



 在调试不使用selenium的爬虫脚本时遇到连接selenium服务的问题,通过调整目录结构和移除__init__.py文件,成功解决了调试过程中的等待问题。
在调试不使用selenium的爬虫脚本时遇到连接selenium服务的问题,通过调整目录结构和移除__init__.py文件,成功解决了调试过程中的等待问题。
调试爬虫时,始终报出以下错误:
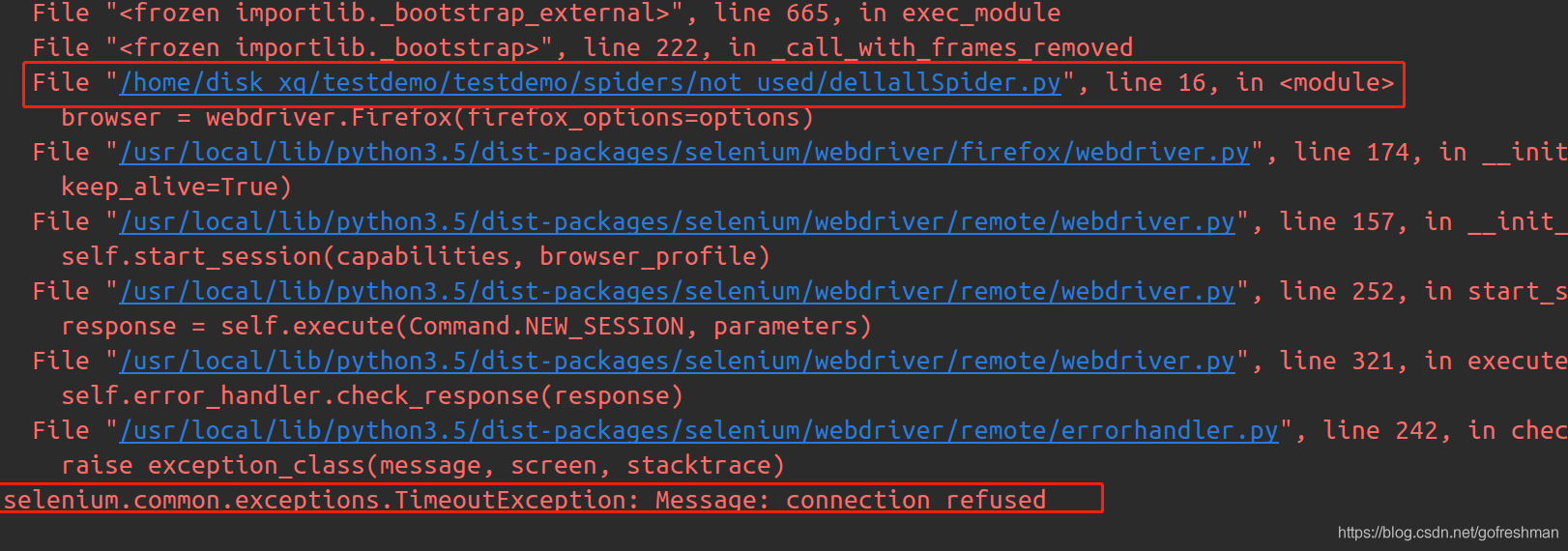
此时使用pycharm调试未应用selenium的爬虫脚本,总报出如上错误或连续三次连接selenium的服务,无法正常进入调试界面。
检查网络并未异常,仔细查看报错的脚本程序,发现该脚本确实使用了selenium来实现自动化爬虫,为了解决此问题,已将该脚本挪出当前工程项目的爬虫路径,但仍未能调试成功,核实检查,发现挪出的新目录含有__init__.py文件导致,该目录仍作为该工程项目的包,因此在调试整个爬虫项目时,仍然会连接selenium服务,导致多次无意义的等待。
遂将新路径下的该文件删除后,爬虫脚本调试无需等待连接,调试正常进入。
以上为个人笔记,其中的深层缘由暂未了解,其中的解决方法来源于网上各位大佬的解答分享和自己的推测和实践得来,若有不对的地方,请大家指教,谢谢

















 1975
1975

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









