









我们从基本概念、数学原理、算法细节、实现框架等多个维度展开,详细全面地解释 Item-CF召回 和 Item2Vec 技术和在推荐系统中的底层原理与可能的源代码实现。
1. Item-CF 召回:基于物品的协同过滤
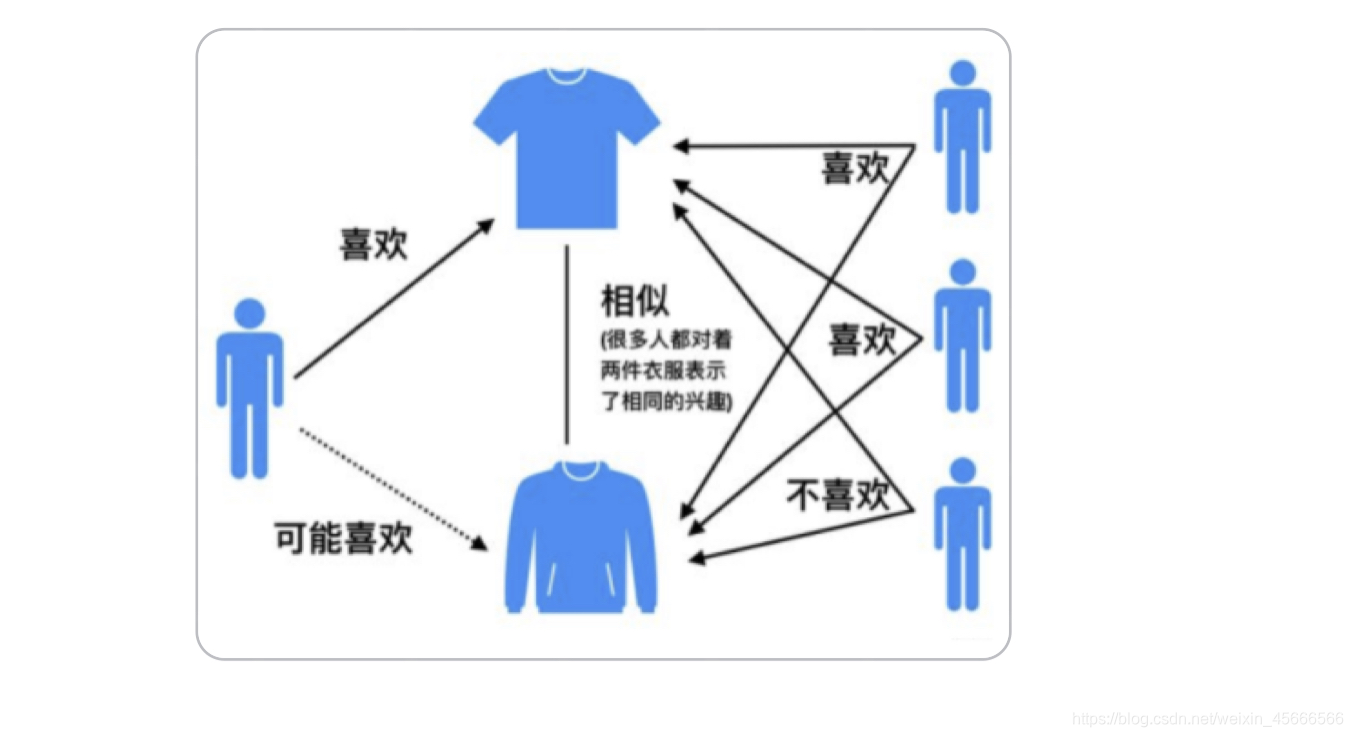
1.1 基本原理
Item-CF(Item-based Collaborative Filtering)是一种协同过滤方法,其核心思想是基于用户的历史行为,寻找与用户感兴趣物品(items)相似的物品,推荐给用户。
-
用户-物品交互矩阵:
构造一个用户-物品交互矩阵,表示用户对物品的交互记录,如评分、点击、购买等行为。示例:
用户 | 物品A | 物品B | 物品C 用户1 | 5 | 4 | 0 用户2 | 3 | 0 | 4 用户3 | 0 | 4 | 5 -
物品相似度:
根据物品的交互记录,计算物品之间的相似度。常用的相似度计算方法包括:- 余弦相似度:
对两个物品 i,j,相似度为:
- 皮尔逊相关系数:
其中表示用户 u 对物品 i 的评分。
- 余弦相似度:
-
推荐计算:
根据用户的历史交互记录,对用户未交互的物品进行评分预测,公式为:
其中
表示用户 u 交互过的物品集合。
1.2 源代码实现
以下是一个简单的基于 Python 和 Numpy 的 Item-CF 实现:
import numpy as np
from collections import defaultdict
# 示例用户-物品交互矩阵
user_item_matrix = np.array([
[5, 4, 0],
[3, 0, 4],
[0, 4, 5]
])
def calculate_item_similarity(matrix):
num_items = matrix.shape[1]
similarity_matrix = np.zeros((num_items, num_items))
# 计算物品间的余弦相似度
for i in range(num_items):
for j in range(num_items):
if i != j:
vec_i = matrix[:, i]
vec_j = matrix[:, j]
norm_i = np.linalg.norm(vec_i)
norm_j = np.linalg.norm(vec_j)
if norm_i > 0 and norm_j > 0:
similarity_matrix[i, j] = np.dot(vec_i, vec_j) / (norm_i * norm_j)
return similarity_matrix
def recommend_items(user_id, user_item_matrix, similarity_matrix, top_k=2):
user_vector = user_item_matrix[user_id]
scores = defaultdict(float)
# 为用户推荐物品
for item_idx, score in enumerate(user_vector):
if score > 0: # 用户已经评分过的物品
for related_item_idx in range(similarity_matrix.shape[0]):
if related_item_idx != item_idx and user_vector[related_item_idx] == 0:
scores[related_item_idx] += similarity_matrix[item_idx, related_item_idx] * score
# 排序,返回 Top-K 推荐
recommended_items = sorted(scores.items(), key=lambda x: x[1], reverse=True)[:top_k]
return recommended_items
# 计算物品相似度
item_similarity = calculate_item_similarity(user_item_matrix)
# 为用户0推荐物品
recommendations = recommend_items(0, user_item_matrix, item_similarity)
print(recommendations)
2. Item2Vec:基于Embedding的物品召回
2.1 基本原理
Item2Vec 是一种基于 Word2Vec 技术思想应用于推荐系统的嵌入式方法,其核心目标是将物品嵌入到低维向量空间中,保留物品之间的语义相似性。
-
Word2Vec回顾:
在 NLP 中,Word2Vec 将单词映射到一个向量空间中,基于上下文窗口训练得到向量。- Skip-Gram 模型:预测上下文词。
- CBOW 模型:预测目标词。
-
Item2Vec 的类比:
将用户的交互序列视为“句子”,物品视为“单词”。通过滑动窗口生成训练数据,学习物品的嵌入表示。示例:
用户行为序列:用户1:商品A -> 商品B -> 商品C 用户2:商品B -> 商品D训练样本:
(商品A, 商品B), (商品B, 商品A), (商品B, 商品C), ... -
训练目标:
学习一个嵌入矩阵() ,使得相似物品在向量空间中的距离较近。
2.2 源代码实现
以下是基于 Gensim 的 Item2Vec 实现:
from gensim.models import Word2Vec
# 用户行为序列
user_behaviors = [
['itemA', 'itemB', 'itemC'],
['itemB', 'itemD'],
['itemA', 'itemC', 'itemE']
]
# 使用 Word2Vec 训练 Item2Vec 模型
model = Word2Vec(sentences=user_behaviors, vector_size=10, window=2, min_count=1, sg=1, workers=4)
# 获取物品的嵌入向量
item_embedding = model.wv['itemA']
print("itemA 的嵌入向量:", item_embedding)
# 找到与 itemA 最相似的物品
similar_items = model.wv.most_similar('itemA', topn=3)
print("与 itemA 最相似的物品:", similar_items)
2.3 结合推荐
通过 Item2Vec 获取物品向量后,可以结合最近邻搜索实现推荐。例如,给用户推荐与其历史行为中物品最相似的物品。
示例:
from sklearn.metrics.pairwise import cosine_similarity
# 获取用户历史行为物品的嵌入
user_history = ['itemA', 'itemB']
user_vector = sum([model.wv[item] for item in user_history]) / len(user_history)
# 计算与所有物品的相似度
item_vectors = [model.wv[item] for item in model.wv.index_to_key]
similarities = cosine_similarity([user_vector], item_vectors).flatten()
# 推荐 Top-K 物品
similar_items = sorted(zip(model.wv.index_to_key, similarities), key=lambda x: x[1], reverse=True)[:3]
print("推荐物品:", similar_items)
3. Item-CF 与 Item2Vec 对比
| 特性 | Item-CF | Item2Vec |
|---|---|---|
| 基本思想 | 基于物品之间的共现或评分相似度 | 基于用户行为序列训练物品嵌入 |
| 优点 | 简单直观,容易实现 | 具有更好的泛化能力,支持非线性关系 |
| 缺点 | 数据稀疏性问题,无法处理冷启动 | 需要大量行为数据,训练成本较高 |
| 适用场景 | 小规模数据或评分数据丰富场景 | 大规模行为数据、需要实时召回场景 |
通过这两种技术,可以有效地完成物品召回任务,结合其他推荐模块(排序、重排)构建完整的推荐系统。


















 751
751

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









