




目录
一、光栅化概念
1.背景
光栅化(rasterization)是一种将三维图形转换为二维图像的方法,它是现代计算机图形学中最重要的技术之一。光栅化的核心思想是将三维场景中的所有可见物体都分解为一系列小的二维图形片段,然后将这些片段组合在一起,形成最终的图像。这种方法的优点是它能够生成高质量的图像,并且对于复杂的三维场景也能够得到较好的性能。
2.光栅化描述
2.1为什么要光栅化?
图形管线的输入是图元顶点,输出的则是像素(pixel),这个步骤其中还有个中间产物叫做片段(fragment),一个片段相应一个像素,但片段比像素多了用于计算的属性,比如:深度值和法向量。通过片段能够计算出终于将要生成像素的颜色值,我们把输入顶点计算片段的过程叫作光栅化。为什么要光栅化?由于要生成用以计算最终颜色的片段。
光栅化(Rasterization),又叫栅格化。类比于西方绘画中的一种技法,画家通过一个网格观察景物,把每个网格中人眼能够看到的影像记录在画像上。这里看到的景物是带有透视效果和前后遮挡关系的。
术语栅格化起源于这样一个事实,即多边形(在这种情况下为三角形)在某种程度上被分解为像素,正如我们所知,由像素组成的图像称为光栅图像。此过程在技术上称为将三角形栅格化为图像或帧缓冲区。
“光栅化是确定三角形内哪些像素的过程,仅此而已。”(Michael Abrash 在 Larrabee 上的光栅化)

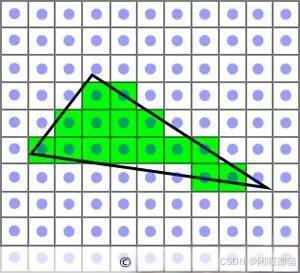
在图形学上,这个网格变得非常细密,即一个格子只包括一个像素。光栅化就像画家一样,确定每个 3D 图元在 2D 画面上占据了哪些像素位置。在这一阶段,同一 2D 位置上可能对应了多个 3D 图元的子区域,每个子区域叫做一个片段。例如下图中,每个格子是一个像素,蓝色圆点是像素的中心。黑色三角形通过像素网格观察,可以看到它占据了绿色那些区域。每个绿色的格子就是这个三角形的一个片段。
一直用OpenGL绘制东西的时候,就会想到我们在写可编程管线的时候,都是使用gl_position去保存一个物体经过model(模型矩阵)矩阵,view(视口)矩阵以及projection(投影)矩阵变换后的位置。然后利用该位置信息在片段着色器中为其上色并显示在屏幕上。这便是我们OpenGL实现光栅化的过程。即,光栅化是将图元转换为二维图像的过程。 该图像的每个点都包含颜色和深度等信息。 因此,对图元进行光栅化由两部分组成。 第一个是确定窗口坐标中整数网格的哪些方格被图元占据。 第二个是为每个这样的方块分配颜色和深度值。 (OpenGL 规范)
经过视口变换后,我们只是得到了与屏幕大小一致的图像,还没有将图像绘制在屏幕上,因此光栅化就是给屏幕像素上色的过程。
通常来说,一幅图像可分割为若干个细小的三角形(一个三角形覆盖屏幕上多个像素),每个三角形有各自的颜色,那么,对屏幕像素进行上色,也就是判断屏幕上某个像素是否在某个三角形内,若在,就给该像素赋上该三角形的颜色。

2.2光栅化的输入和输出
和普通函数一样,光栅化函数也须要输入和输出,从之前的定义来看函数的输入就是组成图元的顶点结构,输出的就是片段结构,为什么说是结构?由于这些能够用c语言中的struct描写叙述。
2.3光栅化发生在哪一步
通常在图形接口中会暴露顶点处理程序和片段处理程序(感觉着色器听起来也是云里雾里就换成处理程序),可是这其中gpu会进行光栅化插值计算,这也就是为什么片段处理程序的input是顶点处理程序的output经过了插值以后得到的值。既然光栅化是在顶点处理程序以后发生的步骤,那么输入的顶点结构是经过顶点处理以后的,也就是进行过mvp变换乘以透视矩阵之后的顶点,注意:这步还没有做透视除法,光栅化插值发生在裁剪空间,绝不是标准化空间,所以顶点位置是四维齐次坐标不是三维坐标!
3.三角形光栅化
首先,为什么要以三角形的光栅化为例呢,因为三角形是最基本的多边形,大部分的模型都是用一个个三角形表示,任意的其它多边形其实都可以转化成多个三角形的形式,因此以三角形的光栅化为例。
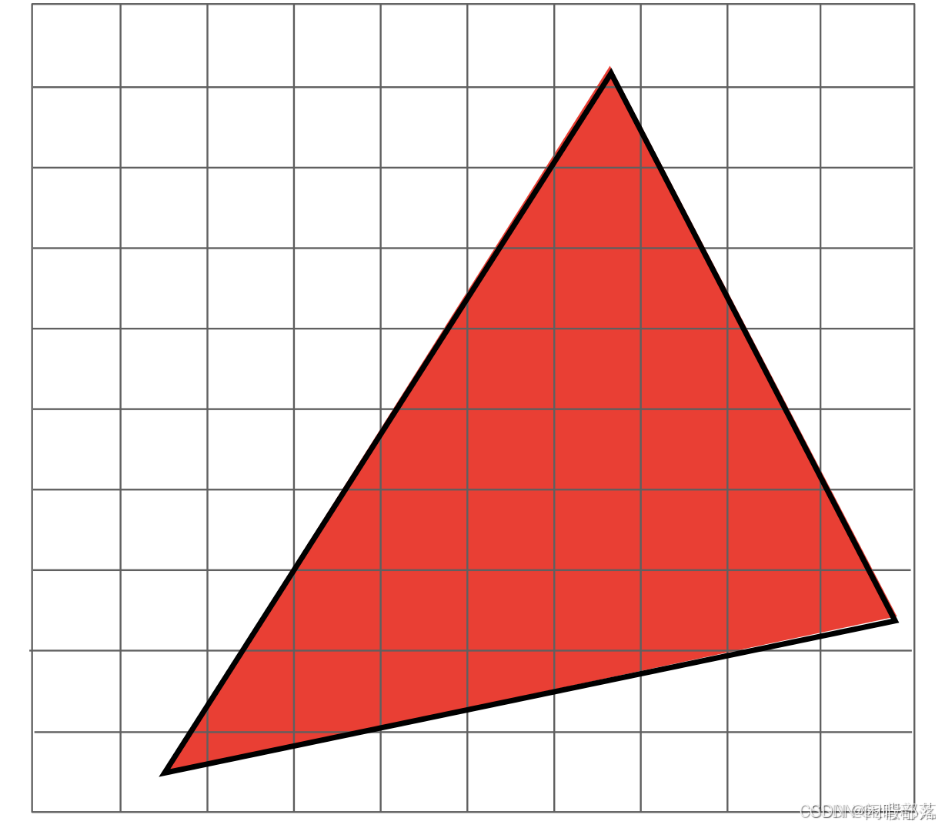
以下图为例,已知三角形的三个顶点坐标以及三角形的颜色值(255,0,0),我们只需判断每一个像素的中心点(x+0.5,y+0.5)是否在三角形内即可,若在其内部则将该像素颜色赋为(255,0,0)。
3.1三角形的好处
- 是最基础的多边形,任意多边形都可以拆分成三角形;
- 可以保证三个顶点在同一平面;
- 三角形内部和外部定义明确,有利于像素的着色;
- 用于在三角形顶点处插值的明确定义方法(重心插值)。
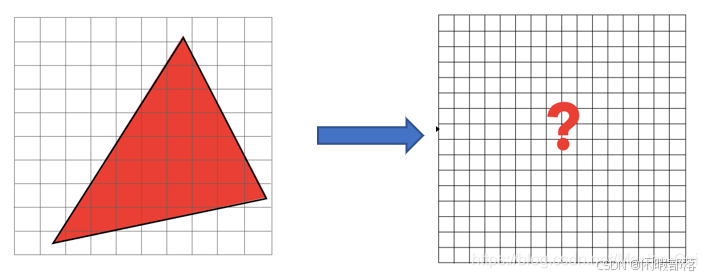
如下图所示,给定了三个点,如何将得到的三角形绘制在右边的屏幕上?进行三角形光栅化处理。
3.2怎么进行光栅化
首先需要进行采样,采样的意思就是对给定的函数进行离散化,比如上图中,要实现一个判断屏幕上的像素是否在三角形内的函数,然后将三角形顶点构成的最大长方形区域内所有点作为函数的输入,判断这些点是否在三角形内,如果在三角形内,就将屏幕上的像素点进行点亮。这个过程就是采样。其他采样的例子包括对视频进行时间上的采样,这样就可以得到视频中的某几帧画面。
对函数进行采样之后,就知道了哪些点在三角形内,然后将对应的像素进行点亮就得到了要绘制的三角形。
判断某个点是否在三角形内,如果P在三角形ABC内部,则满足以下三个条件:P,A在BC的同侧、P,B在AC的同侧、PC在AB的同侧。某一个不满足则表示P不在三角形内部。
要实现三角形的光栅化,需要对像素点进行采样,即遍历所有的像素点,判断像素点是否在三角形内。其对应的代码如下:
for(int x = 0 ; x < xmax ; ++x){
for(int y = 0 ; y < ymax ; ++y){ //遍历每个像素点
image[x][y] = inside(tri,x+0.5,y+0.5); //在三角形内部的像素点作为采样对象
}
}
其中inside函数是用于判断像素点是否在三角形内部的函数,其最经典的实现方法是利用叉乘,如下图:
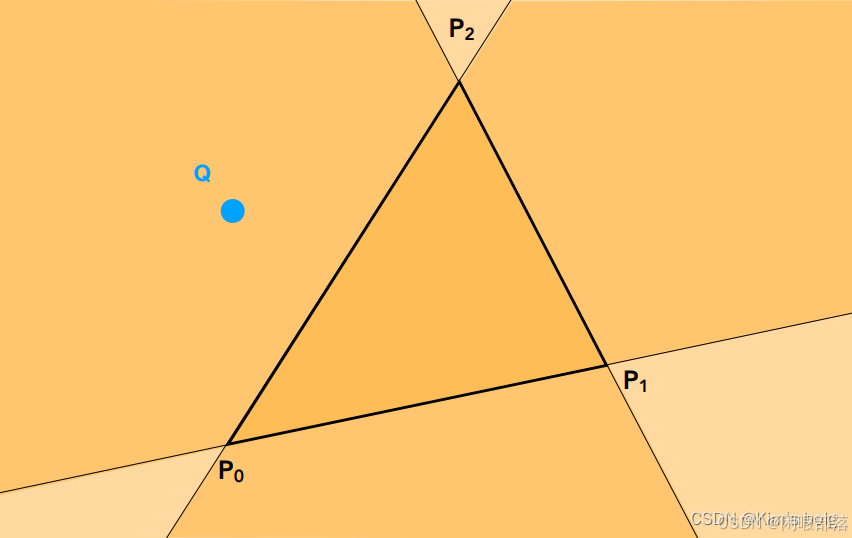
我们从P2按顺时针顺序来看,直线P2P1 与直线P2Q的又乘,利用右手定则,指向屏幕内,说明点(在直线P2 P1 的右侧。同理直线P1 P0与直线P1 Q的又乘,推出点Q在直线P1 P0的右侧;而最后又推出Q在直线P0 P2的左侧。说明点Q在三角形外部。
在上面叙述的方法中,我们需要遍历屏幕空间的每一个像素,运算量较大,
因此,三角形光栅化只需要遍历每一个点,判断是否位于其内部即可。当然我们还可以进一步进行优化,因为显然并没有必要去测试屏幕中的每一个点,一个三角形面可能只占屏幕很小的部分,可以利用一个bounding box包围住想要测试的三角形,只对该bounding box内的点进行采样测试,如下图:
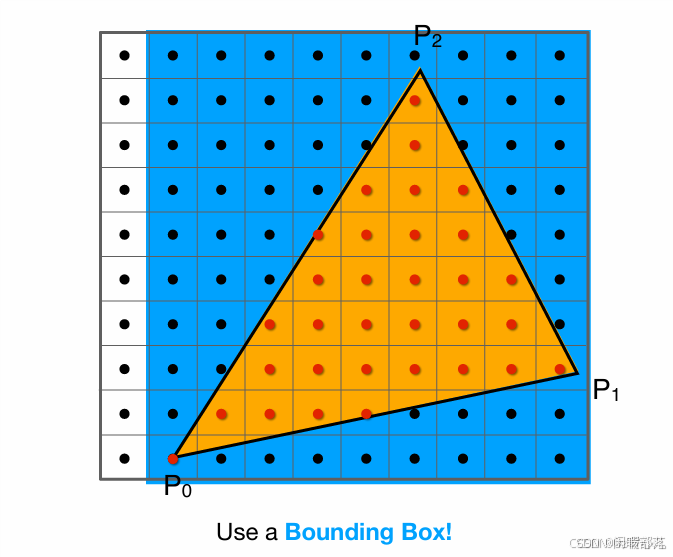
3.3光栅化引起的问题
利用上述三角形光栅化的方法,我们最后得到的图形是下图这样的:
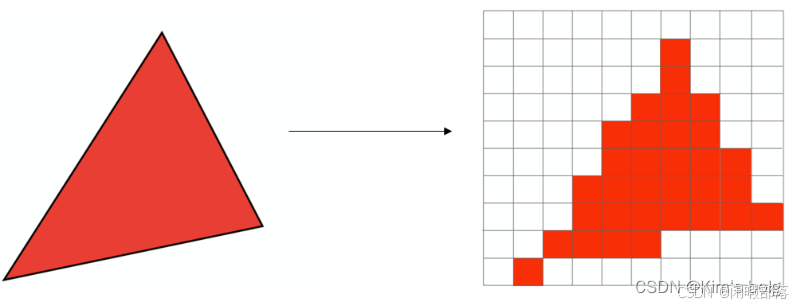
可以看到,本来是三角形的,但是经过采样之后根本就不是三角形,边缘部分非常不平整光滑,这种现象在图形学中称为走样。经过上述光栅化后的图像如下图所示,明显可以看出在三角形的边界上出现了锯齿现象(走样)。
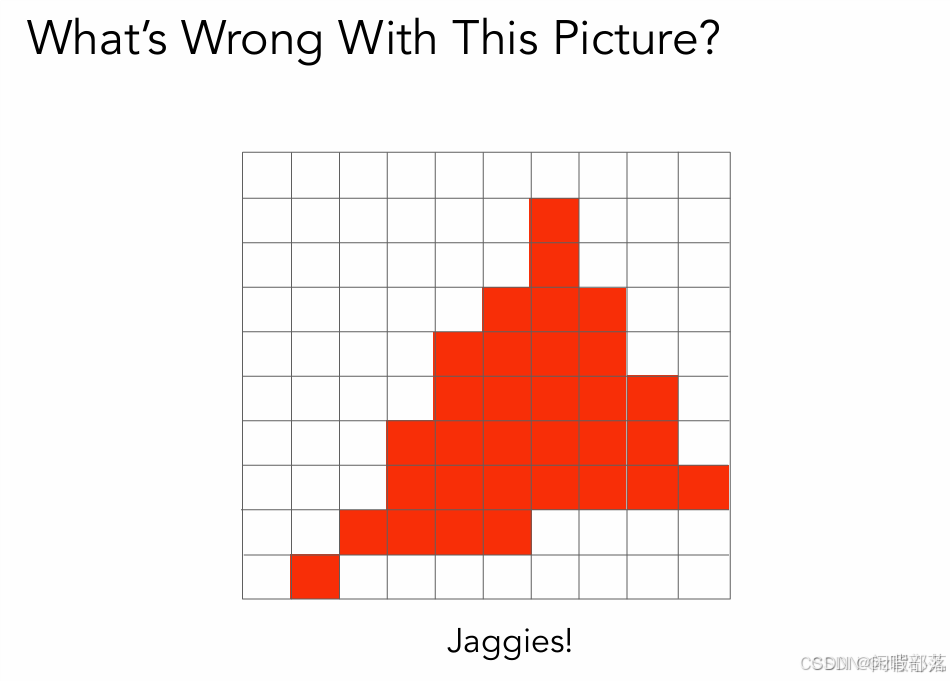
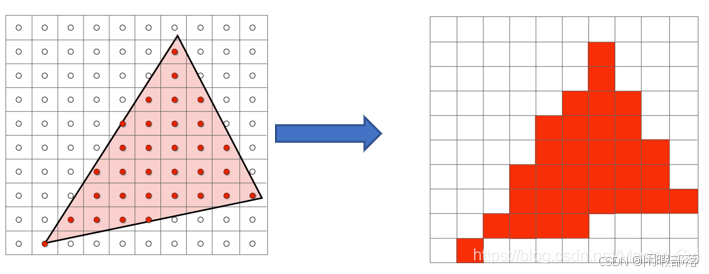
为什么会走样呢?其本质是采样的频率过低,导致采样频率无法跟上图像的频率。通俗地讲就是采样数过少,可以想象一下,像素点足够多,采样数足够大,那么精细度就会越高,一个个的锯齿将会变得十分小至肉眼无法分辨,这样看上去就是平整光滑的了。所以这就需要进行抗锯齿(走样)处理(见二、节)。
4.光栅化算法
请记住,光栅化算法的主要目标是解决可见性问题。为了准确显示 3D 对象,识别哪些表面是可见的至关重要。在了解光栅化问题时,我们需要清楚以往时用什么方法去解决可见性问题(即展示在我们屏幕上)。最常见的两种就是光栅化和光线追踪。
4.1光线追踪——解决可见性问题
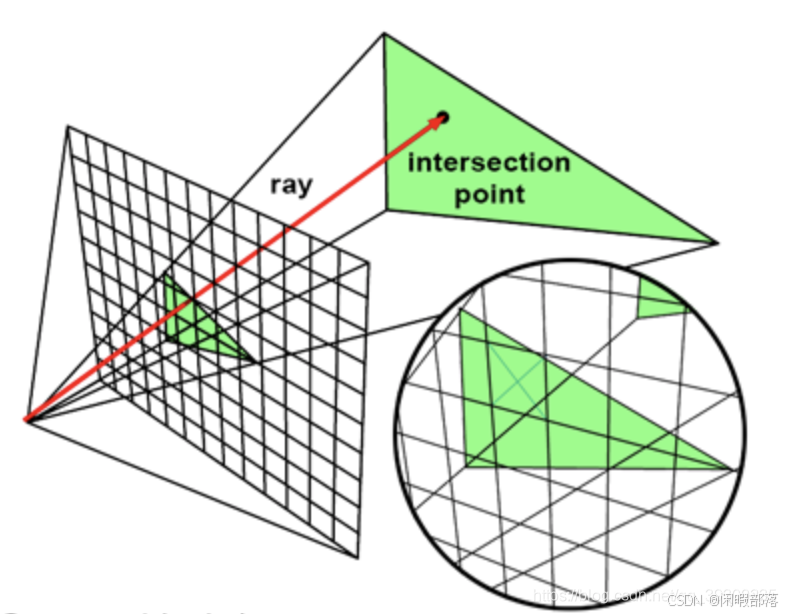
如上图,我们从摄像机的位置,向我们的屏幕(近平面)的每个像素中心发射一条光线,光线和场景中哪个对象相交,并且距离屏幕最近,则将该相交对象的颜色将保存在屏幕上。我们可以用以下伪代码表示该过程。
for (each pixel in image) {
Ray R = computeRayPassingThroughPixel(x,y); //获取光线的方向
float tclosest = INFINITY; //记录最近的距离
Triangle triangleClosest = NULL; //最近的三角形
//寻找最近的三角形
for (each triangle in scene) {
float thit;
if (intersect(R, object, thit)) {//判断相交成功返回1
if (thit < closest) {
triangleClosest = triangle; //如果最近则保存该三角形
}
}
}
if (triangleClosest) {
imageAtPixel(x,y) = triangleColorAtHitPoint(triangle, tclosest); //记录颜色
}
}我们发现这里的代码只判断和三角形求交点,但是我们的图形是其他形状的呢?而我们的OpenGL,DirectX都是只处理三角形的,这又是为什么呢?这是因为三角形是最简单的图形,它们构成的片面是共面的而且最容易求交计算。我们知道光线追踪最昂贵的就是光线和对象的求交计算。所以使用三角形可以缓解我们计算的压力,因此我们在渲染其他图形时,也会使用三角剖分去将一个复杂几何图形转换为多个三角形的集合。
因为昂贵的求交运算,我们现在基本上都是使用光栅化解决可见性问题。但是在渲染高质量图形时,都会结合光栅化和光线跟踪,利用光栅化和z缓存计算眼睛第一个可见表面,反射和折射利用光线跟踪计算。这里还要注意区别光线跟踪和光线传输算法,前者是用来处理可见性问题,后者是用来计算某一点的颜色。
4.2光栅化——解决可见性问题
栅格化采用相反的方法。为了解决可见性,它实际上是将三角形“投影”到屏幕上,换句话说,我们使用透视投影从该三角形的3D表示转换为2D表示。可以通过将组成三角形的顶点投影到屏幕上来轻松完成此操作。该算法的下一步是使用某种技术来填充该2D三角形覆盖的图像的所有像素。这两个步骤如下图所示:
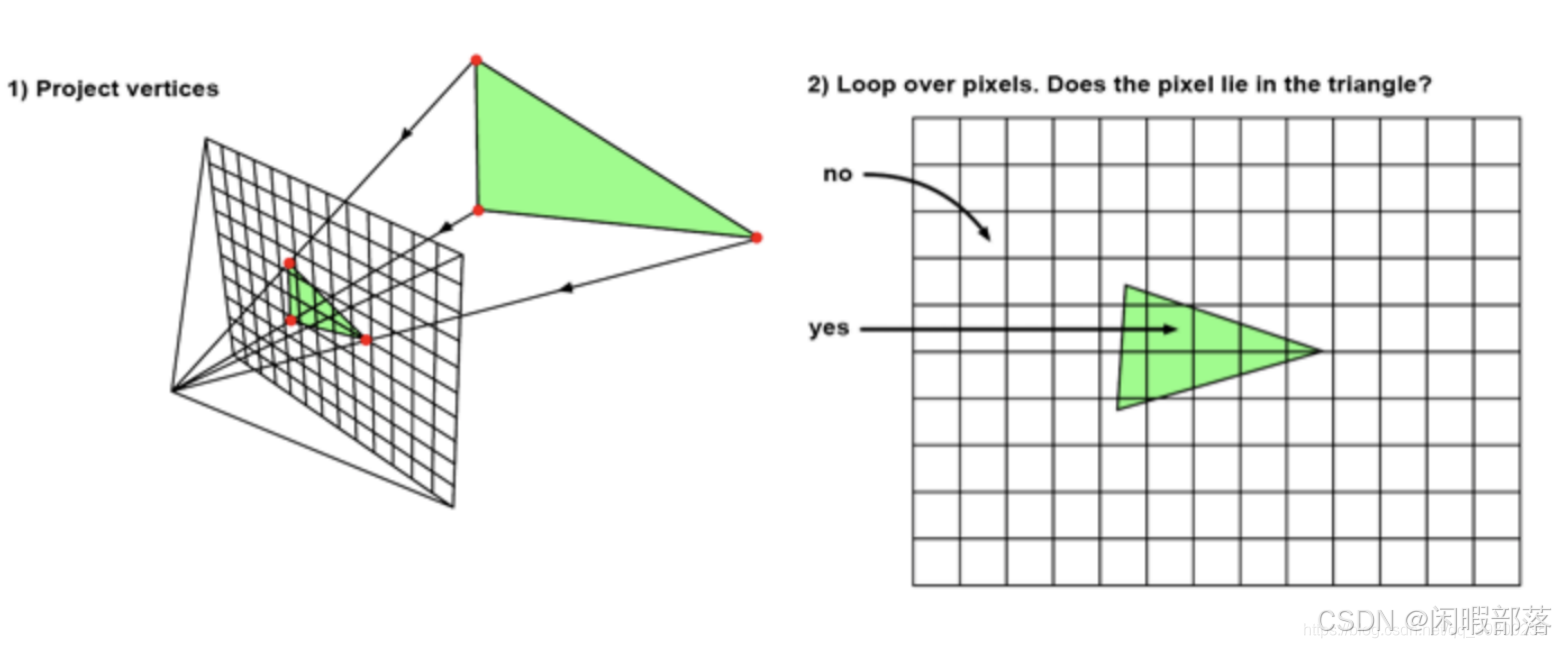
与光线跟踪方法相比,该算法是什么样的?首先,请注意,我们需要对场景中的所有三角形进行迭代,而不是首先在光栅化中在外部循环中迭代图像中的所有像素。然后,在内部循环中,我们遍历图像中的所有像素,并找出当前像素是否“包含”在当前三角形的“投影图像”内(如上图)。换句话说,两种算法的内部和外部循环被交换。我们看一下光栅化算法的伪代码:
for (each triangle in scene) { //为每个三角形迭代
//步骤1:利用投影变换去变化坐标点
Vec2f v0 = perspectiveProject(triangle[i].v0);
Vec2f v1 = perspectiveProject(triangle[i].v1);
Vec2f v2 = perspectiveProject(triangle[i].v2);
for (each pixel in image) { //迭代所有像素
//步骤2:当像素位于三角形内时,绘制该像素
if (pixelContainedIn2DTriangle(v0, v1, v2, x, y)) {
image(x,y) = triangle[i].color;
}
}
} 4.3优化的三角形边界盒
同上述bounding box。
虽然我们的光栅化算法相比光线追踪有很大的性能优势,但是即使三角形只包含少数几个像素时,我们仍然需要循环迭代所有的像素。这是一种巨大的浪费,因此我们这里可以做一个优化,我们可以在投影三角形的时候,并计算它的2D边界框,这样只需要遍历边界框内的像素。这在渲染拥有数百万个三角形的复杂对象时,会提升巨大的性能,刚方法如下图:
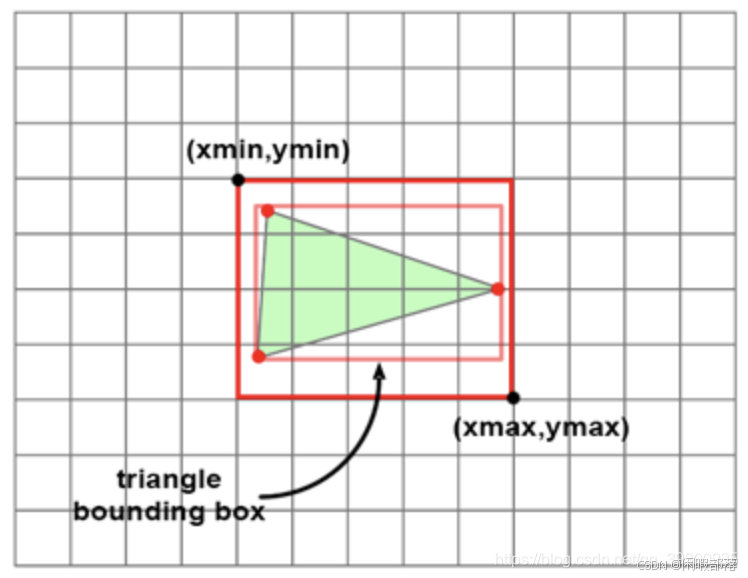
我们对投影后三角形的三个点计算边框并取整,然后匹配像素只需要循环边框内的像素就行了。我们计算边框的伪代码如下:
Vec2f bbmin = INFINITY, bbmax = -INFINITY;
Vec2f vproj[3]; //三角形的3个顶点
for (int i = 0; i < 3; ++i) {
vproj[i] = projectAndConvertToNDC(triangle[i].v[i]);//投影三角形并转换到标准设备空间
// 将标准设备空间的点转换为屏幕像素
vproj[i].x *= imageWidth;
vproj[i].y *= imageHeight;
//计算左上角和右下角的值
if (vproj[i].x < bbmin.x) bbmin.x = vproj[i].x);
if (vproj[i].y < bbmin.y) bbmin.y = vproj[i].y);
if (vproj[i].x > bbmax.x) bbmax.x = vproj[i].x);
if (vproj[i].y > bbmax.y) bbmax.y = vproj[i].y);
} 由于这里我们计算的NDC空间为[0,1](OpenGL中为[-1,1]),所以我们要把他转换到屏幕像素的坐标x [0,imageWidth-1]和y[0,imageHeight-1]。我们获取完2D边界框后可以进行如下循环:
[0,imageWidth-1]和y[0,imageHeight-1]。我们获取完2D边界框后可以进行如下循环:
uint xmin = std::max(0, std:min(imageWidth - 1, std::floor(min.x)));
uint ymin = std::max(0, std:min(imageHeight - 1, std::floor(min.y)));
uint xmax = std::max(0, std:min(imageWidth - 1, std::floor(max.x)));
uint ymax = std::max(0, std:min(imageHeight - 1, std::floor(max.y)));
for (y = ymin; y <= ymin; ++y) {
for (x = xmin; x <= xmax; ++x) {
// 检查像素是否位于三角形内
if (pixelContainedIn2DTriangle(v0, v1, v2, x, y)) {
image(x,y) = triangle[i].color;
}
}
} 我们只要在2D边界框内,判断像素属于三角形内的点,则为其上色。
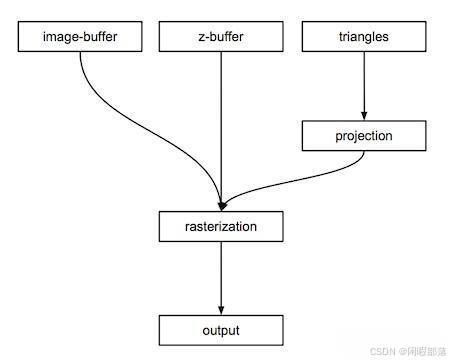
光栅化算法的一个非常高层次的概述(如图下图所示),但它应该能让您很好地了解程序中需要哪些组件来生成图像。我们将需要:
- 图像缓冲区(2D 颜色数组),
- 深度缓冲区(浮点数的 2D 数组),
- 三角形(构成场景的几何图形),
- 将三角形的顶点投影到画布上的函数,
- 栅格化投影三角形的函数,
- 一些代码将图像缓冲区的内容保存到磁盘
5.光栅化步骤
我们介绍完光栅化框架后我们来了解具体实现的细节。
第一步我们先将三角形进行透视投影变换,这一步详细可以看OpenGL中投影矩阵(Projection Matrix)详解_opengl 投影矩阵-优快云博客。
第二步我们在上文完成了2D边界盒的计算。
第三步我们需要了解如何判断像素位于三角形内部。
第四步了解三角形内部点的属性插值。
综上所述:
- 将几何图形转换为三角形可简化该过程。如果将所有基元转换为三角形基元,我们可以开发快速有效的函数将三角形投影到屏幕上,并确定像素是否落在这些 2D 三角形内。
- 栅格化是以对象为中心的。我们将几何图形投影到屏幕上,并通过循环图像中的所有像素来确定它们的可见性。
- 它主要依赖于两种技术:将顶点投影到屏幕上,并确定特定像素是否位于 2D 三角形内。
- 在 GPU 上运行的渲染管线基于光栅化算法。
二、抗锯齿的解决方案
1.锯齿产生的原因
锯齿产生的原因就是因为信号的变化频率高,而相应的采样频率低。就三角形边缘不规则的情况来说,因为三角形的边上是无限多个点,而用有限个方块去逼近无限多个点的三角形的边,所以当然会产生不规则的锯齿,硬件的解决办法一是可以加大屏幕的分辨率,使得像素变小,从而可以得到更多个有限的方块去逼近三角形。而软件的方法就是加入抗锯齿算法。无论是硬件方法还是软件方法,都不能完全解决锯齿问题,只能缓解锯齿问题,直到人眼察觉不出来。
以上都是信号与系统方面的理解,直观的针对上面的锯齿现象来说,为什么我们能看见明显的锯齿,很简单,就是边界部分的颜色变换太快了,缺少过渡,那么,很容易想到的一个思路就是对靠近边界的像素的颜色进行一个过渡处理。怎么做呢,有如下三种方法,一种是先对原图进行低通滤波,之后再光栅化,另外两种是超采样(SSAA)、多采样(MSAA)(详见:Android OpenGL ES详解——多重采样抗锯齿(MSAA)-优快云博客)。
2.先低通滤波再采样
低通滤波就是一个平均的过程,以该像素点周围像素值的平均值来代替当前像素点的值,很明显,这样越靠近边界的地方,其值就会越低或越高,起到了一个颜色过渡的作用
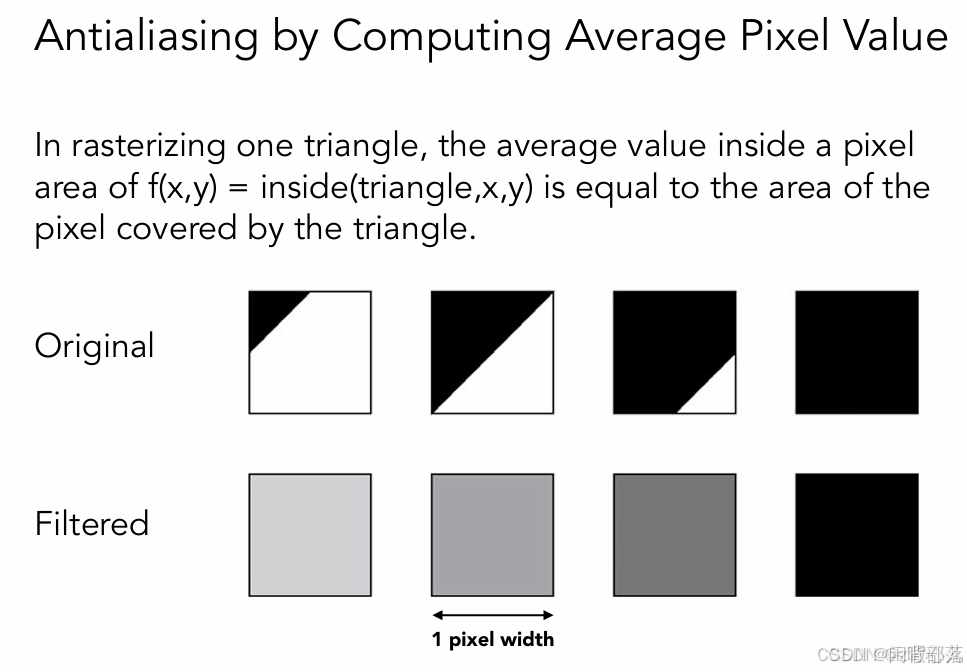
3.软件上抗锯齿的方法及原理
锯齿问题的解决方法是用有限离散的像素点去逼近连续的三角形。
3.1超采样抗锯齿算法SSAA
SSAA(super sampling antialisa,超采样抗锯齿算法)
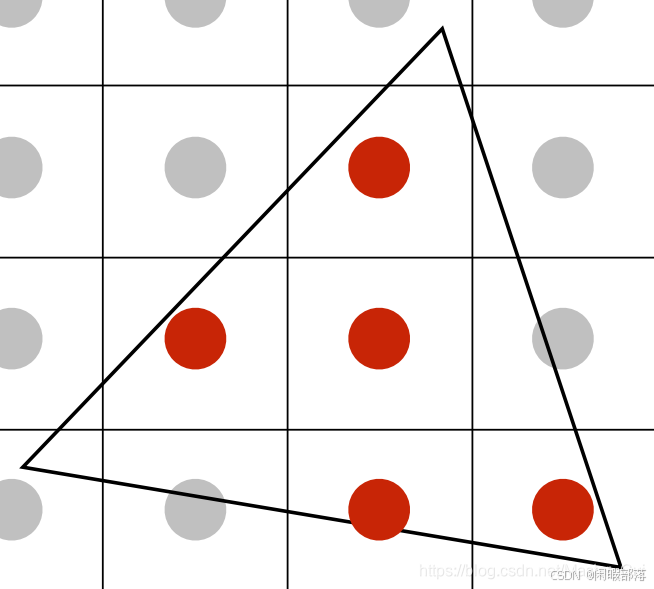
SSAA的思想就是将一个像素分解成2*2,3*3,4*4......,然后判断分解后像素中的4个或者9个或者16个像素点是否在三角形内,如果在像素内,就将点绘制成红色,然后将这4个或者9个或者16个像素点的像素值求平均值,最后作为整个像素点的像素值。
众所周知,高分辨率图形的渲染会极大地消耗GPU运算资源和显存容量及带宽,因此SSAA资源消耗极大,即使是最低的2x也未必能够轻易承受。
此方法无非就是提高分辨率,也就是增加采样点,如下图,将每个像素点细分成了4个采样点:
以2*2为例,比如采样结果是这样的
然后将三角形周围的每个像素点一分为4,就会变成下面这样的
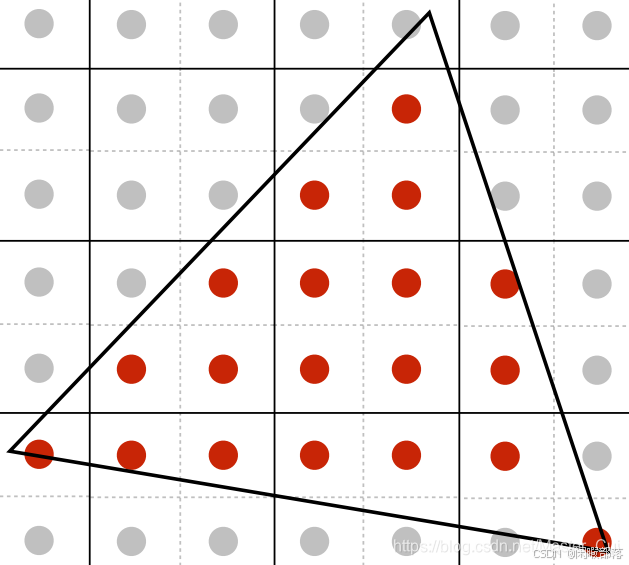
之后根据每个采样点进行着色,每有一个采样点被覆盖就着色一次。这样得到了每个采样点的颜色之后,我们将每个像素点内部所细分的采样点的颜色值全部加起来求平均,作为像素点的抗走样之后的颜色值。结果如下:
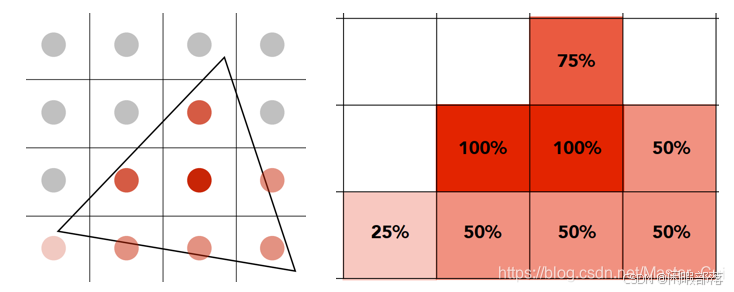
到此,SSAA算法结束。
如前面所说,使用SSAA过后,锯齿依然会存在,只不过SSAA通过超采样的方式把原本是纯白色的像素绘制成了介于白色和红色之间的像素,从而使得图形边缘锯齿看起来不那么突兀,从而达到了抗锯齿的作用

右边是使用了SSAA的结果,可以看到,锯齿不那么突兀了。
3.2多采样抗锯齿算法MSAA
MSAA(multi-sampling antialisa,多采样抗锯齿算法)
SSAA每次计算时,都要计算每个子采样像素的像素值,如果采样频率越高,则计算量越大,对此,MSAA出现了。
MSAA是SSAA的改进版,SSAA仅仅为了边缘平滑,而不得不重新以数倍的分辨率渲染整个画面,造成宝贵显卡处理资源的极大浪费,因此MSAA正是为了改善这种情况而生。MSAA实现方式类似于SSAA,不同之处在于MSAA仅仅将3D建模的边缘部分放大处理,而不是整个画面,简单说就是:3D模型是由大量多边形所组成,MSAA仅仅处理模型最外层的多边形,因此显卡的负担大幅减轻。
MSAA的思想就是如果有子采样像素在三角形内,那么,就认为像素点需要着色,采样后,看有多少个子采样像素点在三角形内,然后计算在三角形内的子采样像素占所有采样点的比重,最后把整体的像素值(比如红色)乘以该比重,就得到了最终绘制的像素值。
所谓多采样,就是对每一个像素点,再将其细分为若干个亚像素点(如4个),判断该像素点内有几个亚像素点在三角形内部,根据亚像素点在三角形内部的比例调整该像素点的值,如4个亚像素点都在三角形内部,那么将该像素点颜色赋值为255,若只有3个在内部,则赋值为int(255*3/4),以此类推。(多采样MSAA,详见:Android OpenGL ES详解——多重采样抗锯齿(MSAA)-优快云博客)
比如下面这个像素被采样了四次
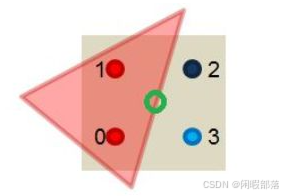
使用MSAA并不会计算四次子像素值,而是将红色的像素值*0.5(0.5=2/4,其中2指的是2个子采样像素在三角形内部,4指的是像素总数),最终得到一个浅红色作为该整个像素的像素值,节约计算量,加快算法速度。
MSAA虽然趋于易用化,十分流行,但是缺点也很明显
- 如果画面中单位物体较多,需要处理的边缘多边形数量也自然增多,此时MSAA性能也会下降的十分厉害;
- 同样倍数的MSAA,理论上边缘平滑效果与SSAA相同,但是由于仅仅处理边缘部分的多边形,因此非边缘部分的纹理锐度远不如SSAA。
3.3SSAA和MSAA的区别
MSAA仍将像素分为多个采样点,不同的是不再需要每有一个采样点被覆盖就着色一次,而是统计被覆盖采样点的个数,例如有两个采样点被覆盖,那么只需要用改像素中心计算出来的颜色值乘以50%即可,这样大大减少了计算量,如上述。
光栅化并缓解了锯齿问题后,就可以将一系列的问题画到屏幕上。
我们在处理完图形光栅化之后,还要考虑物体先后的关系?这十分重要,更直白的说法是,要搞清楚物体的图层,哪个物体会被哪个物体遮挡,哪个物体会遮挡哪个物体。具体的说每个像素点所对应的可能不止一个三角形面上的点,该选择哪个三角形面上的点来显示呢?
三、像素重叠问题
1.光栅化规则
在某些特殊情况下,一个像素可能重叠多个三角形。如图下所示:
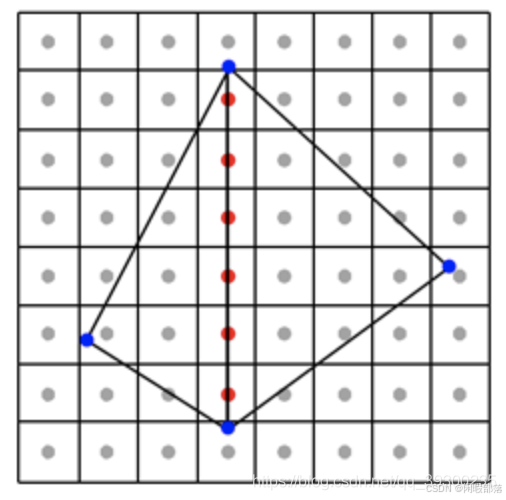
当一个像素恰好位于两个三角形共享的边缘上时,就会发生这种情况。此类像素将通过两个三角形的覆盖率测试。如果它们是半透明的,则由于半透明对象彼此组合的方式(想象两张叠加的半透明塑料薄片),像素重叠两个三角形的地方可能会出现暗边。比不透明的纸张更不透明,并且看起来比单独的纸张更暗)。您将得到类似于下图所示的内容:
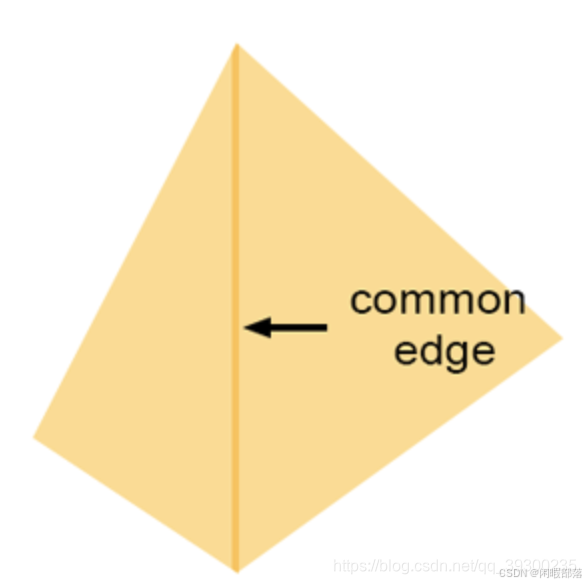
这是一条较暗的线,其中两个三角形共享一条边。该问题的解决方案是提出某种规则,以确保像素永远不会重叠两个共享边的三角形两次。我们该怎么做?大多数图形API(例如OpenGL和DirectX)都定义了一些它们称为左上角的规则。左上角的规则是,如果像素或点位于三角形内部或位于三角形的上边缘或任何被视为左边缘的边缘上,则该像素或点被视为与三角形重叠。什么是上边缘和左边缘?
上边缘是完全水平的边缘,其定义顶点在第三个边缘之上。从技术上讲,这意味着向量V [(X + 1)%3] -V [X]的y坐标等于0,并且其x坐标为正(大于0)。
左边缘本质上是上升的边缘。请记住,在我们的情况下,顶点是按顺时针顺序定义的。如果边缘的相应向量V [(X + 1)%3] -V [X](其中X可以为0、1、2)具有y坐标为正,则认为该边缘上升。
上述图示为:
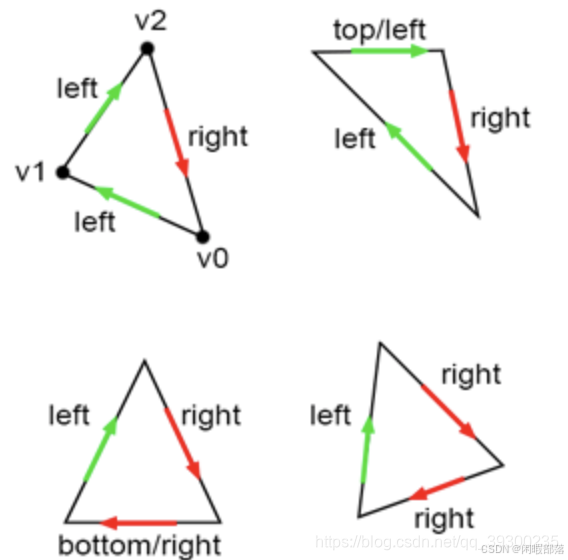
绿色标记的边是我们的上边缘和左边缘。实现代码如下:
//定义的坐标
Vec2f v0 = { ... };
Vec2f v1 = { ... };
Vec2f v2 = { ... };
//边缘函数计算
float w0 = edgeFunction(v1, v2, p);
float w1 = edgeFunction(v2, v0, p);
float w2 = edgeFunction(v0, v1, p);
Vec2f edge0 = v2 - v1;
Vec2f edge1 = v0 - v2;
Vec2f edge2 = v1 - v0;
bool overlaps = true;
// 通过边缘函数返回值判断点是否在边上,如果点在边上,判断是否在左边缘或者上边缘。
//如果不在边上判断是否在三角形内
// 上边缘本质为向量y值为0,x值大于0,左边缘本质向量是y大于0。
overlaps &= (w0 == 0 ? ((edge0.y == 0 && edge0.x > 0) || edge0.y > 0) : (w0 > 0));
overlaps &= (w1 == 0 ? ((edge1.y == 0 && edge1.x > 0) || edge1.y > 0) : (w1 > 0));
overlaps &= (w1 == 0 ? ((edge2.y == 0 && edge2.x > 0) || edge2.y > 0) : (w2 > 0));
if (overlaps) {
//如果像素和三角形重叠,则进行之后的光栅化
...
} 2.物体深度计算
物体和物体之间的深度信息或者前后位置关系该如何表达?表达物体深度的方式有两种,一种是画家算法(讲解如下),另一种是z-buffer算法(讲解如下)。
2.1画家算法
画家算法就是首先绘制距离较远的场景,然后用绘制距离较近的场景覆盖较远的部分。
画家算法首先将场景中的多边形根据深度进行排序,然后按照深度从大到小顺序进行描绘。
比如下面的场景,深度顺序背景、山、草地、树木,所以先绘制背景,再绘制山,然后绘制草地,最后绘制树木。

画家算法通常会将不可见的部分覆盖,可以解决可见性问题。
但是在某些情况下,画家算法也会失效,比如下面这幅图,pqr三个图形彼此互相都有遮挡,无法对三个物体的深度进行排序。
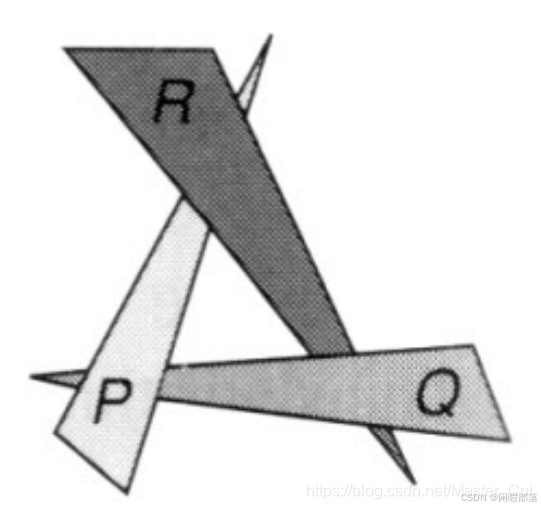
此时,无法通过画家算法来显示物体之间的深度关系,因此,深度缓冲算法出现了。
2.2Z-Buffer算法(深度缓存算法)
深度缓冲是光栅化过程中的一个关键步骤,它用于决定哪些物体是可见的。深度缓冲是一个二维数组,每个元素对应于场景中的一个像素,存储了该像素的深度值。深度值表示从摄像头到该像素的距离,用于决定哪些物体是可见的。当然是离摄像头最近的像素点显示,这就需要用到深度缓冲。因此,z 缓冲区记录场景中每个像素的最近对象的距离(3D物体的远近通过 Z轴表示,故又称Z-Buffer)
深度缓冲的计算过程如下:
-
从摄像头出发,将场景中所有可见物体的表面点都投影到二维图像平面上,得到一个点集。
-
对于每个点,计算它的深度值,即从摄像头到该点的距离。
-
将深度值存储到深度缓冲中,如果该像素已经被其他物体覆盖,则更新深度值。
-
对于场景中的每个物体,从近到远的顺序进行渲染。
2.2.1深度缓存——解决三角形重叠问题
我们的目标是产生场景的图像。我们有两种可视化程序结果的方式,一种是将渲染的图像直接显示在屏幕上,另一种是将图像保存到磁盘上,然后使用诸如Photoshop之类的程序稍后预览图像。但是在这两种情况下,我们都需要以某种方式存储正在渲染的图像,并且为此,我们在CG中使用所谓的图像或帧缓冲区。就是具有图像大小的二维颜色数组。在渲染过程开始之前,将创建帧缓冲区,并将像素全部设置为黑色。在渲染时,当对三角形进行栅格化时,如果给定像素与给定三角形重叠,则我们将该三角形的颜色存储在该像素位置的帧缓冲区中。光栅化所有三角形后,帧缓冲区将包含场景的图像。剩下要做的就是将缓冲区的内容显示到屏幕上,或将其内容保存到文件中。但是如果我们的给定像素与多个给定三角形重叠,这时候怎么选择要显示的三角形呢?显然我们需要的是距离我们屏幕最近的三角形的点。我们可以采用称为Z-缓存算法的方法来获取最近的三角形的点。
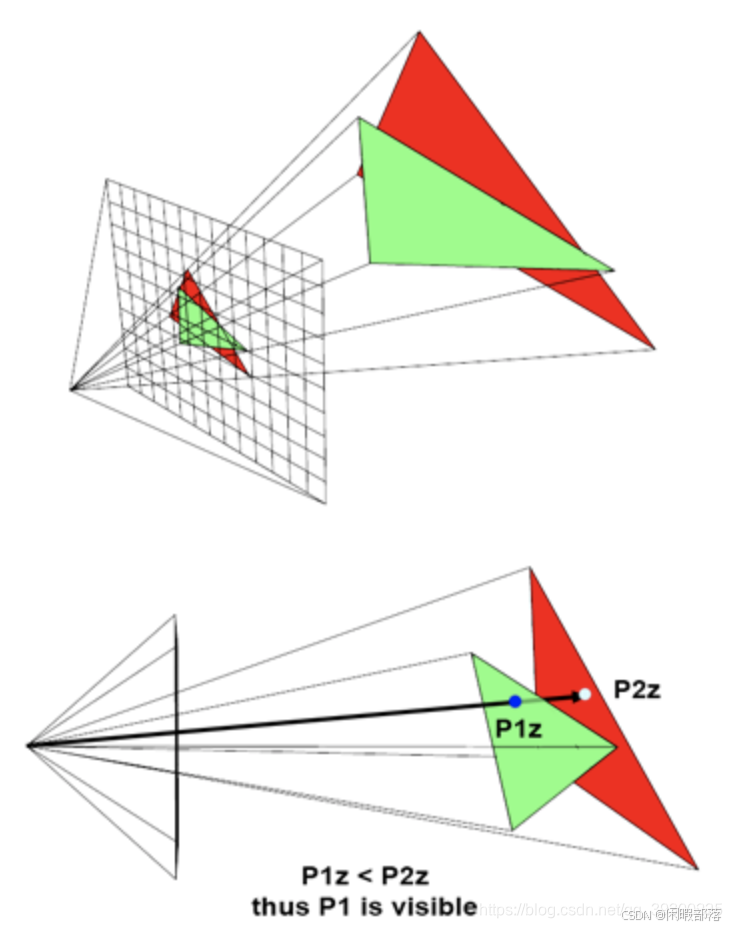
Z缓冲区无非是另一个二维数组,它的维数与图像的维数相同,但是它不是颜色数组,而只是一个浮点数数组。在开始渲染图像之前,我们将该数组中的每个像素初始化为非常大的数量。当像素与三角形重叠时,我们还将读取存储在该像素位置z缓冲区中的值。该数组用于存储从相机到图像中任何像素重叠的最近三角的距离。伪代码如下:
// Z-缓存就是一个浮点的2维数组
float buffer = new float [imageWidth * imageHeight];
// 用非常大的数初始化该2维数组
for (uint32_t i = 0; i < imageWidth * imageHeight; ++i)
buffer[i] = INFINITY;
for (each triangle in scene) {
// 投影三角形
...
// 计算2D边界盒
...
for (y = ymin; y <= ymin; ++y) {
for (x = xmin; x <= xmax; ++x) {
// 判断像素是否和三角形重叠
float z; // 三角形上该点到摄像机距离(深度)
if (pixelContainedIn2DTriangle(v0, v1, v2, x, y, z)) {
// 如果当前的三角形的z值是最近的则更新z缓存的值,并绘制颜色
if (z < zbuffer(x,y)) {
zbuffer(x,y) = z;
image(x,y) = triangle[i].color;
}
}
}
}
} 在上述的过程中,我们似乎只用到了x,y值,z值没有,那么考虑在下面的这种情况下,应该怎样给屏幕像素赋值呢?很显然,对于同时位于多个三角形内部的像素点,该点的值我们应该赋最近的三角形的颜色值,这个最近,怎么体现,就是用z值体现的,当z都为正的情况下,z越小,代表该点离我们越近。
所谓深度缓存(Z-Buffer),就是存储屏幕空间像素点处最小深度值的二维矩阵,与z-buffer对应,有一个frame-buffer,其存储的是像素点处的颜色值(RGB值)。
因为在透视投影钟,可以得到每个像素的深度信息Z。
深度缓冲的算法过程如下:
1.首先分配一个数组buffer,数组的大小为像素的个数,数据中的每个数据都表示深度,初始深度值为无穷大
2. 随后遍历每个三角形上的每个像素点[x,y],如果该像素点的深度值z<zbuffer[x,y]中的值,则更新zbuffer[x,y]值为该点深度值z,并更新该像素点[x,y]的颜色为该三角形上像素点上的颜色。
Z-Buffer算法可表示如下

举个形象的例子,其中数字代表深度,越小代表离相机越近,我们可以使用以上算法实现像素颜色的更新。示例直观展示如下

如上图,首先把屏幕上所有的像素点的深度都设置为无穷大,然后先绘制一个所有深度都为5、颜色为红色的三角形,因为5比无穷大小,所以,把三角形中所有的像素点都绘制到屏幕上,颜色为红色,深度更新为5,之后,又有一个紫色的三角形。其深度值各不相同,以深度为8的顶点为例,8>5,所以这点像素会被深度为5的像素遮挡,不做任何处理。再以深度为3的顶点为例,因为3>5,所以更新这点的像素颜色为紫色,深度为3。其余像素同理
z-buffer算法的好处就是不区分三角形绘制的先后顺序,只需要找到每个像素上深度值的最小的像素和颜色即可。
深度图的样子
深度图分为两种,一种是近处物体被描画为深色,而远处物体被描画为浅色,这是因为在透视投影时,将相机的朝向定为了Z轴正方向,那么在Z轴方向,离远点越远,像素值就越大。

而另一种如下图所示,在透视投影时,将相机的朝向定为了Z轴负方向,那么在Z轴方向,离远点越远,Z值越小,像素值就越小,所以越远深度图的颜色就越黑

2.2.2边缘函数——检测三角形重叠问题
要找到像素是否与三角形重叠有许多方法,这里我们使用Juan Pineda于1988年提出,并发表在论文“多边形栅格化的并行算法”中的方法。我们将首先描述他的方法的原理。假设三角形的边缘可以看作是将2D平面(图像的平面)一分为二的线。 Pineda方法的原理是找到一个称为边缘函数的函数,这样,当我们测试该点在哪条线的哪一侧(图2中的点P)时,该函数将返回负数。在该行的左边,当正点在该行的右边时为正数;在该点正好在该行上时为零。如下图所示:
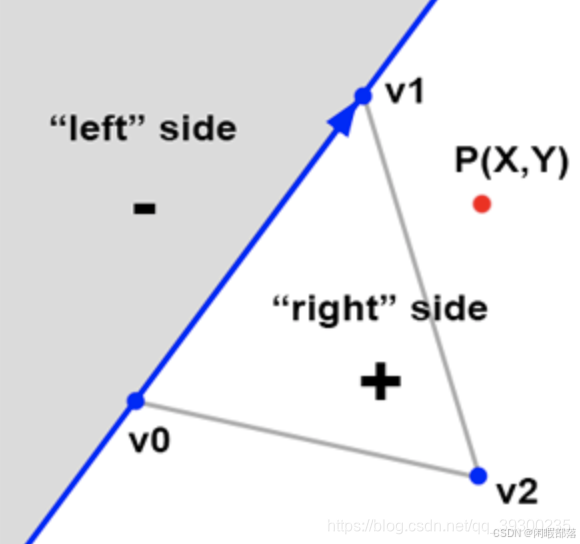
上图中我们将此方法应用于三角形的第一个边缘(由顶点v0-v1定义。请注意顺序很重要)。如果现在将相同的方法应用于其他两个边(v1-v2和v2-v0),则可以清楚地看到存在一个区域(白色三角形),其中所有点均为正。如果P实际上是像素中心的一个点,则可以使用此方法查找像素是否与三角形重叠。如果在这一点上,我们发现边缘函数为所有三个边缘返回正数,则像素包含在三角形中(或可能位于其边缘之一上),如下图所示:
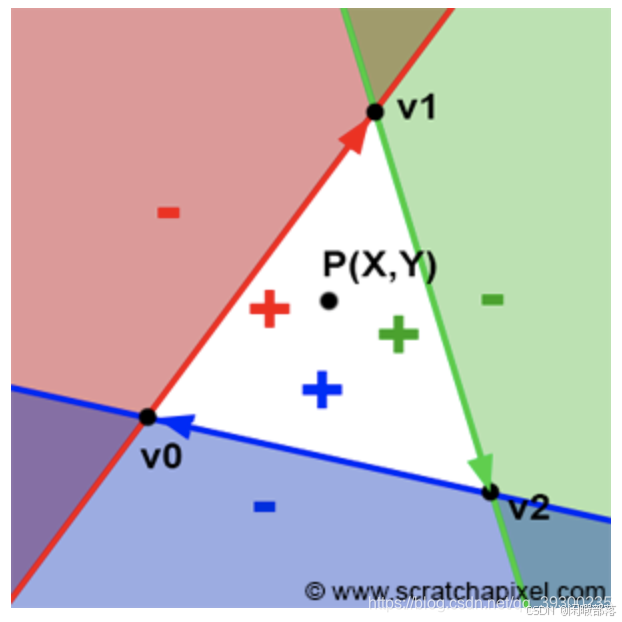
要注意的是这里的顺序一定要是顺时针(如果为逆时针,则内部为负数),Pinada使用的函数也恰好是线性的,这意味着可以递增地计算它。现在我们了解了原理,让我们找出该函数是什么。边函数定义为(对于由顶点V0和V1定义的边):
![]()
该函数值和点P有如下关系:
- E(P) > 0 ,P在右侧
- E(P) = 0 ,P在线上
- E(P) < 0 ,P在左侧
其实该公式正是向量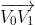 和向量
和向量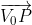 的叉积,叉积又可以表示平行四边形面积,叉积公式如下所示:
的叉积,叉积又可以表示平行四边形面积,叉积公式如下所示:
![]()
其中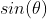 表现了正负性(我们用右手定则也可以轻松判断正负)。我们分别计算三条利用公式:
表现了正负性(我们用右手定则也可以轻松判断正负)。我们分别计算三条利用公式:
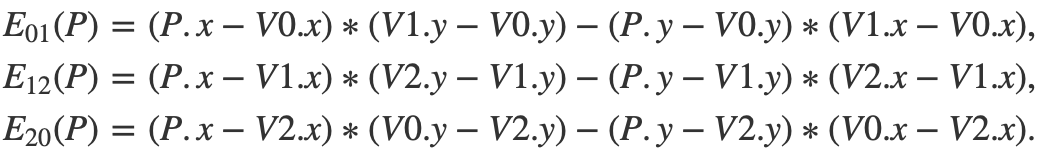
若三者都为大于0的数,则表明点P位于三角形内。代码:
bool edgeFunction(const Vec2f &a, const Vec3f &b, const Vec2f &c)
{
return ((c.x - a.x) * (b.y - a.y) - (c.y - a.y) * (b.x - a.x) >= 0);
}
bool inside = true;
inside &= edgeFunction(V0, V1, p);
inside &= edgeFunction(V1, V2, p);
inside &= edgeFunction(V2, V0, p);
if (inside == true) {
// 点P在由点V0,V1,V2构成的三角形内部
...
} 当心,边缘顺序问题!!!

我们一直在讨论但在 CG 中非常重要的事情之一是声明构成三角形的顶点的顺序。 它们是两种可能的约定,如图 8 所示:顺时针或逆时针排序或环绕。 顺序很重要,因为它本质上定义了三角形的一个重要属性,即法线的方向。 请记住,三角形的法线可以通过两个向量 A=(V2-V0) 和 B=(V1-V0) 的叉积来计算。 假设 V0={0,0,0}、V1={1,0,0} 且 V2={0,-1,0},则 (V1-V0)={1,0,0} 且 (V2 -V0)={0,-1,0}。 现在让我们计算这两个向量的叉积:
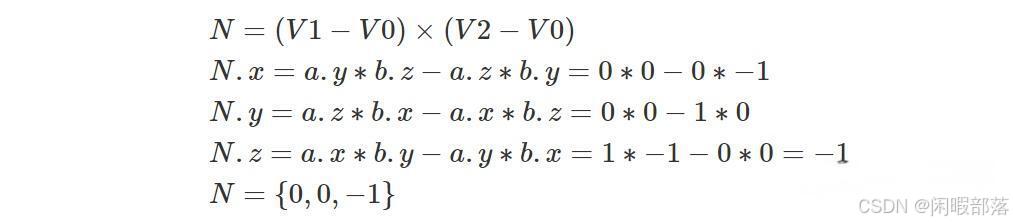
但是,如果按逆时针顺序声明顶点,则 V0={0,0,0}、V1={0,-1,0} 且 V2={1,0,0}、(V1-V0)= {0,-1,0} 且 (V2-V0)={1,0,0}。 让我们再次计算这两个向量的叉积:
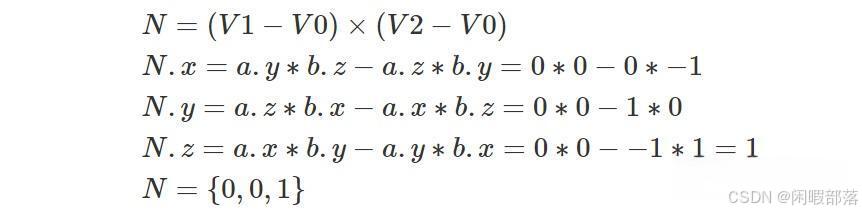
顺序定义了法线的方向:
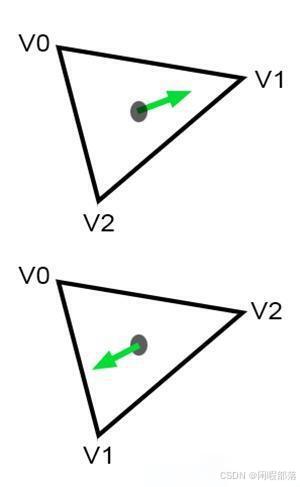
顺序定义三角形内的点是正值还是负值:
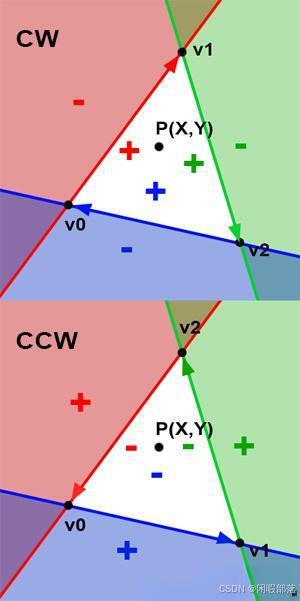
正如预期的那样,两条法线指向相反的方向。 由于许多不同的原因,法线的方向非常重要,但最重要的原因之一是面部剔除。 大多数光栅化器甚至光线追踪器都可能无法渲染法线背向相机的三角形。 这称为背面剔除(backface culling)。 大多数渲染 API(例如 OpenGL 或 DirectX)都提供关闭背面剔除的选项,但是,你仍然应该意识到顶点排序在渲染内容等方面发挥着重要作用。 毫不奇怪,边缘函数是其中之一。
总之,根据你使用的边缘排序约定,可能需要使用边缘函数的一个或另一个版本。
2.2.3插值计算深度值
我们根据前文的知识,我们再看我们的光栅化器,伪代码如下:
float *depthBuffer = new float [imageWidth * imageHeight];
// 初始化深度缓存
for (uint32_t y = 0; y < imageHeight; ++y)
for (uint32_t x = 0; x < imageWidth; ++x)
depthBuffer[y][x] = INFINITY;
for (each triangle in scene) {
//投影三角形
...
// 计算三角形的边界盒
...
for (uint32_t y = bbox.min.y; y <= bbox.max.y; ++y) {
for (uint32_t x = bbox.min.x; x <= bbox.max.x; ++x) {
if (pixelOverlapsTriangle(i + 0.5, j + 0.5) {
// 计算三角形上点的深度值
float z = computeDepth(...);
// 判断当前点的深度并记录颜色
if (z < depthBuffer[y][x]) {
// 更新深度缓存
depthBuffer[y][x] = z;
frameBuffer[y][x] = triangleColor;
}
}
}
}
} 我们发现还缺少深度值插值计算,我们怎么通过三角形的三个顶点插值出中间任意位置的深度值z呢?你可能会想到用上面的重心坐标向插值颜色那样插值深度值(见四、3、节)。但是这个地方直接这么使用却是行不通的。因为深度在映射之后变成了非线性,我们看下图:
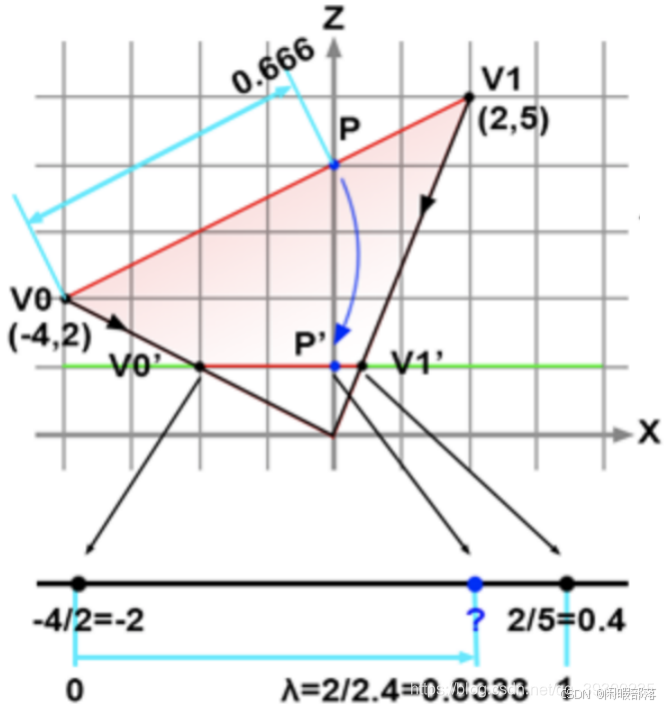
我们设定屏幕到原点的距离为1,且平行于X轴。我们图中 上的点P投影到屏幕的
上的点P投影到屏幕的 。
。 ,而
,而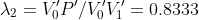 。两者并不相等,因为投影并不能保留距离。所以这里我们便不能直接运用求重心坐标的公式,但是方法还是一致的,只是公式有所改动:
。两者并不相等,因为投影并不能保留距离。所以这里我们便不能直接运用求重心坐标的公式,但是方法还是一致的,只是公式有所改动:
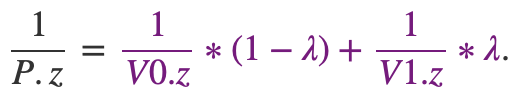
因为我们是在投影之后进行计算,所以这里的 是投影后计算的。公式用简单的相似三角形能推出(这里就不写推倒过程了)。我们带入公式计算:
是投影后计算的。公式用简单的相似三角形能推出(这里就不写推倒过程了)。我们带入公式计算:
![]()
得P.z=4正好符合上图。
4、透视图中正确的顶点属性插值
我们提到在传入顶点属性的时候可以传入颜色值和纹理坐标值,OpenGL在底层帮我们插值。颜色插值公式:
![]()
纹理坐标插值公式:
![]()
我们都可以用重心坐标去计算,但是我们的三角形通过投影后会产生形变,会出现这种情况:
在投影之后,由于不保留距离,直接获取的会出错:
由于我们从右下角往上看,右图才是我们想要的。而左图则还是位于中心点与实际不符。找到正确的解决方案并不难。 假设我们有一个三角形,在三角形的每一侧都有两个z坐标Z0和Z1,如下图所示:
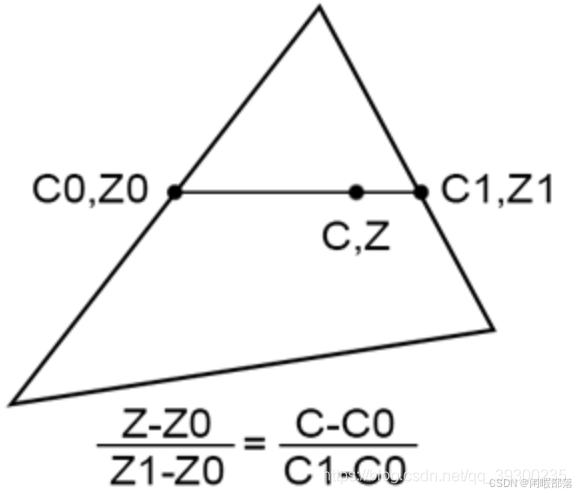
如果我们连接这两个点,则可以使用线性插值对这条线上的点的z坐标进行插值。 我们可以通过在三角形上分别比Z0和Z1相同的位置定义两个顶点属性C0和C1的值来执行相同的操作。 从技术上讲,由于Z和C都是使用线性插值计算的,因此我们可以编写以下等式:
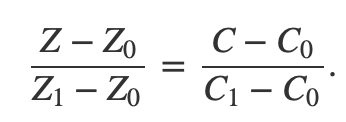
根据前面深度插值公式:
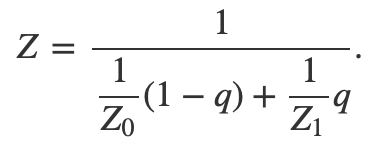
带入得:
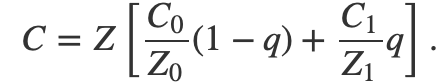
我们利用这个知识点完成一个程序,代码如下:
// 编译:
// c++ -o raster3d raster3d.cpp 对于无使用投影矫正
// c++ -o raster3d raster3d.cpp -D PERSP_CORRECT 使用投影矫正
#include <cstdio>
#include <cstdlib>
#include <fstream>
typedef float Vec2[2];
typedef float Vec3[3];
typedef unsigned char Rgb[3];
inline
float edgeFunction(const Vec3 &a, const Vec3 &b, const Vec3 &c)
{ return (c[0] - a[0]) * (b[1] - a[1]) - (c[1] - a[1]) * (b[0] - a[0]); }
int main(int argc, char **argv)
{
Vec3 v2 = { -48, -10, 82};
Vec3 v1 = { 29, -15, 44};
Vec3 v0 = { 13, 34, 114};
Vec3 c2 = {1, 0, 0};
Vec3 c1 = {0, 1, 0};
Vec3 c0 = {0, 0, 1};
const uint32_t w = 512;
const uint32_t h = 512;
// 简单投影至屏幕
v0[0] /= v0[2], v0[1] /= v0[2];
v1[0] /= v1[2], v1[1] /= v1[2];
v2[0] /= v2[2], v2[1] /= v2[2];
// 转换至DNC坐标空间
v0[0] = (1 + v0[0]) * 0.5 * w, v0[1] = (1 + v0[1]) * 0.5 * h;
v1[0] = (1 + v1[0]) * 0.5 * w, v1[1] = (1 + v1[1]) * 0.5 * h;
v2[0] = (1 + v2[0]) * 0.5 * w, v2[1] = (1 + v2[1]) * 0.5 * h;
#ifdef PERSP_CORRECT
// 投影矫正
c0[0] /= v0[2], c0[1] /= v0[2], c0[2] /= v0[2];
c1[0] /= v1[2], c1[1] /= v1[2], c1[2] /= v1[2];
c2[0] /= v2[2], c2[1] /= v2[2], c2[2] /= v2[2];
// 与计算1/z
v0[2] = 1 / v0[2], v1[2] = 1 / v1[2], v2[2] = 1 / v2[2];
#endif
Rgb *framebuffer = new Rgb[w * h];
memset(framebuffer, 0x0, w * h * 3);
float area = edgeFunction(v0, v1, v2);
for (uint32_t j = 0; j < h; ++j) {
for (uint32_t i = 0; i < w; ++i) {
Vec3 p = {i + 0.5, h - j + 0.5, 0};
float w0 = edgeFunction(v1, v2, p);
float w1 = edgeFunction(v2, v0, p);
float w2 = edgeFunction(v0, v1, p);
if (w0 >= 0 && w1 >= 0 && w2 >= 0) {
w0 /= area;
w1 /= area;
w2 /= area;
float r = w0 * c0[0] + w1 * c1[0] + w2 * c2[0];
float g = w0 * c0[1] + w1 * c1[1] + w2 * c2[1];
float b = w0 * c0[2] + w1 * c1[2] + w2 * c2[2];
#ifdef PERSP_CORRECT //投影矫正
float z = 1 / (w0 * v0[2] + w1 * v1[2] + w2 * v2[2]);
r *= z, g *= z, b *= z;
#endif
framebuffer[j * w + i][0] = (unsigned char)(r * 255);
framebuffer[j * w + i][1] = (unsigned char)(g * 255);
framebuffer[j * w + i][2] = (unsigned char)(b * 255);
}
}
}
std::ofstream ofs;
ofs.open("./raster2d.ppm");
ofs << "P6\n" << w << " " << h << "\n255\n";
ofs.write((char*)framebuffer, w * h * 3);
ofs.close();
delete [] framebuffer;
return 0;
} 该程序运行可以对比我们是否启用投影矫正产生的结果。
四、如何渲染三角形
请记住,绘制三角形(因为三角形是基元,我们将在本例中使用它)是一个两步问题:
- 我们首先需要找到哪些像素与三角形重叠。
- 然后,我们需要定义与三角形重叠的像素应设置为哪种颜色,这个过程称为着色
光栅化阶段主要涉及第一步。 我们说本质上而不是排他的原因是,在光栅化阶段,我们还将计算称为重心坐标(barycentric coordinates)的东西,在某种程度上,它在第二步中使用。
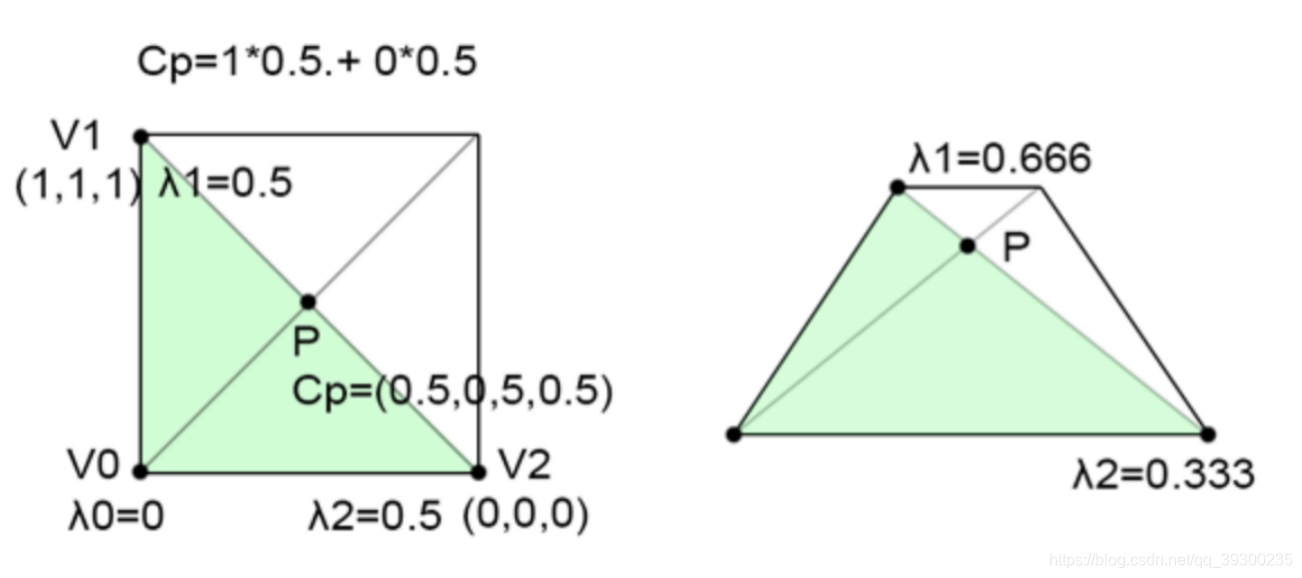
1.重心坐标
在进一步介绍之前,我们先了解重心坐标是什么。首先,它们是一组三个浮点数,在本课中,我们将分别表示 ,
, 和
和 。可以通过以下方式使用坐标定义三角形上的任何点:
。可以通过以下方式使用坐标定义三角形上的任何点:
![]()
通常,V0,V1和V2是三角形的顶点。 这些坐标可以取任何值。而对于三角形内部(或其边缘之一)上的点。,和只能在[0,1]范围内,并且总和等于1。 也就是说:
![]()
这是一种插值形式。有时也将它们定义为三角形顶点的权重。插值三角形的顶点以找到三角形内部的点的位置并没有太大用处。但是,该方法还可以用于在三角形的表面上插值在三角形顶点处定义的任何数量或变量。假设您在三角形的每个顶点上定义了一种颜色。假设V0为红色,V1为绿色,V2为蓝色。如下图:
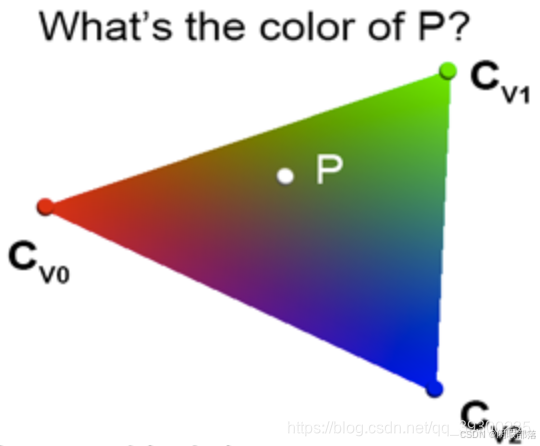
您想要做的是找到如何在三角形的表面上插入这三种颜色。如果知道三角形上的点P的重心坐标,则其颜色CP(三角形顶点颜色的组合)定义为:
![]()
这是一种非常方便的技术,它将对渲染三角形有用。与三角形的顶点关联的数据称为顶点属性。这是CG中非常普遍且非常重要的技术。最常见的顶点属性是颜色,法线和纹理坐标。实际上,这意味着在定义三角形时,不仅将三角形的顶点传递给渲染器,而且将其相关的顶点属性传递给渲染器。例如,如果要渲染三角形,则可能需要颜色和法线顶点属性,这意味着每个三角形将由3个点(三角形顶点位置),3个颜色(三角形顶点的颜色)和3个法线定义(三角形顶点的法线)。法线也可以在三角形的表面内插。插值法线用于一种称为“平滑着色”的技术,该技术最早由Henri Gouraud引入。这里我们先不介绍。
2.如何计算重心坐标
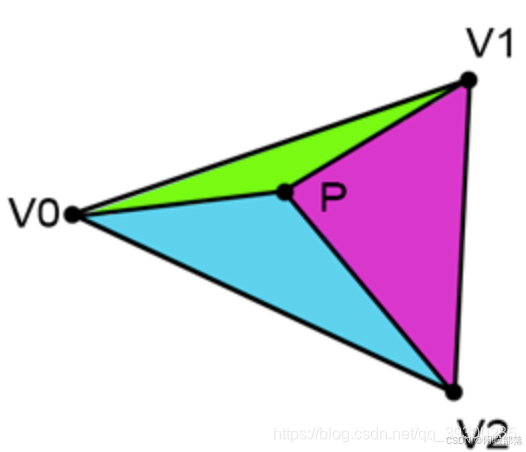
如果点P在三角形内,那么通过查看下图可以看到,我们可以绘制三个子三角形:V0-V1-P(绿色),V1-V2-P(洋红色)和V2-V0- P(青色)。 很明显,这三个子三角形的面积之和等于三角形V0-V1-V2的面积:
即:

而我们刚才的边缘函数:
![]()
正好是三角形面积的两倍。即:

那么我们可以直接用边缘函数求解重心坐标:

我们来看一下计算重心坐标的代码:
float edgeFunction(const Vec2f &a, const Vec3f &b, const Vec2f &c)
{
return (c.x - a.x) * (b.y - a.y) - (c.y - a.y) * (b.x - a.x);
}
float area = edgeFunction(v0, v1, v2); // 三角形的面积(在乘上2,下面三个都是)
float w0 = edgeFunction(v1, v2, p); // 三角形v1v2p的面积
float w1 = edgeFunction(v2, v0, p); // 三角形v2v0p的面积
float w2 = edgeFunction(v0, v1, p); // 三角形v0v1p的面积
// 判断点是否在三角形内
if (w0 >= 0 && w1 >= 0 && w2 >= 0) {
// 计算重心坐标
w0 /= area;
w1 /= area;
w2 /= area;
} 3.重心坐标应用举例——用插值法对像素着色
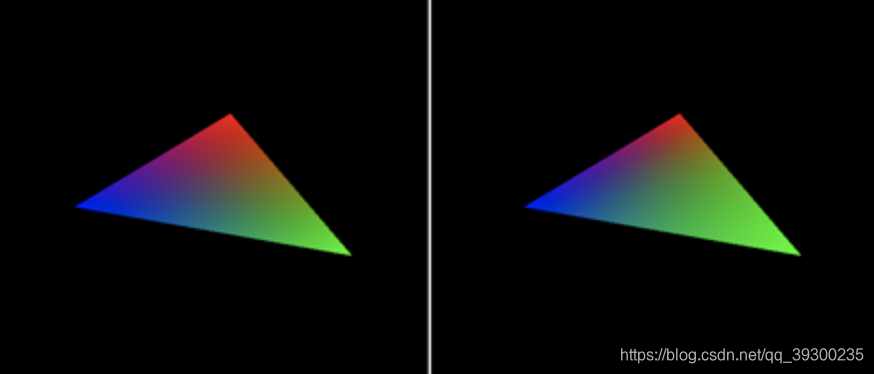
让我们在生成实际图像的程序中测试本章中学到的不同技术。 假设我们已经投影了三角形(查看本课的最后一章以了解光栅化算法的完整实现)。 我们还将为三角形的每个顶点分配一种颜色。 以下是图像的形成方式。 我们将循环图像中的所有像素,并使用边缘函数方法测试它们是否与三角形重叠。 三角形的所有三个边都根据像素的当前位置进行测试,如果边缘函数为所有边返回正数,则像素与三角形重叠。 然后,我们可以计算像素的重心坐标,并通过对三角形每个顶点定义的颜色进行插值,使用这些坐标来对像素进行着色。 帧缓冲区的结果保存到 PPM 文件(您可以使用 Photoshop 读取该文件)。该程序为:
#include <cstdio>
#include <cstdlib>
#include <fstream>
typedef float Vec2[2];
typedef float Vec3[3];
typedef unsigned char Rgb[3];
inline
float edgeFunction(const Vec2 &a, const Vec2 &b, const Vec2 &c)
{ return (c[0] - a[0]) * (b[1] - a[1]) - (c[1] - a[1]) * (b[0] - a[0]); }
int main(int argc, char **argv)
{
Vec2 v0 = {491.407, 411.407};
Vec2 v1 = {148.593, 68.5928};
Vec2 v2 = {148.593, 411.407};
Vec3 c0 = {1, 0, 0};
Vec3 c1 = {0, 1, 0};
Vec3 c2 = {0, 0, 1};
const uint32_t w = 512;
const uint32_t h = 512;
Rgb *framebuffer = new Rgb[w * h];
memset(framebuffer, 0x0, w * h * 3);
float area = edgeFunction(v0, v1, v2);
for (uint32_t j = 0; j < h; ++j) {
for (uint32_t i = 0; i < w; ++i) {
Vec2 p = {i + 0.5f, j + 0.5f};
float w0 = edgeFunction(v1, v2, p);
float w1 = edgeFunction(v2, v0, p);
float w2 = edgeFunction(v0, v1, p);
if (w0 >= 0 && w1 >= 0 && w2 >= 0) {
w0 /= area;
w1 /= area;
w2 /= area;
float r = w0 * c0[0] + w1 * c1[0] + w2 * c2[0];
float g = w0 * c0[1] + w1 * c1[1] + w2 * c2[1];
float b = w0 * c0[2] + w1 * c1[2] + w2 * c2[2];
framebuffer[j * w + i][0] = (unsigned char)(r * 255);
framebuffer[j * w + i][1] = (unsigned char)(g * 255);
framebuffer[j * w + i][2] = (unsigned char)(b * 255);
}
}
}
std::ofstream ofs;
ofs.open("./raster2d.ppm");
ofs << "P6\n" << w << " " << h << "\n255\n";
ofs.write((char*)framebuffer, w * h * 3);
ofs.close();
delete [] framebuffer;
return 0;
} 程序结果为:(使用重心坐标进行顶点属性线性插值的示例)
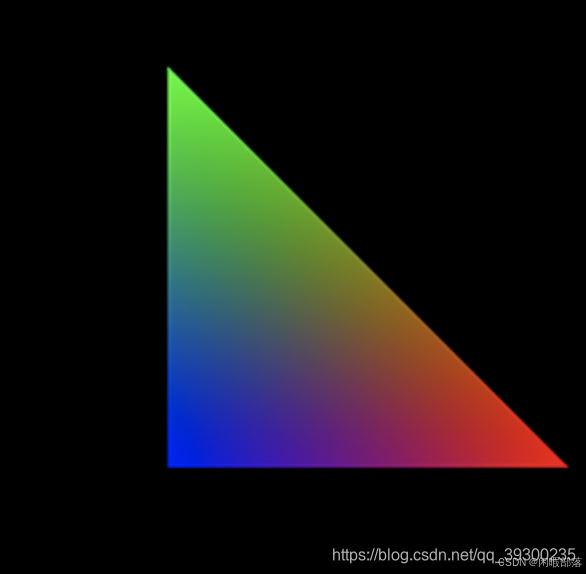
这和我们在OpenGL中渲染的效果几乎一模一样。
五、渲染管线处理流程
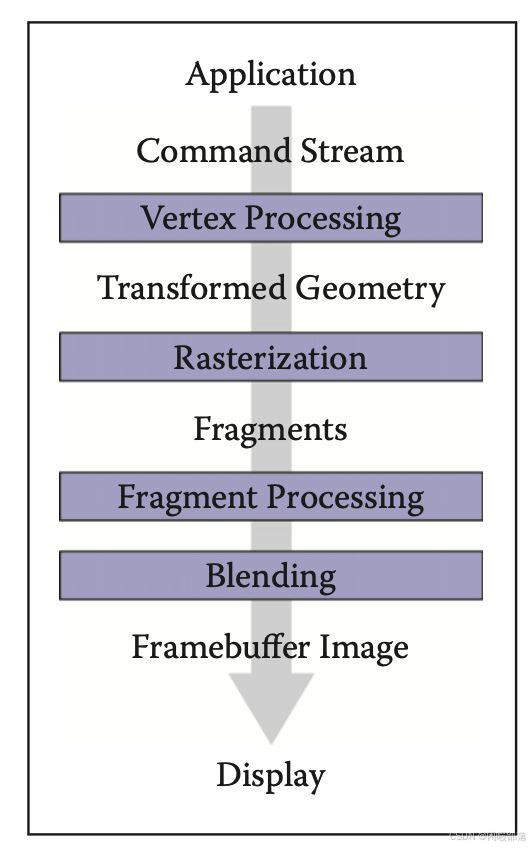
上图是图形管线的主要过程,对照上文例子中的简单模型阐述各个环节工作:
- Vertex Processing: 顶点处理,对空间中顶点进行变换,针对我们例子中简化的两个三角形模型,透视投影包含在顶点变换中。
- Rasterization: 光栅化操作,对于我们这个例子就是对两个三角形做透视投影 --> 然后向[x, y]平面做投影 --> 视口变换,然后判定投影后的三角形内包含了多少像素。
- Fragment Processing: 像素着色,例子中就是针对投影后两个三角形内的像素进行着色,这里与光照、纹理映射相关,对于三角形任一点的纹理坐标、法向量可以通过三角形顶点的这些信息及三角形重心坐标(透视投影前)计算得到。
- Blending: 混合上屏,将最终混合结果填充到图形缓冲区,进而刷到屏幕。
六、未来发展趋势与挑战
光栅化技术在现代计算机图形学中已经扮演着关键角色,但是随着技术的不断发展,光栅化面临着一些挑战。
- 高效渲染:随着显示设备的提高分辨率,光栅化算法需要处理的像素数量越来越多,这将对算法的性能产生挑战。因此,未来的研究趋势将会倾向于提高光栅化算法的性能,例如通过并行处理、硬件加速等方法。
- 虚拟现实和增强现实:虚拟现实和增强现实技术的发展将需要更高质量的图形渲染,这将对光栅化算法的要求更高。未来的研究趋势将会倾向于提高光栅化算法的图像质量,例如通过更复杂的光照计算、纹理映射等方法。
- 机器学习和人工智能:机器学习和人工智能技术的发展将对计算机图形学产生深远影响。未来的研究趋势将会倾向于将机器学习和人工智能技术应用于光栅化算法,例如通过自动优化光栅化参数、生成更真实的物体表面等方法。
参考文章
3D渲染——光栅化渲染原理解析|向量|三角形|3d渲染_网易订阅
https://www.zhihu.com/question/29163054/answer/2298413553
4、计算机图形学——光栅化、抗锯齿、画家算法和深度缓冲算法(Z-buffer)_计算机图形学画家算法-优快云博客
光栅化:将三维图形转换为二维图像-优快云博客
计算机图形学】【GAMES101学习笔记】Rasterization 光栅化_图形光栅化-优快云博客
https://www.zhihu.com/question/29163054/answer/2298413553
3D渲染——光栅化渲染原理解析|向量|三角形|3d渲染_网易订阅



















 1144
1144

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











