




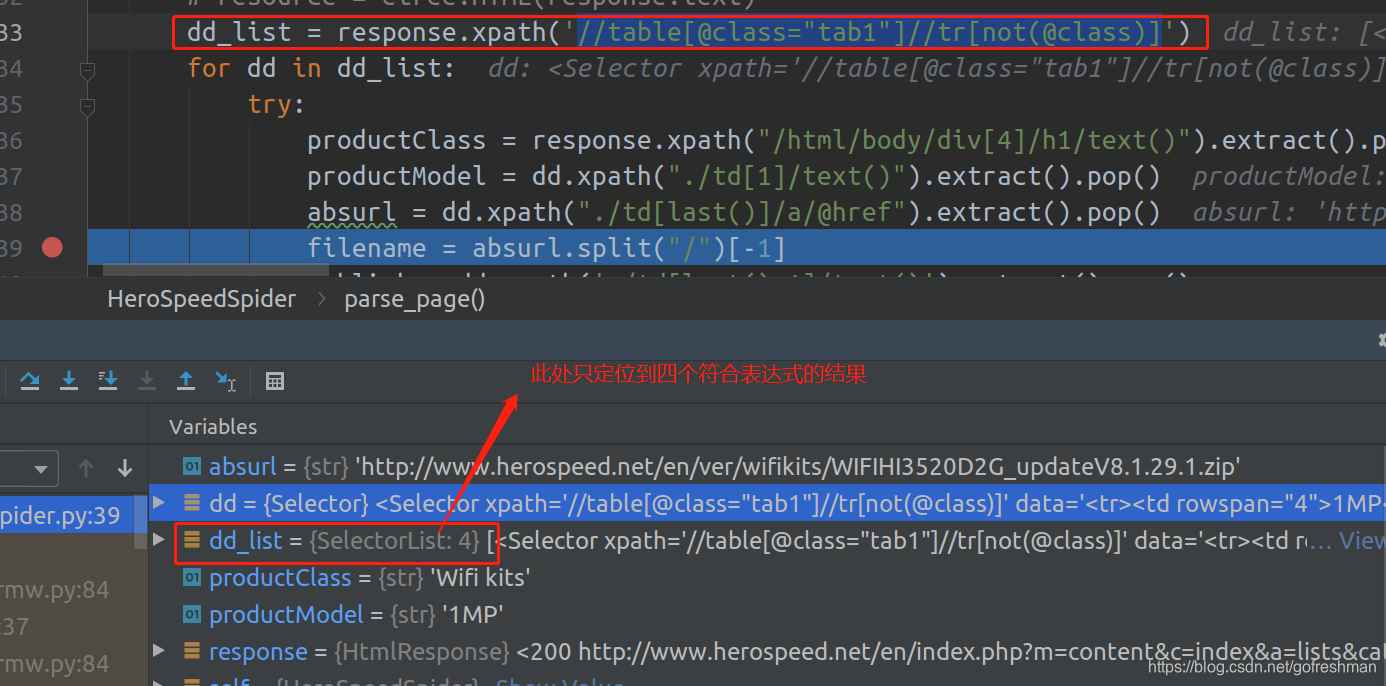
scrapy爬虫调试得到结果如下:
此时,再将response获得源代码另存,用edge打开,显示如下:
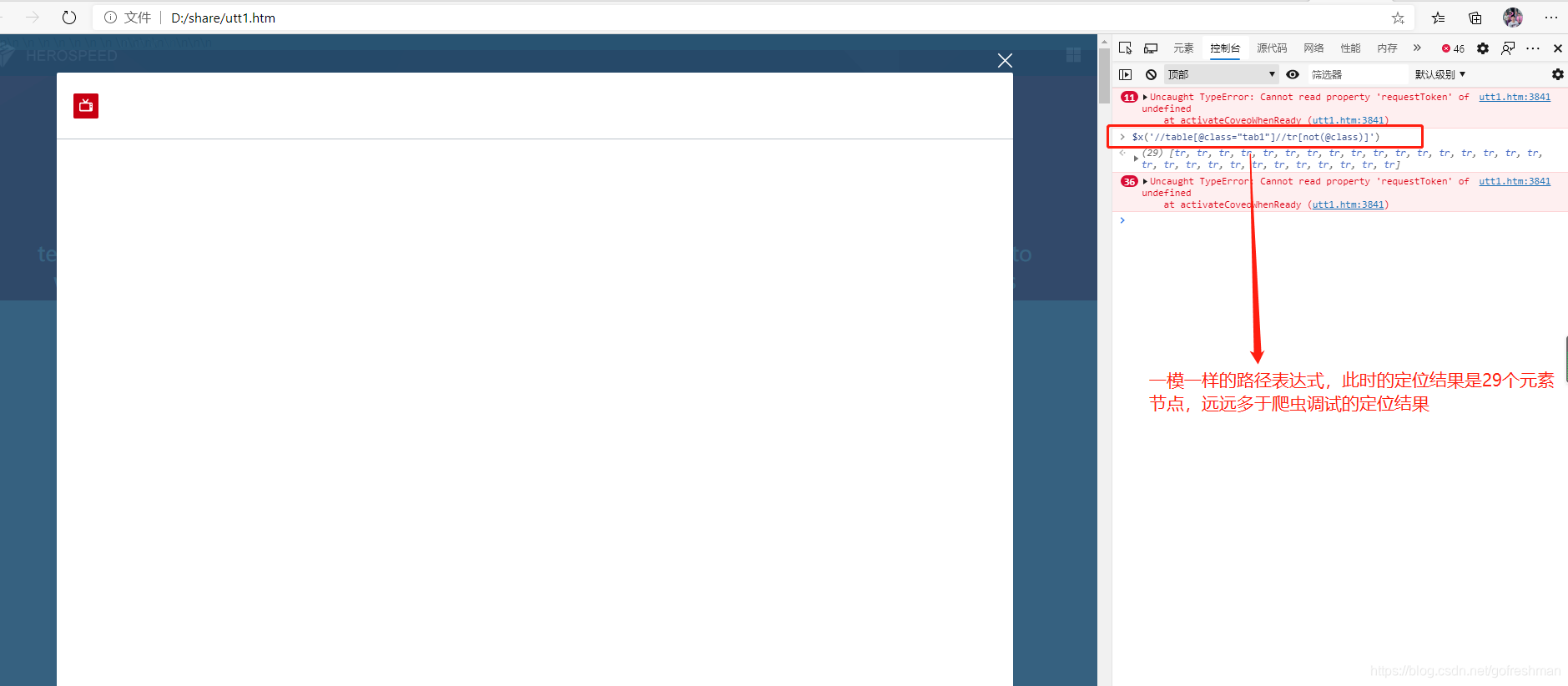
使用控制台验证定位的xpath路径表达式如下:
仔细观察,爬取同一网页的结果,发现只含有网页显示的table元素的子元素tr,且此tr的子元素首个td节点不同的首个符合要求的tr元素节点,现象如下:
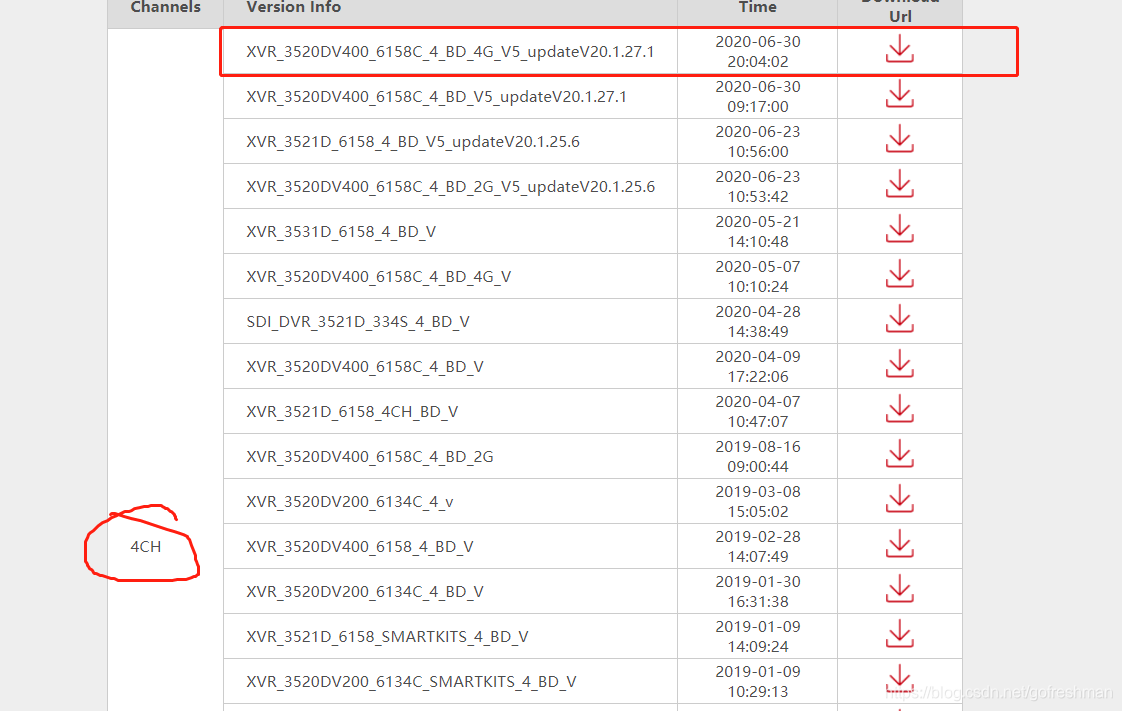
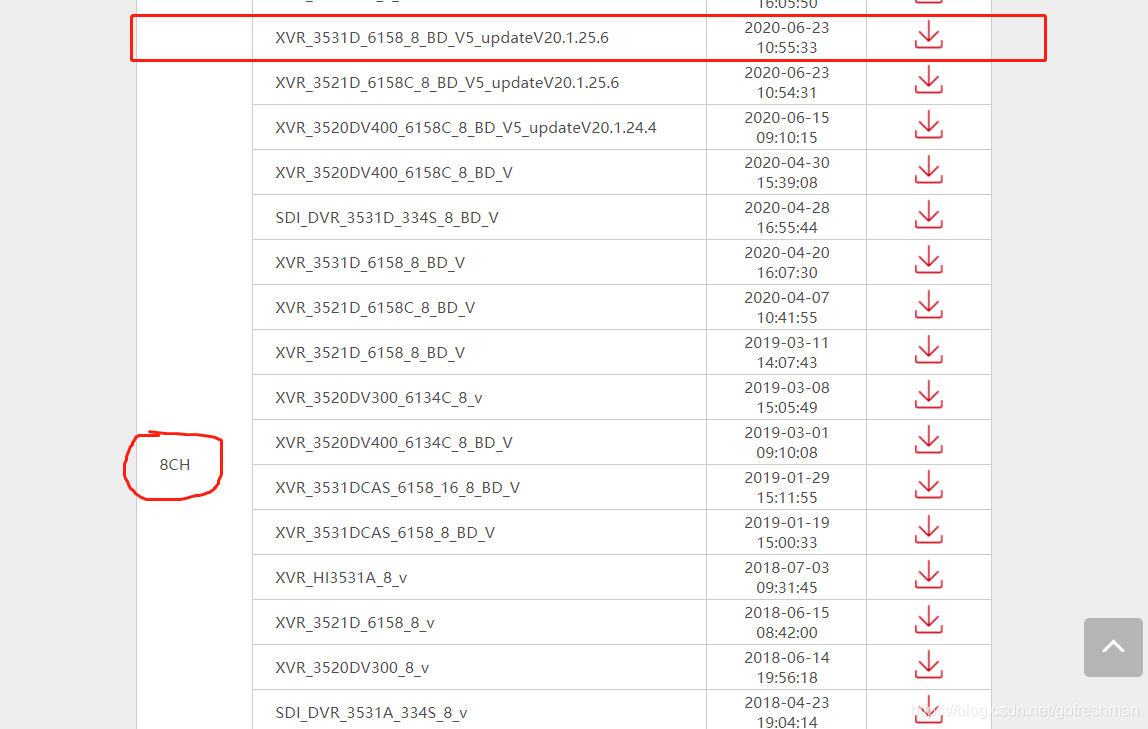
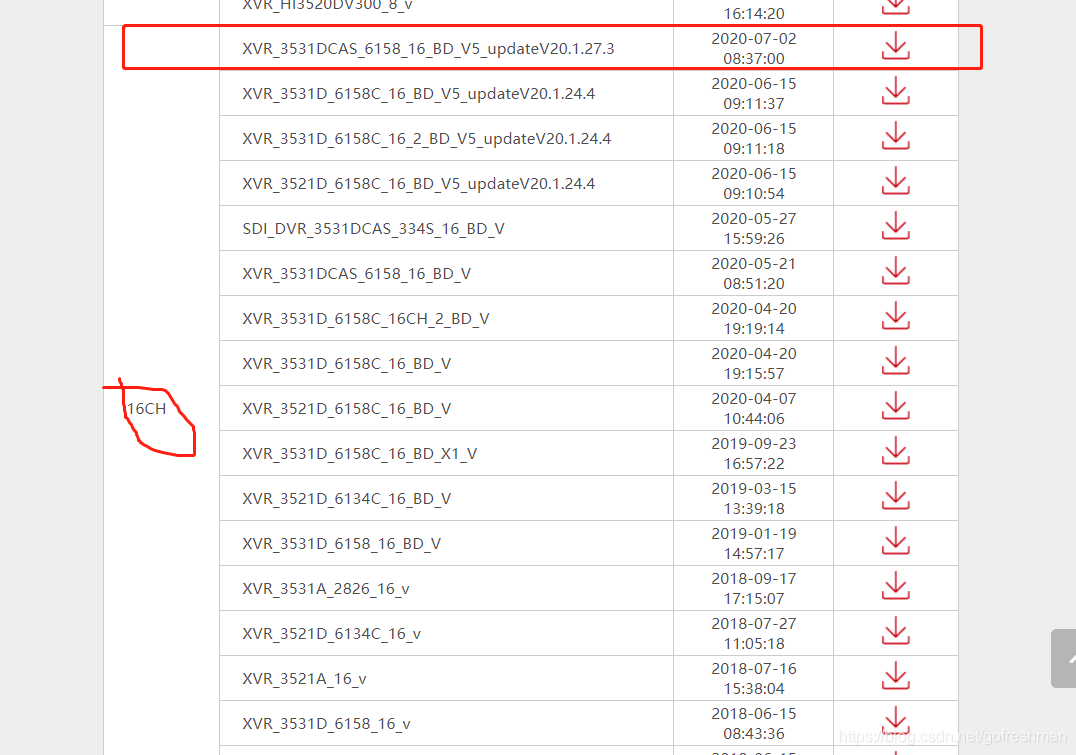
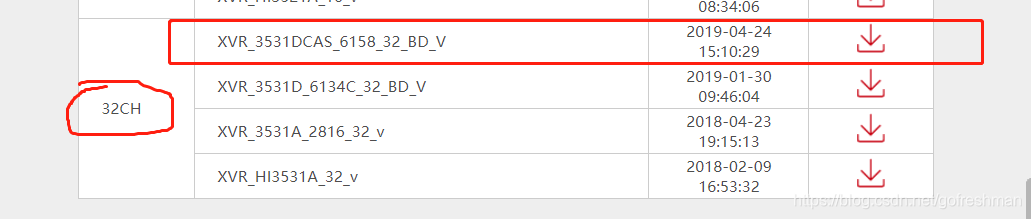
这样四个tr元素节点的内容,被正常爬取,爬取时打印信息如下:
scrapy爬虫获得网页源码另存,再尝试浏览器定位符合预期,但调试脚本中定位远少于前者
最新推荐文章于 2022-11-03 14:11:18 发布
 在使用Scrapy爬虫抓取网页时,发现爬虫获取的源码中只包含了部分表格元素`<tr>`,而浏览器定位到的元素更多。通过另存response源代码并在Edge浏览器中打开,确认了这一差异。尽管XPath表达式正确,但在爬虫中匹配到的`<tr>`元素远少于实际。检查源代码并未发现明显区别,问题原因待解。
在使用Scrapy爬虫抓取网页时,发现爬虫获取的源码中只包含了部分表格元素`<tr>`,而浏览器定位到的元素更多。通过另存response源代码并在Edge浏览器中打开,确认了这一差异。尽管XPath表达式正确,但在爬虫中匹配到的`<tr>`元素远少于实际。检查源代码并未发现明显区别,问题原因待解。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









