







======文件操作=
# 一,文件介绍:文件分为:文本文件,二进制文件
# 1.文件:就是数据存放的容器
# 2.文件的作用:可以持久性的存储数据内容(如果想在电脑上存储一个字符串,那必须要把字符串存放到一个文件中,否则无法存储)
# 3.文件的组成:1)文件名;2)扩展名;3)文件内容
# 二,文件的使用流程:1)打开;2)读写;3)关闭
# 1)打开文件:其实就是通过一个管道,怼到文件上,并打开,进行读写,然后再关闭,这个管道,称之为“文件句柄”,
# 一般通过open()函数插上一个管子来打开这个文件,open()函数参数,主要使用前两个file,mode
# 相对路径,相对于哪一个目录下面的指定文件(a.txt是相对于当前“python文件操作.py”文件的同级目录的位置)
# open()函数的返回值就是一个文件的对象,即是管道
# r模式,只读模式,如果文件不存在,读取时会报错,文件不存在;如果是r模式,执行写操作时会报错,提示文件不可写;只能是只读的方式;读取的指针在文件的开头
# w模式,只写模式,如果文件不存在,会创建新的文件;w模式打开时,指针放在文件的开头,会覆盖删除原来文件的全部内容; w模式,执行读取时会报错,不支持读操作
# a模式,类似w模式,追加只写模式;文件不存在时会创建新的文件;只能写入,不能读取,如果读取会报错,不可读;打开文件后指针放在文件内容的末尾;执行写操作时,
# 会在文件内容最后追加
# 增加b: rb,wb,ab: 是以二进制格式进行操作文件读写;如果文件是二进制文件,则选择此模式,如图片,视频,音频等
# 增加+:r+, w+, a+, rb+, wb+, ab+模式,代表都是以“读写”模式进行打开
# f = open("a.txt", "r")
# f = open("a.txt", "w")
# f = open("a.txt", "a")
f = open("a.txt", "r+") # r+模式,可以读写,如果没有文件会报错,如果read()和write()函数连续操作,写的内容会追加在内容最后,如
# 果只写操作,会把文件的内容从最前面进行部分覆盖,
# 2)读写操作
# content = f.read()
# print(content)
f.write("123")
# 3)关闭文件
f.close()
# rb,wb,ab的操作案例:
# 1.rb读取二进制文件
# 1.1.打开二进制文件
# fromFile = open("xx.jpg","rb")
#
# # 1.2.读二进制文件
# fileContent = fromFile.read()
# print(fileContent)
#
# # 1.3.关闭二进制文件
# fromFile.close()
#
# # 2.wb写入二进制文件, 将图片xx.jpg的内容的前半部分写入到xx2.jpg中
# # 2.1 打开二进制文件
# toFile = open("xx2.jpg", "wb")
#
# # 2.2 写入二进制文件
# content = fileContent[0:len(fileContent) // 2] # fileContent[0: len(fileContent) // 2]是对xx.jpg的内容进行分片处理,只要前半部分
# toFile.write(content)
#
# # 2.3 关闭二进制文件
# toFile.close()

# # 2.wb写入二进制文件, 将图片xx.jpg的内容的前半部分写入到xx2.jpg中
# # 2.1 打开二进制文件
# toFile = open("xx2.jpg", "wb")
#
# # 2.2 写入二进制文件
# content = fileContent[0:len(fileContent) // 2] # fileContent[0: len(fileContent) // 2]是对xx.jpg的内容进行“切片”处理,只要前半部分
# toFile.write(content)
#
# # 2.3 关闭二进制文件
# toFile.close()
# =========2)文件读写
# ====2.1)文件读
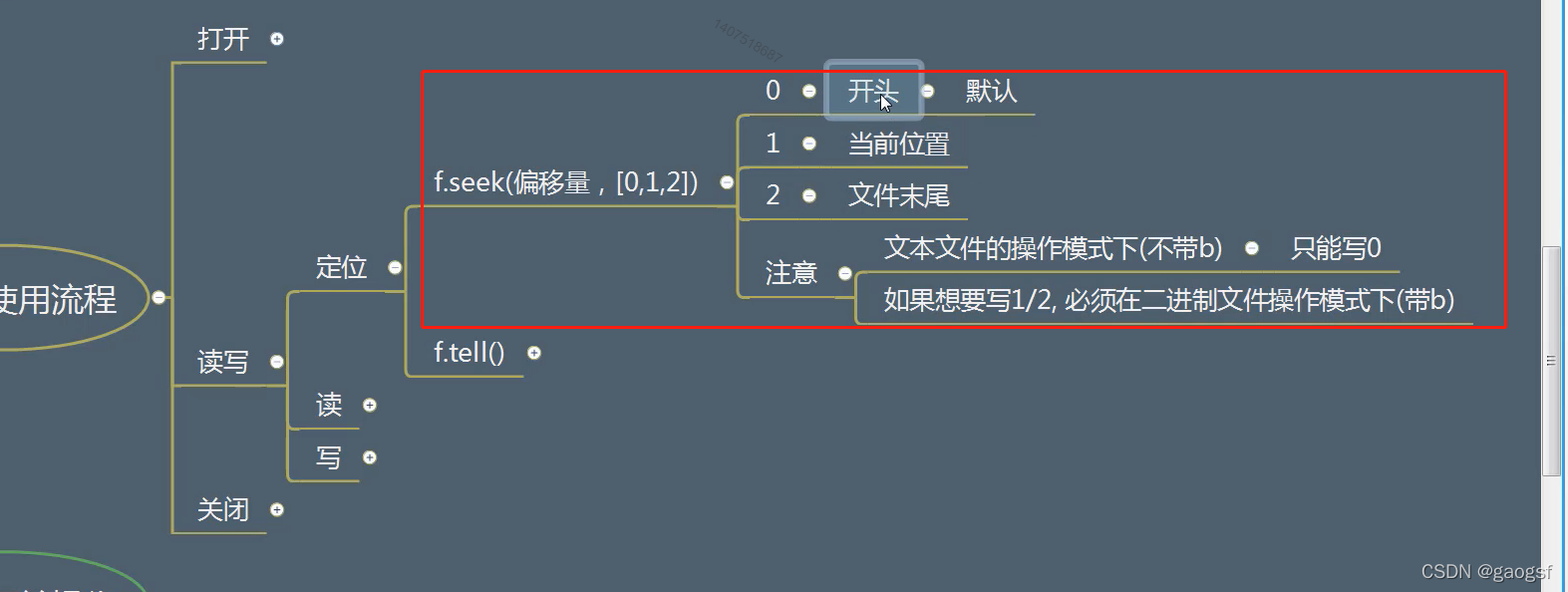
# 2.1文件定位,f.seek(self,offset, whence),一般传入2个参数,一个是offset偏移量,whence是从何处;
# 如果是文本文件,那whence必须是0,如果是二进制文件,才可以为1或2;
# 0代表是文件的开始位置,默认值是0,可以不输入,1代表是二进制文件的当前位置,2代表二进制文件的末尾位置
# 打开文件
# f = open(file="a.txt", mode="r")
# 读写文件
# print("偏移前的位置:",f.tell()) # f.tell()函数是告诉我当前指针的位置
# f.seek(6) # f.seek()函数是让当前指针偏移几个位置
# print("偏移后的位置:",f.tell())
# print(f.read()) # f.read([n])函数读取文件的所有内容, n是读取的字节长度
# print("读取后的位置:",f.tell())
# content = f.readline(10) # f.readline([limit])读取文件的一行,limit是读取一行的限制的最大字节数
# print(content)
# content = f.readlines() # f.readlines()会自动的将文件按换行符进行处理,将处理好的每一行组成一个列表返回,可以通过for循环遍历
# print(content)
# for in 遍历:可以遍历文件对象f,也可以遍历readlines()返回的行列表
# 1.for in 遍历文件对象f,f是个可以迭代的对象
# f = open("a.txt", "r")
# for i in f:
# print(i, end="")
# 2.for in 遍历文件readlines()的行列表:
import collections
# f = open("a.txt", "r")
# print(isinstance(f, collections.Iterator)) # instance(o, Iterator)函数判断一个对象是不是属于某一个类的
# listContent = f.readlines()
# print(listContent)
# for i in listContent:
# print(i, end="")
# 3.判读文件是否可读
# f = open("a.txt", "r")
# if f.readable():
# content = f.readlines()
# print(content)
# # 关闭文件
# f.close()
# 总结注意:
# ->1.一般文件特别大的时候,可以使用readline(),或者for in方便读取文件:按行加载,可以省内存;但相比其他两个方法性能较低;
# ->2.如果文件不是特别大,可以用read()或readlines()方法,一次性读取所有内容:虽然占内存,但处理性能比较高;
# ====2.2)文件写: f.write("内容"),此函数返回写入内容的长度
# f = open("a.txt", "a+")
# # 文件读写,容错处理
# if f.writable():
# len_content = f.write("ni hao4444444444")
# print(len_content)
#
# if f.readable():
# print(f.tell())
# len_read = f.read()
# f.seek(len(len_read) /2) # len()函数可以对读取文件的内容做长度计算,而不能对文件对象做长度计算;
# print(f.read())
#
# f.close()
# ==========3)文件关闭
# 关闭文件:f.close(), 可以释放系统资源,会立即清空缓冲区的数据内容到磁盘文件
# 补充:f.flush(),是立即清空缓冲区的内容,并写到文件中去
# f = open("a.txt", "w")
# f.write("abc")
# f.flush()
# f.close()
# ==========4)其他操作, 模块 import os, 操作,这些操作都在os的模块里面
# 1)文件重命名
import os
# os.rename("b.txt", "bb.txt") # os.rename(src, dst)修改文件的名称,# os.rename(old, new) 修改单级目录/文件名称
# os.rename("one", "first") # os.rename(src, dst)修改文件路径的名称
# os.renames("two/two.txt", "first/first.txt") # os.renames(old, new) 修改多级目录/文件名称
# 2)文件删除:删除文件,删除目录
# 删除文件,如果文件不存在,删除时会报错“文件不存在”
# os.remove("bb.txt")
# 删除目录:
# os.rmdir("first/first2") # 不能递归删除目录,如果文件夹非空,会报错
# os.removedirs("first/first2") # 可以递归删除目录,如果文件夹非空,会报错
# 3)文件创建目录
# os.mkdir("first") # os.mkdir()只能创建一层目录,不能递归创建目录
# 4)查看改变列举目录
# open("cc.txt", "w")
# # 4.1 获取当前目录:os.getcwd()
# print(os.getcwd())
# 4.2 改变默认目录: os.chdir("目标目录")
# os.chdir("first")
# open("dd.txt", "w")
# 4.3 获取目录内容列表:os.listdir("./")
# print(os.listdir("./")) # 列举当前目录的内容
# print("=====")
# print(os.listdir("../")) # 列举当前目录上层目录的内容
# =================6.综合案例:
# 1)文件复制,及注意事项
# 案例1:将一个文件复制到另一个副本中
# 步骤:1.先有一个文件,再新建一个问题,读取文件的内容,写入到新的文件中去,关闭文件
# src_file = open("a.txt", "r")
# dst_file = open("first/c.txt", "a")
# os.chmod(src_file, mode=0o777) # 修改文件的属性,读写执行权限
# os.chmod(dst_file, mode=0o777) # 修改文件的属性,读写执行权限
#
# while True:
# content = src_file.read(1024) # 一次读取1024个字节长度
# if len(content) == 0: # 判断读取的内容长度为0时,代表文件内容读取完毕,跳出循环
# break
# dst_file.write(content)
#
# src_file.close()
# dst_file.close()
# ========================
# 2)文件分类--思路--代码实现
# 将不同后缀名的文件分别放入到指定的目录
# 步骤分解:
# # 0.获取所有的文件列表
# import shutil # shutil包中有可以移动文件的方法,shutil.move(file, folder)
# path = "files"
# if not os.path.exists(path):
# exit()
# os.chdir("files")
# file_list = os.listdir("./")
# # print(file_list)
# # 1.遍历所有的文件
# for file_name in file_list:
# # print(file_name)
# # 2.分解文件的后缀名
# # 2.1 获取最后一个“.”的索引 xx.00.txt
# last_point_index = file_name.rfind(".")
# if last_point_index == -1: # 当没有检索到“.”时会返回-1
# continue
# # print(last_point_index)
# # 2.2 根据这个索引位置,当作起始位置,来截取后续的所有字符串
# extension = file_name[last_point_index + 1:]
# print(extension)
#
# # 3.查看一下,是否存在同名的目录
# # 4.如果不存在这样的目录 -> 直接创建一个这样名称的目录
# if not os.path.exists(extension):
# os.mkdir(extension)
# else: # 5.目录存在 -> 移动过去
# shutil.move(file_name, extension)
# ===================================
# 3)列表清单--代码实现
# 将文件夹中的所有目录和文件全部列举出来, 并将列举的内容信息,写到一个文件中去
import os, shutil
path = "files"
def listFilesToFile(dir, file):
file_list = os.listdir(dir)
for file_name in file_list:
new_file_path = dir + "/" + file_name
if os.path.isdir(new_file_path):
# print(new_file_path)
file.write(new_file_path + "\n")
listFilesToFile(new_file_path, file)
else:
# print("\t" + file_name)
file.write("\t" + file_name + "\n")
print("\n")
f = open("list.txt", "a")
listFilesToFile(path, f)
# 7.基础阶段总结:总结


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









