




来了,使用YOLOv11目标检测教程
概述
YOLO11 在 2024 年 9 月 27 日的 YOLO Vision 2024 活动中宣布:https://www.youtube.com/watch?v=rfI5vOo3-_A。
YOLO11 是 Ultralytics YOLO 系列的最新版本,结合了尖端的准确性、速度和效率,用于目标检测、分割、分类、定向边界框和姿态估计。与 YOLOv8 相比,它具有更少的参数和更好的结果,不难预见,YOLO11 在边缘设备上更高效、更快,将频繁出现在计算机视觉领域的最先进技术(SOTA)中。

主要特点
-
**增强的特征提取:**YOLO11 使用改进的主干和颈部架构来增强特征提取,以实现更精确的目标检测和复杂任务的性能。
-
**针对效率和速度优化:**精细的架构设计和优化的训练流程在保持准确性和性能之间最佳平衡的同时,提供更快的处理速度。
-
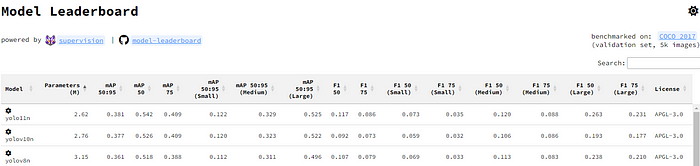
**更少的参数,更高的准确度:**YOLO11m 在 COCO 数据集上实现了比 YOLOv8m 更高的 mAP,参数减少了 22%,提高了计算效率,同时不牺牲准确度。
-
**跨环境的适应性:**YOLO11 可以无缝部署在边缘设备、云平台和配备 NVIDIA GPU 的系统上,确保最大的灵活性。
-
**支持广泛的任务范围:**YOLO11 支持各种计算机视觉任务,如目标检测、实例分割、图像分类、姿态估计和定向目标检测(OBB)。
本教程涵盖的步骤
-
环境设置
-
准备数据集
-
训练模型
-
验证模型
-
在测试图像上运行推理
-
结论
环境设置
你需要一个谷歌账户才能使用 Google Colab。我们使用 Colab 进行需要密集计算的任务,比如深度学习。由于我电脑的 GPU 不足,我需要激活 Colab 的 GPU 支持。
这样做之后,我们检查 gpu 活动。

它支持高达 16GB 的内存和 2560 CUDA 核心,以加速广泛的现代应用程序。然后执行此代码以动态确定工作目录并灵活管理文件路径。
import os
HOME = os.getcwd()
接下来,你需要下载 Ultralytics 包来加载和处理模型,以及用于数据集的 Roboflow 包。
!pip install ultralytics supervision roboflow
from ultralytics import YOLO
from roboflow import Roboflow
准备数据集
在这个项目中,我使用了 RF100 中包含的寄生虫数据集。我将在这个数据集中训练一个有 8 种不同寄生虫类别的目标检测模型。我将通过 Roboflow 处理标记、分类的图像。我经常在我的个人项目中使用这个开源平台。在处理现成的数据集时,你可以在数据集的健康分析部分快速获取大量关于数据的信息。例如,下面显示的类别平衡部分,我们可以看到 Hymenolepis 类别是代表不足的。
数据集相关链接:
https://universe.roboflow.com/roboflow-100/parasites-1s07h
https://universe.roboflow.com/roboflow-100
https://universe.roboflow.com/roboflow-100/parasites-1s07h/health
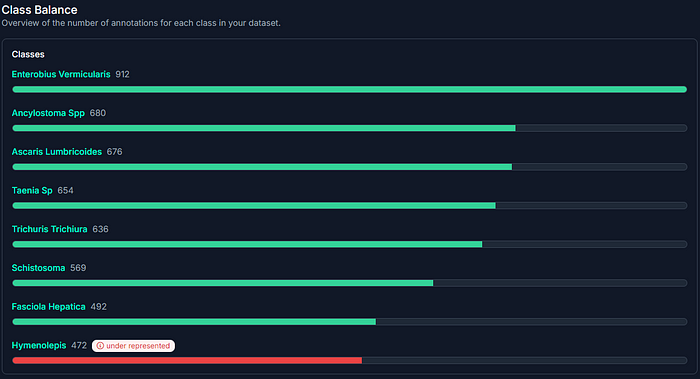
为了提高这个类别的准确性,你需要应用增强、过采样或调整类别权重。我们不会在本文中讨论这些主题,不用担心,但如果你对这些任务感兴趣,请随时联系我。如果有足够需求,我也可以分享我关于这些主题的详细工作。你可以下载并使用 Roboflow 环境中的任何开源项目,按照格式使用。在准备或选择数据集后,我们将在 Colab 环境中工作我们切换到 Colab 的原因是它提供免费的 16GB NVIDIA T4 GPU 使用。我在下面提到了这个问题。我们需要使用 Roboflow API 以 YOLOv8 格式导入我们的数据。让我们获取现成的代码片段和数据格式。
rf = Roboflow 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2965
2965



 到【灌水乐园】发言
到【灌水乐园】发言










