



 本文详细介绍了在Windows环境下,如何使用MapReduce进行词频统计的完整过程,包括Map、Reduce和Driver阶段的实现,以及可能出现的异常及解决方法。读者将学习到如何自定义Mapper和Reducer,以及如何处理和输出数据。
本文详细介绍了在Windows环境下,如何使用MapReduce进行词频统计的完整过程,包括Map、Reduce和Driver阶段的实现,以及可能出现的异常及解决方法。读者将学习到如何自定义Mapper和Reducer,以及如何处理和输出数据。
实验目的:
Windows系统下,通过MapReduce实现次词频统计
MapReduce编程实例-----词频统计
1)·首先,MapReduce通过默认组件TextInputFormat将待处理的数据文件(如ext1.txt和text2.txt),
把每一行的数据都转变为<key,value>键值对;
2)·其次,调用Map()方法,将单词进行切割并进行计数,输出键值对作为Reducer阶段的输入键值对
3)·最后,调用Reduce()方法将单词汇总、排序后,通过TextOutputFormat组件输出结果文件中
Map阶段:
1)自定义Mapper,继承自己的父类;
2)Mapper输入数据是kv键值对形式;形如<a,1> <b,2>
3)Mapper阶段的逻辑代码写入map()方法内;
4)Mapper输出的数据也是kv键值对类型;
5)map()方法,每一个kv都要调用一次;
package word.com;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/*
*Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
*KEYIN:表示mapper阶段数据输入时key的数据类型,读一行数据,返回一行给MR程序
*这种情况下KEYIN表示每一行的起始偏移量,因此数据类型为Long
*VALUEIN: 表示mapper阶段数据输入时Value的数据类型,在默认读取数据组件下,VALUEIN表示读取的一行内容,因此为String
*KEYOUT:表示mapper阶段数据输出时key的数据类型,本案例中输出的Key是单词,因此用String
*VALUEOUT:表示mapper阶段数据输出是Value的数据类型,本案例中输出值Value为单词出现的次数,因此用Integer
*使用Hadoop特殊的序列化类型:long -- LongWritable, String -- Text, Integer -- InWritable
* */
public class WordMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] words = line.split(" ");
for(String word:words){
context.write(new Text(word), new IntWritable(1));
}
}
}
Reduce阶段:
1)自定义Reducer,继承自己的父类;
2)Reducer输入数据是mapper的输出数据类型;形如<a,1> <b,2>
3)Reducer阶段的逻辑代码写入reducer()方法内;
4)reducer()方法,每一个相同的kv都要调用一次;
package word.com;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
/*
* 这里是MR程序reducer阶段处理的类
* KEYIN:这是Reducer阶段数据输入key的数据类型,对应Mapper阶段输出key的类型
* VALUEIN:这是Reducer阶段数据输入value的数据类型,对应Mapper阶段输出value的类型
* KEYOUT:这是Reducer阶段输出key的数据类型,本案例中,是Text
* VALUEOUT:这是Reducer阶段输出value的数据类型,本案例中,是IntWritable
*
* **/
public class WordReduce extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int count = 0;
for(IntWritable value:values){
count += value.get();
}
context.write(key, new IntWritable(count));
}
}
Driver阶段:
通俗讲,相当于连接Mapper和Reducer的桥梁
package word.com;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordDriver {
public static void main(String[] args) throws Exception {
// 1. 获取 job
Configuration conf = new Configuration();
// conf.set("fs.defaultFS", "hdfs://192.168.170.133:9000");
//2.加载jar驱动
Job job = Job.getInstance(conf);
job.setJarByClass(WordDriver.class);
// 3. 关联 mapper 和 reducer
job.setMapperClass(WordMapper.class);
job.setReducerClass(WordReduce.class);
// 4. 设置 map 输出的 k v 类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5. 设置最终输出的k v类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6. 设置输入路径和输出路径
FileInputFormat.addInputPath(job, new Path("F:\\input\\test1.txt"));
FileOutputFormat.setOutputPath(job, new Path("F:\\output"));//output之前是不存在的
// 7. 提交 job
job.submit(); //提交的yarn
boolean b = job.waitForCompletion(true);
System.out.println(b?"成功":"失败");
}
}
实验结果:
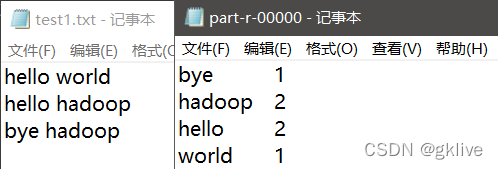
可能出现的问题
Windows系统下运行代码,可能会出现Exception in thread "main" java.lang.NullPointerException
解决方法
将hadoop.dll放到C:\Windows\System32(之前放到hadoop-2.7.2\bin没起作用😓)
将winutils.exe放到hadoop-2.7.2\bin下就可(不要忘记事先配好环境变量)

















 1791
1791




 到【灌水乐园】发言
到【灌水乐园】发言







