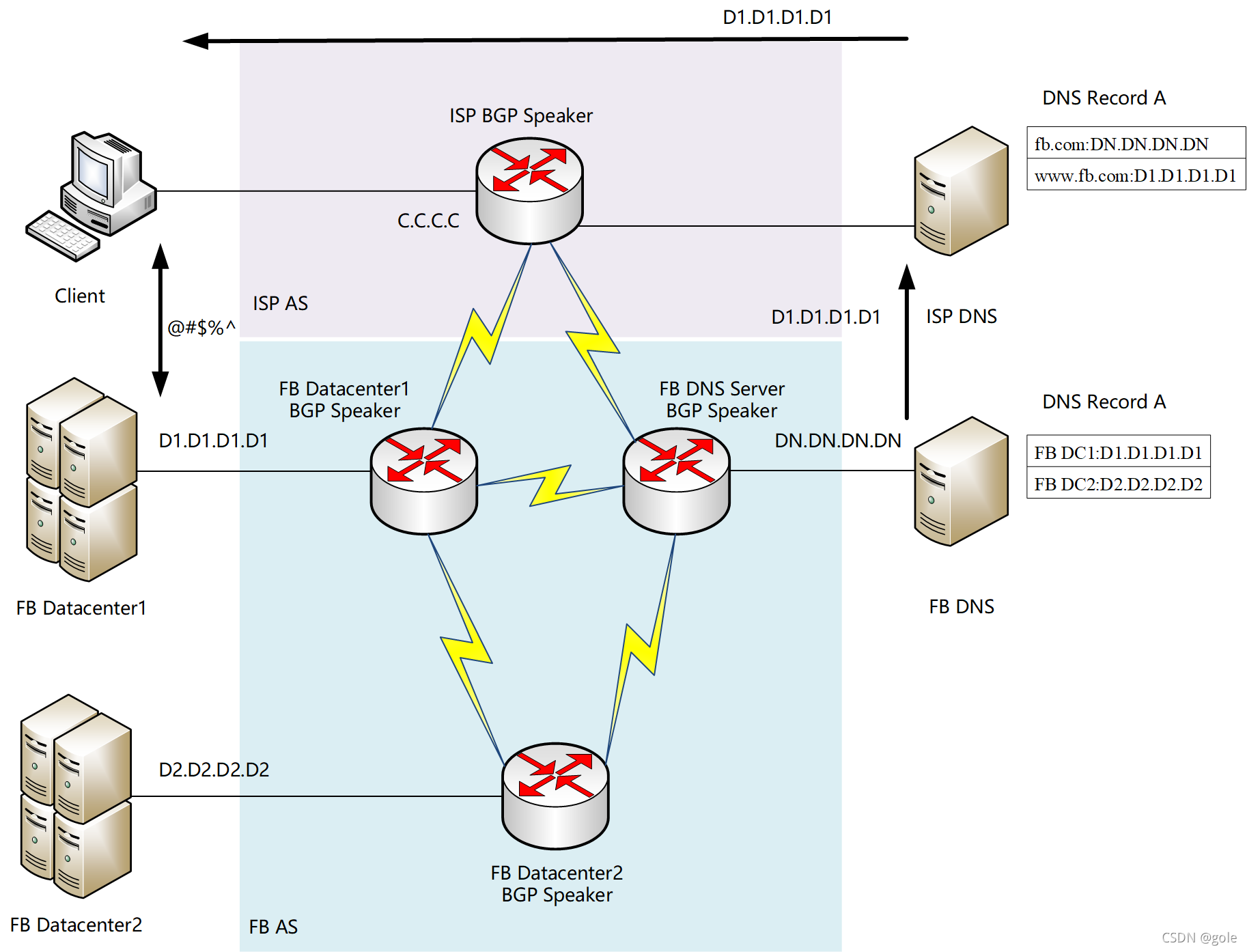
然后看看故障情况下究竟发生了什么
本来相安无事,一条命令导致到整个FB的骨干失效。这是先看看网络层发生了什么: 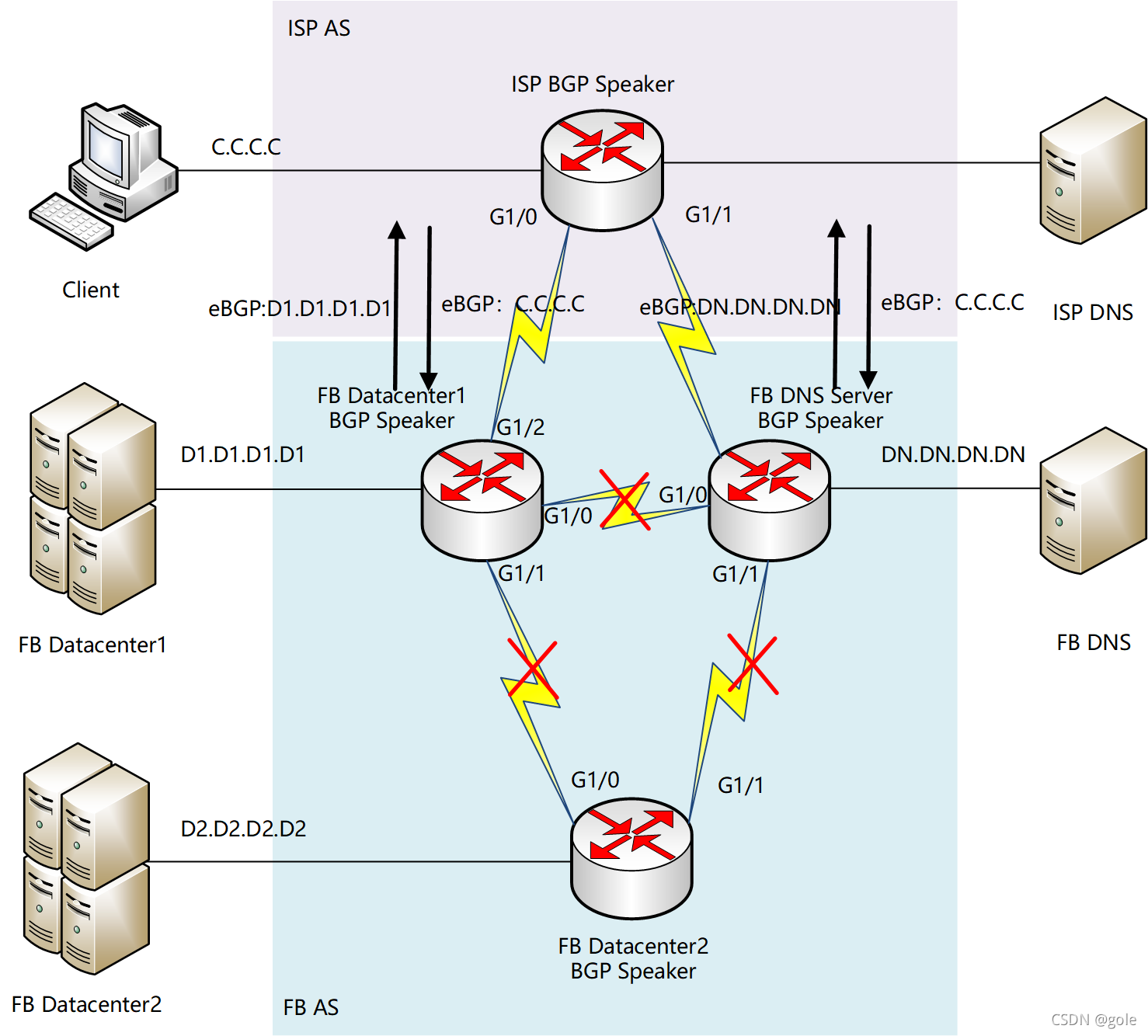
这时,FB内部骨干全部断开,iBGP全部失效。这就是FB所谓的第一层故障。影响面时DC之间无法同步消息,也不能使用基础设施所提供的资源。
但ISP与FB各路由器的eBGP依旧保持连接正常。理论上,如果按照上图的BGP通告,因为ISP的路由器还能收到来自FB DC1和FB DNS的eBGP路由信息,因此它们之间的路由应该是没有问题的。可是FB玩了一手新招......
our DNS servers disable those BGP advertisements if they themselves can not speak to our data centers
FB DNS会从骨干访问各DC,如果发现自己不能访问这些DC,则会把自个从BGP通告里撤销?!所以真实的BGP通告变成了:
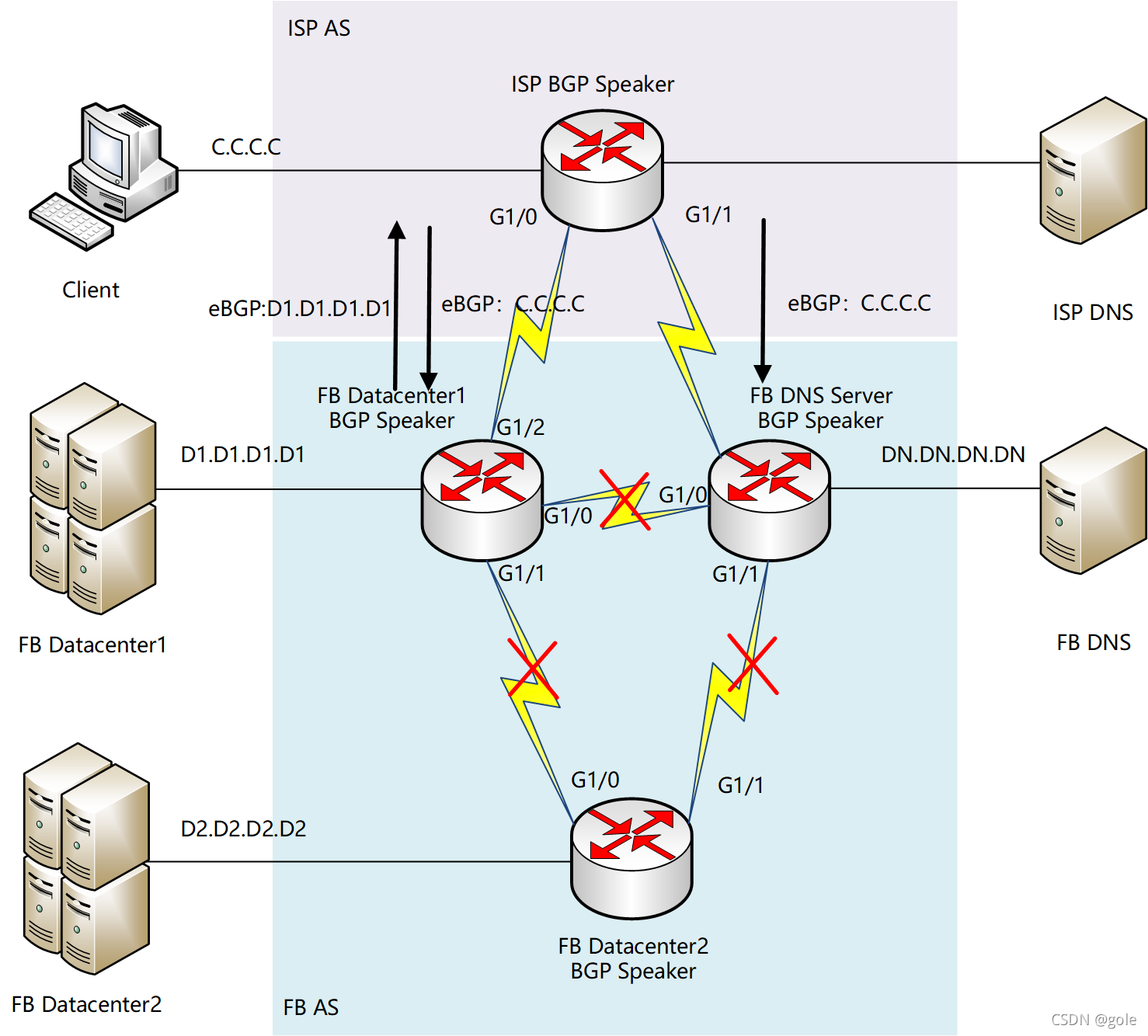
FB DNS不在eBGP内通告自己的路由,因此ISP的路由表里只剩下指向DC1的路由:
这是收敛后的路由信息。可以发现,ISP BGP Speaker明明和FB DNS保持着eBGP毗邻关系,但是死活收不到FB DNS的BGP路由信息。
这时,如果还有客户需要访问www.fb.com,就要看你所在ISP的DNS有没有DC1的正向查询记录缓存了。如果没有,正如那8000w用户一样,ISP的DNS将因为所在AS没有DN.DN.DN.DN的路由,从而导致无法访问fb.com的权威DNS,最终导致无法解释www.fb.com,将与FB的所有服务隔离。
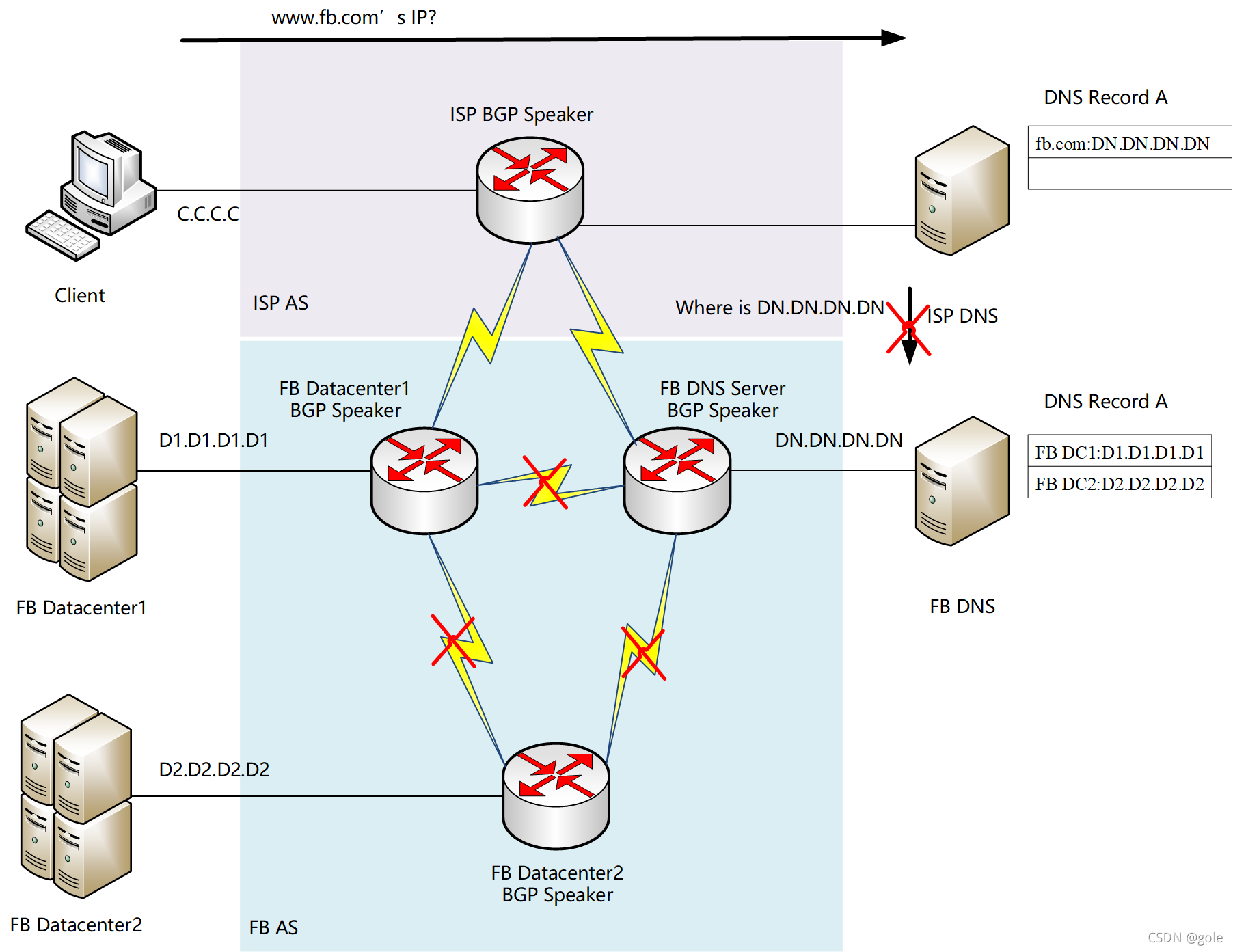
但也有很多用户是幸运的,主要是因为他们的ISP DNS已经缓存好了www.fb.com的正向解释记录:D1.D1.D1.D1,而且ISP的路由器上有包含有D1.D1.D1.D1的路由。
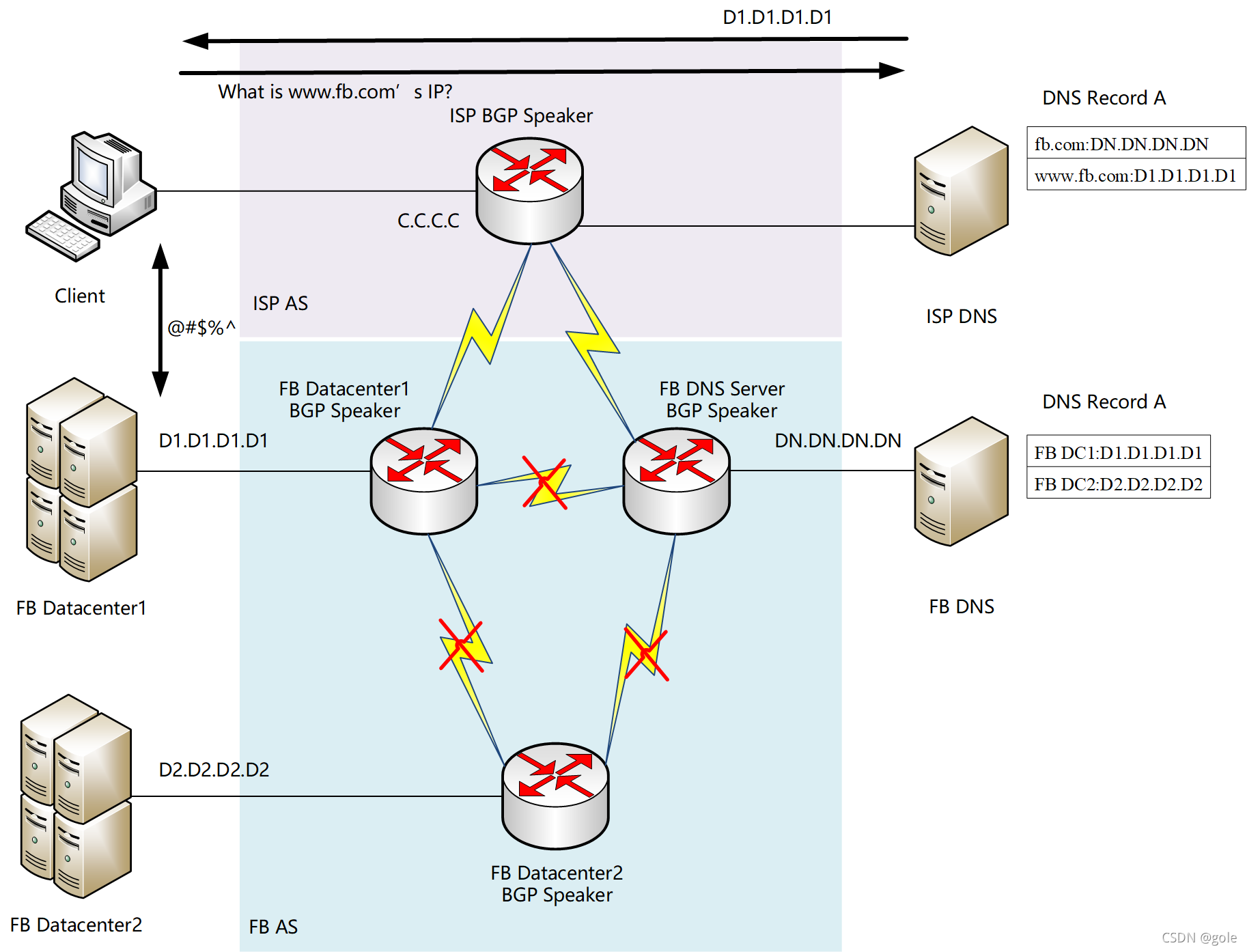 可以看到,这次FB宕机事故最大的问题并不是骨干掉线,而是DNS掉线。骨干掉线的问题只是影响到数据更新和内部计算,但DNS掉线直接让用户无法访问就近数据中心,这就是最大的隐患。
可以看到,这次FB宕机事故最大的问题并不是骨干掉线,而是DNS掉线。骨干掉线的问题只是影响到数据更新和内部计算,但DNS掉线直接让用户无法访问就近数据中心,这就是最大的隐患。
总结
这里我认为主要问题在于,FB的DNS通过骨干网检查自身与DC之间的连接状况,并在骨干中断后错误判定为DNS失效,从而终止了BGP通告。正如这次骨干故障所引发的连锁反应,实际上DNS和DC都能对外正常提供服务。而用户流量可能根本不会经过骨干。可以考虑取消DNS的连通性检查机制,避免因骨干网络故障从而强制造成所有设施设备对外服务的中断。而各DC前置负载均衡器,在本地服务器失效的情况下,通过负载均衡把流量转移到其它DC中。当然如果DC的负载过大,还是需要手工改变DNS中的DC指向。
若有纰漏,敬请指正

















 832
832

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









