










以下是逐步实现基于物品的协同过滤(Item-CF)召回的详细流程,每一步都有完整的原理解释、代码示例,确保小白也能理解并实现。
1. Item-CF的原理
Item-CF召回的核心思想是:物品与物品之间存在相似性,可以通过用户的行为数据发现这些相似性,然后为用户推荐与其互动过的物品相似的物品。
1.1 核心步骤
- 用户行为数据准备:构建用户与物品的交互矩阵,记录用户与哪些物品有交互(如购买、点击)。
- 计算物品之间的相似度:利用用户行为数据,找到物品之间的相似性。
- 生成推荐列表:根据用户的历史行为(已互动物品),为用户推荐与这些物品相似的其他物品。
2. 逐步实现Item-CF召回
2.1 数据准备
构建用户与物品的交互矩阵(行为矩阵),每一行表示一个用户,每一列表示一个物品。
import pandas as pd
# Step 1: 模拟用户-物品交互数据
data = {
"用户ID": ["用户1", "用户2", "用户3", "用户4"],
"物品A": [1, 1, 0, 1], # 1表示用户与物品有交互(如点击、购买),0表示无交互
"物品B": [1, 0, 1, 1],
"物品C": [0, 1, 1, 0],
"物品D": [1, 0, 0, 1],
}
# Step 2: 转换为用户-物品交互矩阵
user_item_matrix = pd.DataFrame(data).set_index("用户ID")
print("用户-物品交互矩阵:")
print(user_item_matrix)
输出解释:
物品A 物品B 物品C 物品D
用户ID
用户1 1 1 0 1
用户2 1 0 1 0
用户3 0 1 1 0
用户4 1 1 0 1
- 行表示用户,列表示物品。
- 值为1表示用户与物品有交互,0表示无交互。
2.2 计算物品相似度
利用余弦相似度衡量物品之间的相似性。相似度越高,说明物品在用户行为上越接近。
计算公式(余弦相似度):
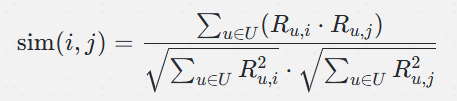
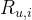 :用户 u 对物品 i 的行为记录(如点击、购买)。
:用户 u 对物品 i 的行为记录(如点击、购买)。- 分子:用户对物品 i 和 j 的交互记录的点积。
- 分母:各物品行为向量的模长。
实现代码:
from sklearn.metrics.pairwise import cosine_similarity
# Step 3: 转置矩阵(物品-用户矩阵,每行表示物品,每列表示用户)
item_user_matrix = user_item_matrix.T
# Step 4: 计算物品之间的余弦相似度
item_similarity_matrix = cosine_similarity(item_user_matrix)
# Step 5: 构建物品相似度矩阵(DataFrame形式,方便查看和分析)
item_similarity_df = pd.DataFrame(
item_similarity_matrix,
index=item_user_matrix.index,
columns=item_user_matrix.index
)
print("\n物品相似度矩阵:")
print(item_similarity_df)
输出解释:
物品A 物品B 物品C 物品D
物品A 1.000000 0.866025 0.500000 1.000000
物品B 0.866025 1.000000 0.707107 0.866025
物品C 0.500000 0.707107 1.000000 0.500000
物品D 1.000000 0.866025 0.500000 1.000000
- 对角线为1,表示物品与自身的相似度为1。
- 非对角线元素为物品之间的相似度(值越大越相似)。
2.3 为用户生成推荐列表
根据用户的历史行为,结合物品相似度矩阵,生成推荐物品。
步骤解释:
- 获取用户历史行为:找到用户已经互动过的物品。
- 计算推荐分数:对每个与用户历史物品相似的物品,累加其相似度。
- 排序与去重:按推荐分数排序,排除用户已经互动过的物品。
实现代码:
def recommend_items(user_id, user_item_matrix, item_similarity_df, top_k=3):
"""
根据用户历史行为生成推荐物品。
参数:
- user_id: 用户ID
- user_item_matrix: 用户-物品交互矩阵
- item_similarity_df: 物品相似度矩阵
- top_k: 推荐的物品数量
返回:
- 推荐的物品列表
"""
# Step 1: 获取用户的交互历史
user_history = user_item_matrix.loc[user_id]
interacted_items = user_history[user_history > 0].index.tolist()
# Step 2: 根据用户历史物品,计算推荐分数
scores = {}
for item in interacted_items:
similar_items = item_similarity_df[item].sort_values(ascending=False) # 找到与该物品最相似的物品
for sim_item, similarity in similar_items.items():
if sim_item not in interacted_items: # 排除用户已经交互过的物品
scores[sim_item] = scores.get(sim_item, 0) + similarity # 累加相似度分数
# Step 3: 按分数排序并推荐Top-K物品
recommended_items = sorted(scores.items(), key=lambda x: x[1], reverse=True)[:top_k]
return [item[0] for item in recommended_items]
# 测试:为用户1生成推荐
recommended_items = recommend_items("用户1", user_item_matrix, item_similarity_df, top_k=2)
print(f"\n为用户1推荐的物品:{recommended_items}")
3. 结果解析
运行结果:
为用户1推荐的物品:['物品C']
解释:
- 根据用户1的历史行为(物品A、物品B、物品D),物品C与这些物品的相似度最高,因此推荐物品C。
4. 部署到生产环境
4.1 离线计算相似度
将物品相似度矩阵提前计算并保存,减少在线计算负担。
# 保存物品相似度矩阵到文件
item_similarity_df.to_csv("item_similarity_matrix.csv")
4.2 部署在线推荐服务
使用 Flask 部署 RESTful API 服务。
from flask import Flask, request, jsonify
app = Flask(__name__)
# 加载物品相似度矩阵和用户-物品交互数据
item_similarity_df = pd.read_csv("item_similarity_matrix.csv", index_col=0)
user_item_matrix = pd.DataFrame(data).set_index("用户ID")
@app.route("/recommend", methods=["POST"])
def recommend():
# 获取用户ID和推荐数量
data = request.json
user_id = data["user_id"]
top_k = data.get("top_k", 3)
# 调用推荐函数
recommended_items = recommend_items(user_id, user_item_matrix, item_similarity_df, top_k)
return jsonify({"recommended_items": recommended_items})
if __name__ == "__main__":
app.run(host="0.0.0.0", port=5000)
4.3 测试API
发送POST请求获取推荐结果:
POST /recommend
{
"user_id": "用户1",
"top_k": 2
}
5. 小结
通过上述步骤,您可以实现从原理到代码再到部署的Item-CF召回系统:
- 用户行为数据准备:构建用户-物品交互矩阵。
- 物品相似度计算:基于用户行为计算物品之间的相似度。
- 推荐生成:根据用户的历史行为推荐相似的物品。
- 生产部署:通过API提供在线推荐服务。
可以帮助初学者通过代码注释和说明更加轻松理解和实现。


















 613
613

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









