




 本文深入探讨了Python中的函数,包括无参无返回值、带参数和返回值的函数,以及如何处理不定长参数。介绍了参数的装包与拆包、偏函数、高阶函数、返回函数、匿名函数(lambda)、闭包、装饰器、生成器及其相关方法。此外,还讨论了递归函数和作用域的概念,展示了函数在实际编程中的广泛应用。
本文深入探讨了Python中的函数,包括无参无返回值、带参数和返回值的函数,以及如何处理不定长参数。介绍了参数的装包与拆包、偏函数、高阶函数、返回函数、匿名函数(lambda)、闭包、装饰器、生成器及其相关方法。此外,还讨论了递归函数和作用域的概念,展示了函数在实际编程中的广泛应用。
无参,无返回值函数
def test1():
print("我是无参无返回值函数")
test1()
有参数,无返回值函数: 需要动态的调整函数体中某一个处理信息,则可以以参数的形式接收到相关数据
def test2(num):
print(num ** 1)
print(num ** 2)
print(num ** 3)
test2(3)
有参数,有返回值函数:需要动态的调整函数体中某一个处理信息,则可以以参数的形式接收到相关数据,并且函数执行完成后会返回一个值
def test3(num):
a = num +1
return a
result = test3(4)
print(result)
有参数函数:需要动态调整函数体中多个处理信息时,则可以以逗号做分割,接收多个参数
def test4(num1, num2):
print(num1 + num2)
test4(3,4) # 直接输入实参,形参和实参一一对应
test4(num2=5, num1=4) # 按照关键字传递参数,不是按照参数顺序传递参数的
不定长参数函数,需要在形参前加个“*”,即是元组做参数
def test5(*t):
print(t, type(t))
result = 0
for i in t:
print(i)
result += i
print(result)
test5(1,2,3,4,5)
不定长参数函数,需要在形参前加个“**”,即是类似字典做参数,在调用函数时必须以关键字的形式输入参数
def test6(**kwargs):
print(kwargs, type(kwargs))
test6(name="larry", age=18, sex="男")
参数的拆包和装包
装包:把传递的参数,包装成一个集合,称之为“装包”
def mySum(a,b,c,d):
print(a + b + c + d)
def test7(*args):
# 装包, *args代表是拆包,代表一个一个的数据,args代表是装包,代表是一个整体
print(args)
# 拆包,应该使用一个*用于拆包操作, 不用*用于装包操作
print(*args)
print(args[0],args[1], args[2], args[3])
mySum(*args)
test7(1,2,3,4)
拆包:把集合参数,再次分解成单独的个体,称之为“拆包”
def mySum(a,b,c):
print(a)
print(b)
print(c)
def test8(**kwargs):
# 装包, **kwargs代表是拆包,代表一个一个的数据,kwargs代表是装包,代表是一个整体
print(kwargs)
# 拆包,应该使用两个**用于拆包操作, 不用*用于装包操作
# print(**kwargs) # 不可以直接打印这个**kwargs,要有接收对应的函数和参数
mySum(**kwargs)
test8(a="sz", b=18, c="男") # 调用的时候,也要输入对应的keyword才可以,否则会报错,找不到对应的keyword
# 函数返回值
def test9(a,b):
he = a + b
cha = a - b
return (he, cha)
# res是一个集合
res = test9(4, 5)
# 拆包:
he, cha = test9(4, 5)
print(res)
# res集合拆包
print(res[0], res[1])
print(he, cha)
=======================函数的描述=
# 一般函数的描述,需要说明如下几个信息:函数的功能,参数的含义、类型、是否可以省略、默认值,返回值的含义、类型
def mySum(a, b=1):
"""
计算两个说的和,以及差
:param a: 数值1,数值类型,不可选,没有默认值
:param b: 数值2,数值类型,可选,默认值:1
:return: 返回计算的结果,元组类型:(和,差)
"""
he = a + b
cha = a - b
return (he, cha)
help(mySum)
#------------------------函数的高级用法------------------------
偏函数:当我们写一个参数比较多的函数时,如果有些参数,大部分场景下都是一个固定的值,那么为了简化使用,就可以创建一个新函数,指定我们要使用的函数的某个参数,为某个固定的值,这个新函数就是“偏函数”
import functools
def test10(a,b,c,d=1):
res = a + b + c + d
print(res)
# test10(1,2,3)
#
# # 再定义一个偏函数
# def test11(a,b,c,d=2):
# test10(a,b,c,d)
#
# test11(1,2,3)
# 使用python自带的一个功能,通过functools模块的partial类来创建一个偏函数,不指定参数的值
newFunc = functools.partial(test10, c=5, d=2)
newFunc(1,2) # 这个就是新的偏函数,只要输入两个参数就可以了,其他参数使用默认的固定的值
# 偏函数的使用场景,比如int()函数,int()函数有个参数是base,用于指定使用哪个“进制”进行转换成int整数,将数值字符串以某一个进制进行转换
numStr = "10010"
# 导入functools模块,使用里面的partial方法,指定进制base=xx,然后产生一个偏函数
import functools
intTransfer = functools.partial(int, base=16)
res = intTransfer(numStr)
print(res)
======================高阶函数=
高阶函数,如果一个函数的参数能够接收一个函数,那么这个函数就叫高阶函数
l = [{"name":"sz", "age":18}, {"name":"sz2", "age":19}, {"name":"sz3", "age":18.5}]
# 定义个对于l列表选择什么字段进行排序的函数,这个函数会接收l列表中的每个元素
def getKey(x):
return x["name"]
result = sorted(l, key=getKey, reverse=-1)
print(result)
高阶函数的实例
def caculate(num1, num2, caculateFunc):
result = caculateFunc(num1, num2)
print(result)
def sum(a, b):
return a + b
def jianfa(a, b):
return a - b
caculate(num1=6, num2=2, caculateFunc=jianfa)
======================返回函数=
返回函数:是指一个函数内部,它返回的数据是另外一个函数,把这样的操作成为“返回函数”
案例:根据不同参数,获取不同操作,做不同计算
def getFunc(flag):
# 1.再次定义几个函数
def sum(a, b, c):
return a + b + c
def jian(a, b, c):
return a - b - c
# 2.根据不同的flag的值,来返回不同的操作函数
if flag == "+":
return sum # 返回的是函数sum,而不是调用sum函数,因为没有加()
elif flag == "-":
return jian # 返回的是函数jian,而不是调用jian函数,因为没有加()
backFunc = getFunc("-") # 参数传入flag是“+”,返回的是sum函数,flag是“-”,返回的是jian函数
print(backFunc, type(backFunc))
res = backFunc(1,2,3) # backFunc是个返回函数,那么就可以调用这个函数,并传入参数
print(res)
======================匿名函数=
匿名函数,也称“lambda函数”,顾名思义就是没有名字的函数
newFunc2 = lambda x, y : x + y
res = newFunc2(1,2)
print(res)
l = [{"name":"sz", "age":18}, {"name":"sz2", "age":19}, {"name":"sz3", "age":18.5}]
# 定义个对于l列表选择什么字段进行排序的函数,这个函数会接收l列表中的每个元素
# def getKey(x):
# return x["name"]
result = sorted(l, key=lambda x : x["age"])
print(result)
======================闭包=
在函数嵌套的前提下,内层函数引用了外层函数的变量或参数,外层函数又把内层函数当作返回值进行返回
那么,将 这个内层函数+所引用的外层变量,称为"闭包"
def test11():
a = 10
def test12():
print(a)
return test12
newFunc3 = test11()
newFunc3()
应用场景:外层函数,根据不同的参数,来生成不同作用功能的函数
案例:根据配置信息,生成不同的分割线函数
def line_config(content, length):
def line():
print(("-" * (length // 2)) + content + ("-" * (length // 2)))
return line
newFunc4 = line_config("aaaa", 20)
newFunc4()
newFunc5 = line_config("bbbb", 10)
newFunc5()
通过闭包修改外层函数的变量,必须使用nonlocal关键字
def test13():
num = 1
def test14():
nonlocal num
num = 6
print(num)
print(num)
test14()
print(num)
return test14
newFunc5 = test13()
newFunc5()
闭包注意2:
def test15():
a = 1
def test16():
print(a)
a = 2
return test16
newFunc6 = test15()
newFunc6()
闭包,更加复杂的例子
def test17():
funcs = []
for i in range(1,4):
def test18():
print(i)
funcs.append(test18)
return funcs
newFuncs = test17()
print(newFuncs)
newFuncs0
newFuncs1
newFuncs2
def test17():
funcs = []
for i in range(1,4):
def test18(num):
def inner():
print(num)
return inner
funcs.append(test18(i)) # 这个代表,添加的是返回的inner函数,以及对应i的值
return funcs
newFuncs = test17()
print(newFuncs)
newFuncs[0]()
newFuncs[1]()
newFuncs[2]()
=========================函数装饰器=
作用:在函数名和函数体不改变的前提下,给一个函数附加一些额外代码
案例:发说说,发图片
1.定义两个函数
1.定义两个函数
def checkLogin(func): # 装饰器函数,为了对于fss()和ftp()函数增加一些额外的小功能,可以定义一个装饰器函数
def inner():
print("登录验证...") # 增加额外的功能代码
func() # 传入的函数
return inner # 返回内部函数,此内部函数为传入的函数增加了额外的功能代码
#python的语法糖模式,其实就是设计模式,类似调用了checkLog(func)函数并反应一个内部函数,
# 且此返回的函数名字与踹人的函数名字是一样的
@checkLogin # @checkLogin语法糖,返回一个与下面函数一样的名字的函数,并将此函数额外增加了其他的功能代码
def fss():
print("发说说")
# fss = checkLogin(fss)
#python的语法糖模式,其实就是设计模式,类似调用了checkLog(func)函数并反应一个内部函数,
# 且此返回的函数名字与踹人的函数名字是一样的
@checkLogin # @checkLogin语法糖,返回一个与下面函数一样的名字的函数,并将此函数额外增加了其他的功能代码
def ftp():
print("发图片")
# ftp = checkLogin(ftp)
# 2.相关的逻辑代码
btnIndex = 1
if btnIndex == 1:
fss()
else:
ftp()
总结:需要将功能函数的部分,与业务逻辑代码的部分,进行分开
发说说,发图片,必须有一个前提,就是,用户必须登录之后
登录验证的操作
1.直接在业务逻辑代码里面去修改,添加一个验证操作:弊端如下:
因为业务逻辑代码非常多,所以,就造成了,每一份,逻辑代码,在调用,具体的功能函数之前都需要,去做一个登录验证,
代码冗余度,就比较大,而且代码的复用性比较差,代码的维护性比较差
2.直接在功能函数里面去修改,方便代码的重用: 这样也有一点问题,登录验证的代码重复了
改善方式:再定义一个登录验证的函数checkLogin(),然后在发说说和发图片的函数里面调用checkLogin()的函数即可
==============有参数的装饰器,和不定长度的装饰器=
def zsq(func):
def inner(*args, **kwargs):
print("_" * 30)
res = func(*args, **kwargs)
return res
return inner
@zsq
def pnum1(num1, num2, num3):
print(num1, num2, num3)
return num1 + num2 + num3 # 增加功能函数的返回值,那装饰器也要写成一直的形式
@zsq
def pnum2(num):
print(num)
return num
@zsq
def pnum3(*args, **kwargs):
print(*args, **kwargs)
res1 = pnum1(1,2, num3=666) # 执行这里的pnum1()函数,就是执行inner函数
res2 = pnum2(999) # 执行这里的pnum2()函数,就是执行inner函数
res3 = pnum3(1,2,3,4,5,56,6) # 执行这里的pnum3()函数,就是执行inner函数
print(res1,res2,res3) # 打印查看返回值
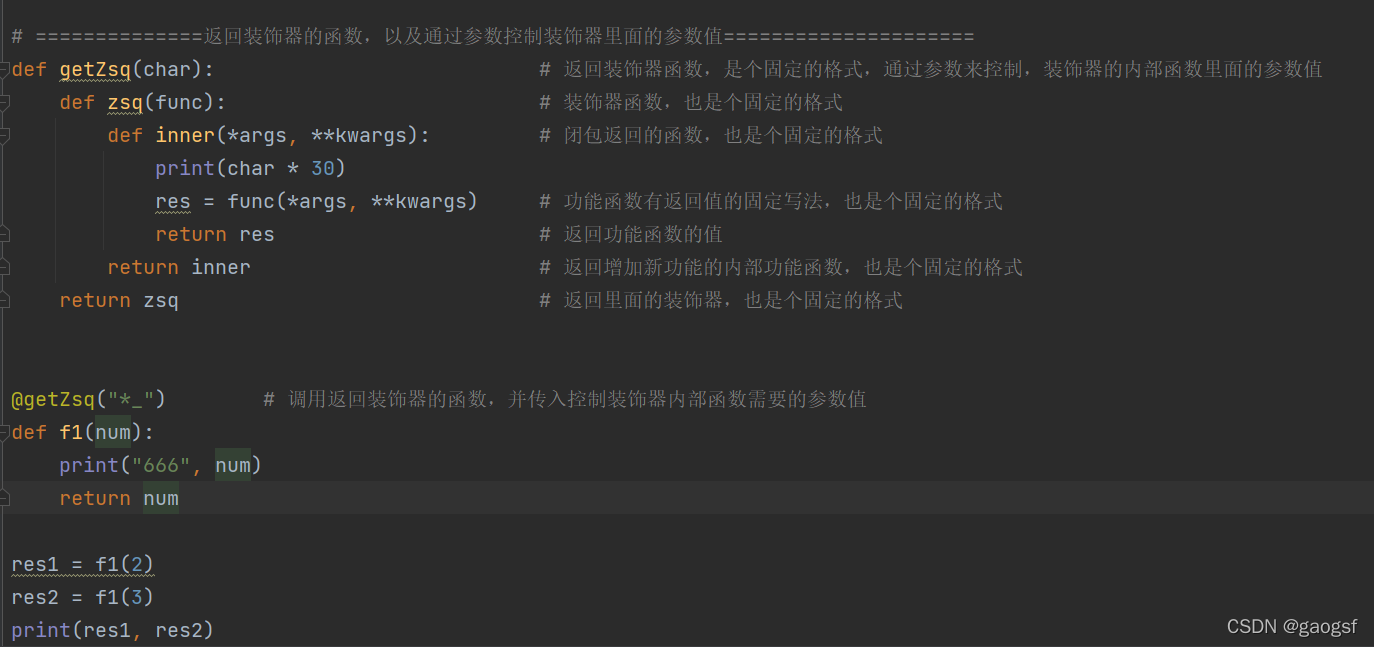
==============返回装饰器的函数,以及通过参数控制装饰器里面的参数值=
def getZsq(char): # 返回装饰器函数,是个固定的格式,通过参数来控制,装饰器的内部函数里面的参数值
def zsq(func): # 装饰器函数,也是个固定的格式
def inner(*args, **kwargs): # 闭包返回的函数,也是个固定的格式
print(char * 30)
res = func(*args, **kwargs) # 功能函数有返回值的固定写法,也是个固定的格式
return res # 返回功能函数的值
return inner # 返回增加新功能的内部功能函数,也是个固定的格式
return zsq # 返回里面的装饰器,也是个固定的格式
@getZsq("*_") # 调用返回装饰器的函数,并传入控制装饰器内部函数需要的参数值
def f1(num):
print("666", num)
return num
res1 = f1(2)
res2 = f1(3)
print(res1, res2)
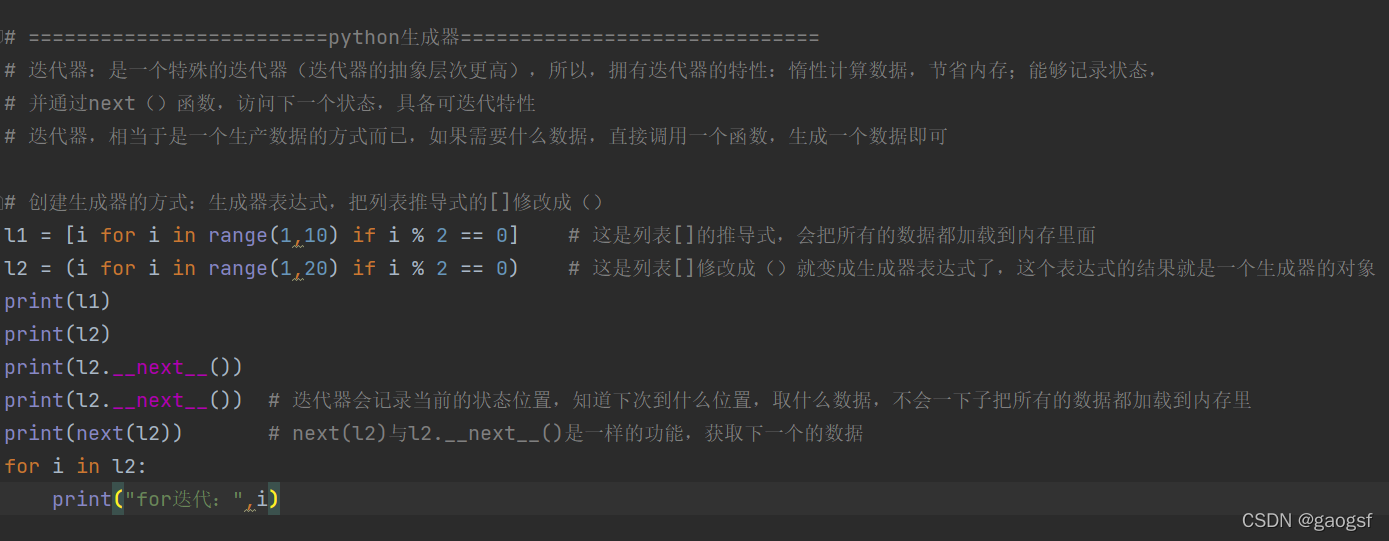
=========================python生成器=
迭代器:是一个特殊的迭代器(迭代器的抽象层次更高),所以,拥有迭代器的特性:惰性计算数据,节省内存;能够记录状态,
并通过next()函数,访问下一个状态,具备可迭代特性
迭代器,相当于是一个生产数据的方式而已,如果需要什么数据,直接调用一个函数,生成一个数据即可
1.创建生成器的方式:生成器表达式,把列表推导式的[]修改成()
l1 = [i for i in range(1,10) if i % 2 == 0] # 这是列表[]的推导式,会把所有的数据都加载到内存里面
l2 = (i for i in range(1,20) if i % 2 == 0) # 这是列表[]修改成()就变成生成器表达式了,这个表达式的结果就是一个生成器的对象
print(l1)
print(l2)
print(l2.__next__())
print(l2.__next__()) # 迭代器会记录当前的状态位置,知道下次到什么位置,取什么数据,不会一下子把所有的数据都加载到内存里
print(next(l2)) # next(l2)与l2.__next__()是一样的功能,获取下一个的数据
for i in l2:
print("for迭代:",i)
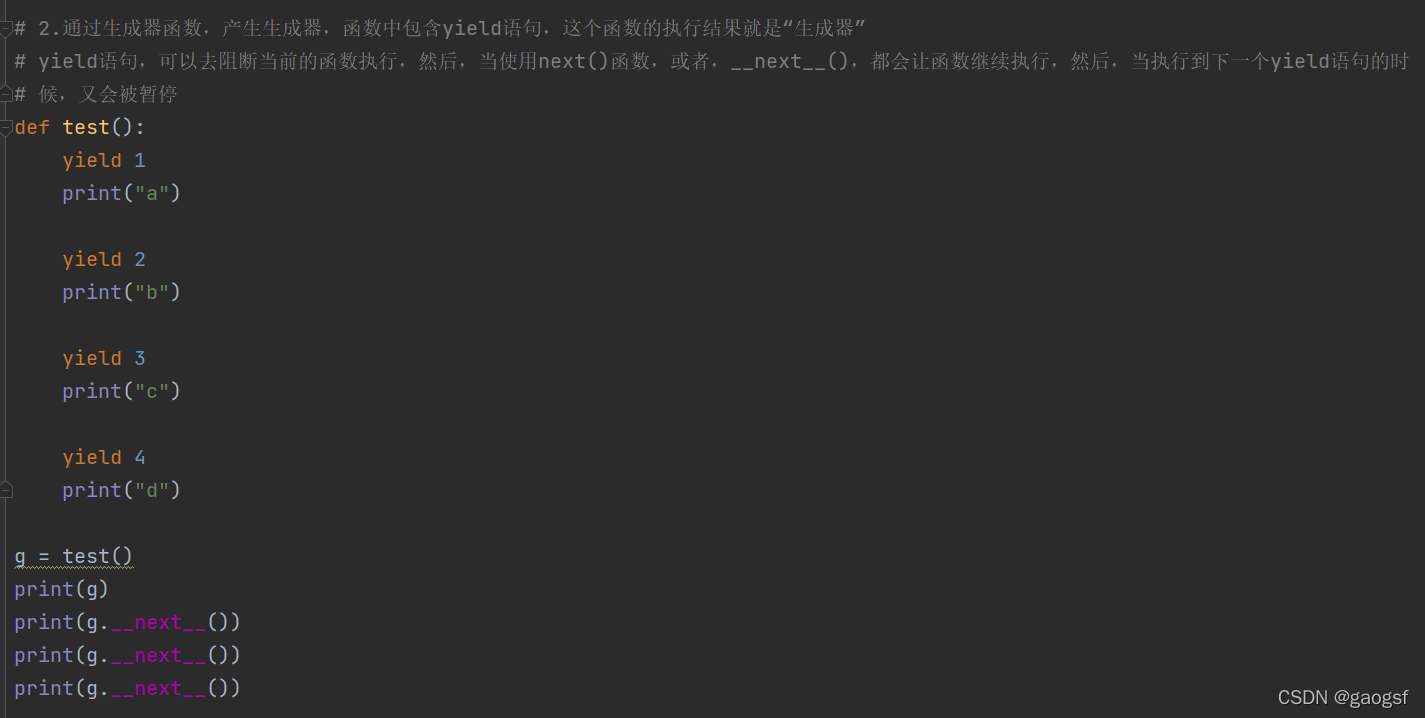
2.通过生成器函数,产生生成器,函数中包含yield语句,这个函数的执行结果就是“生成器”
yield语句,可以去阻断当前的函数执行,然后,当使用next()函数,或者,next(),都会让函数继续执行,然后,当执行到下一个yield语句的时
候,又会被暂停
def test():
yield 1
print("a")
yield 2
print("b")
yield 3
print("c")
yield 4
print("d")
g = test()
print(g)
print(g.__next__())
print(g.__next__())
print(g.__next__())
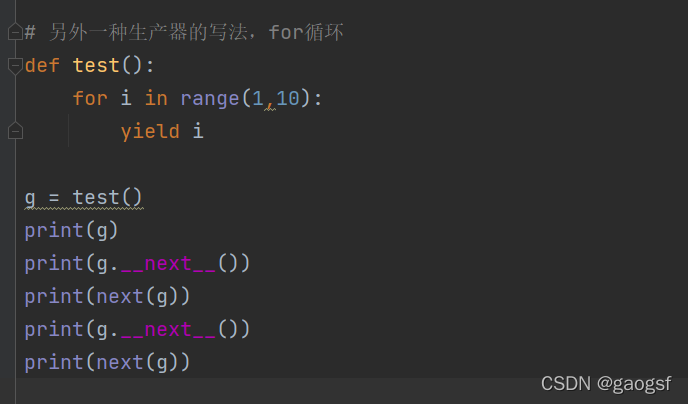
另外一种生产器的写法,for循环
def test():
for i in range(1,10):
yield i
g = test()
print(g)
print(g.__next__())
print(next(g))
print(g.__next__())
print(next(g))
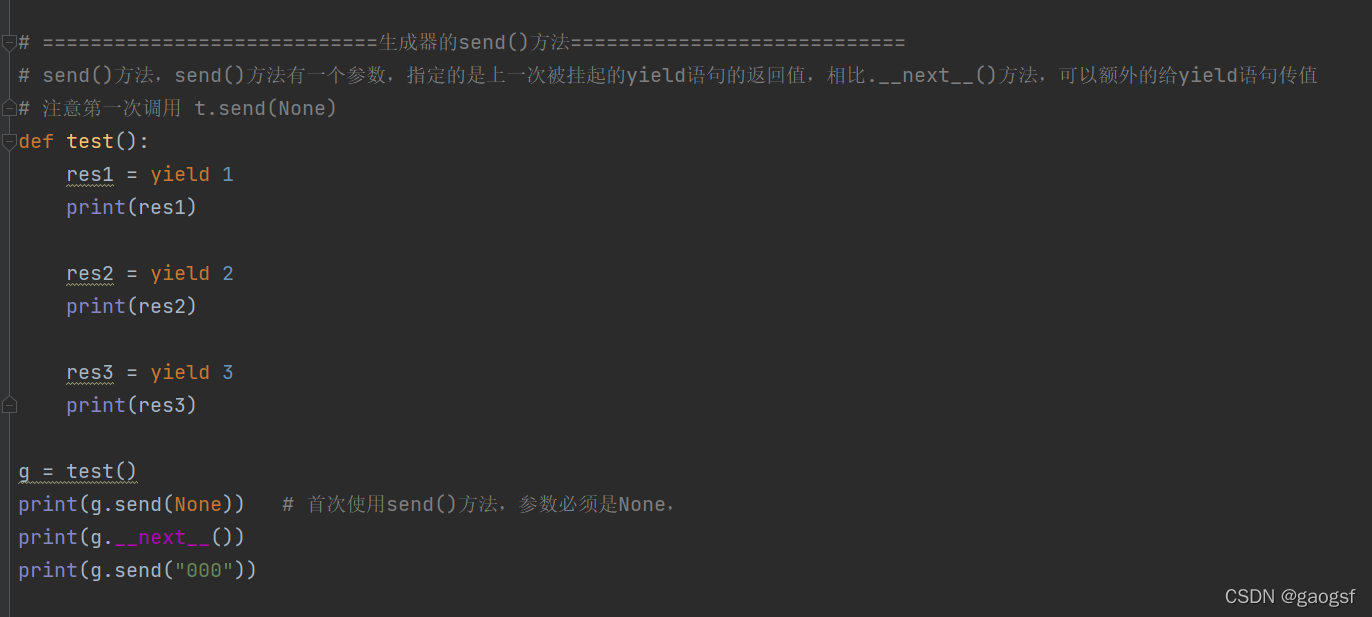
=================生成器的send()方法=
send()方法,send()方法有一个参数,指定的是上一次被挂起的yield语句的返回值,相比.next()方法,可以额外的给yield语句传值
注意第一次调用 t.send(None)
def test():
res1 = yield 1
print(res1)
res2 = yield 2
print(res2)
res3 = yield 3
print(res3)
g = test()
print(g.send(None)) # 首次使用send()方法,参数必须是None,
print(g.__next__())
print(g.send("000"))
==============生成器的关闭=
# 关闭生成器的方法,g.close()
# 先写一个生成器的函数
def test():
yield 1
print("a")
yield 2
print("b")
yield 3
print("c")
# 通过生成器函数,先生成一个生成器g
g = test()
# 下面可以对于生成器g进行操作
print(g.__next__())
print(g.__next__())
g.close() # 通过生产器的close()方法,意思就是将生成器的状态指导生成器的最后,再调用的时候就会报错StopIteration
print(g.__next__())
================生成器的注意事项=
生成器,如果遇到return语句会怎么样,另外能遍历几次
1.生成器,在执行过程中,一旦遇return语句,会立即停止,并报错StopIteration,并输入return后面的值
def test1():
yield 1
print("aa")
# return 10
yield 2
print("bb")
yield 3
print("cc")
# 通过生成器函数,先生成一个生成器g
g = test1()
# 下面可以对于生成器g进行操作
print(g.__next__())
print(g.__next__()) # 当执行这个代码时就会执行return语句了,就会报错StopIteration 并返回 return 后的值
print(g.__next__())
2.生成器值能遍历1次,如果想再遍历,还需要再拿到生成器
def test2():
yield 1
print("aaa")
# return 10
yield 2
print("bbb")
yield 3
print("ccc")
# 通过生成器函数,先生成一个生成器g
g = test2()
for i in g: # for遍历生成器时,能够将生成器里面的最后yield语句下面的代码执行完
print(i)
print("当前执行的位置xxxxxxxx,下面代码不会执行")
for i in g: # 当第二次遍历生成器时就不会执行了,前面的print()函数代表是执行的位置,要想使用还需要
print(i) # 再获取一次生成器
========递归函数=
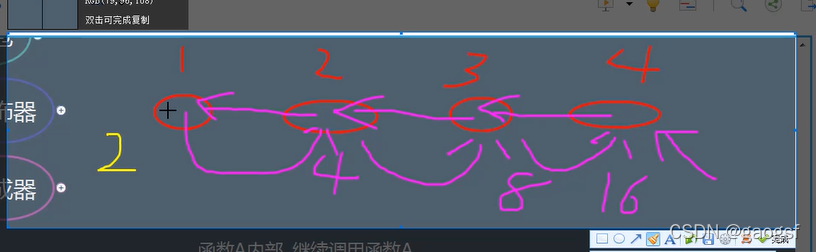

====================递归函数=
递归函数:函数A内部,继续调用函数A
递归函数:先有传递,即询问;后有回归,传递值
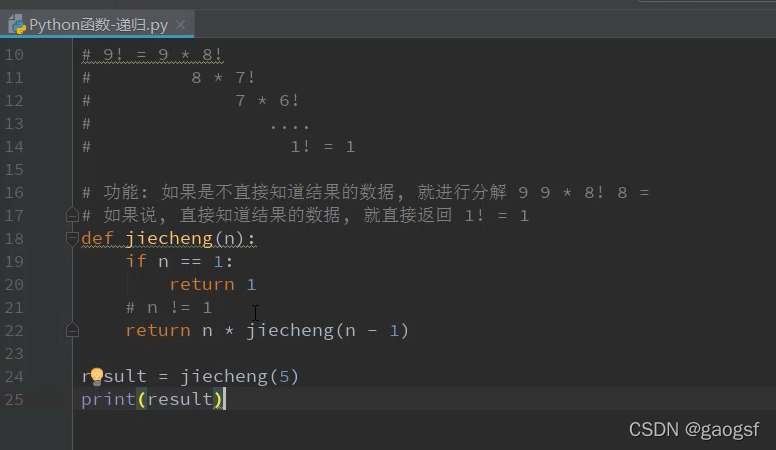
# 案例:求一个数的阶乘,比如9的阶乘:9! = 9 * 8 * 7 * 6 * 5 * .... * 2 * 1
# 功能:如果是不直接知道结果的数据,就进行分解,
def jieCheng(n):
if n == 1: # 这里就是传递结束的位置条件,也是回归的开始位置条件
return 1
# 下面肯定是 n != 1的情况
return n * jieCheng(n-1)
result = jieCheng(3)
print(result)
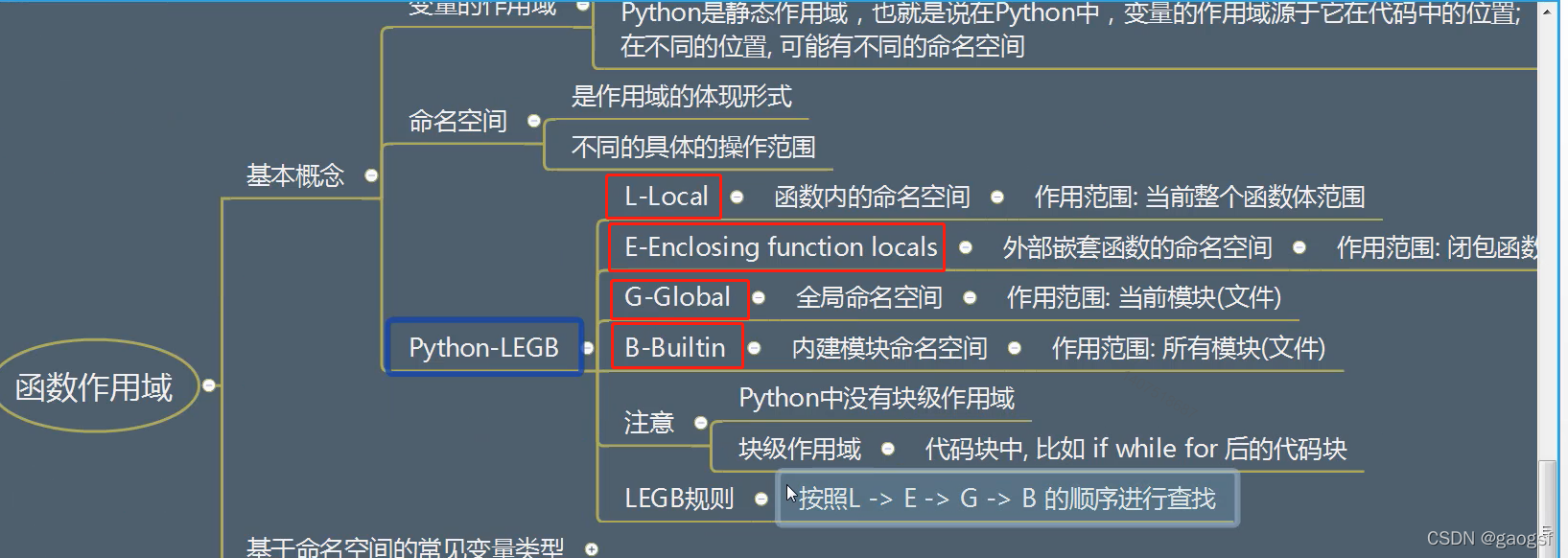
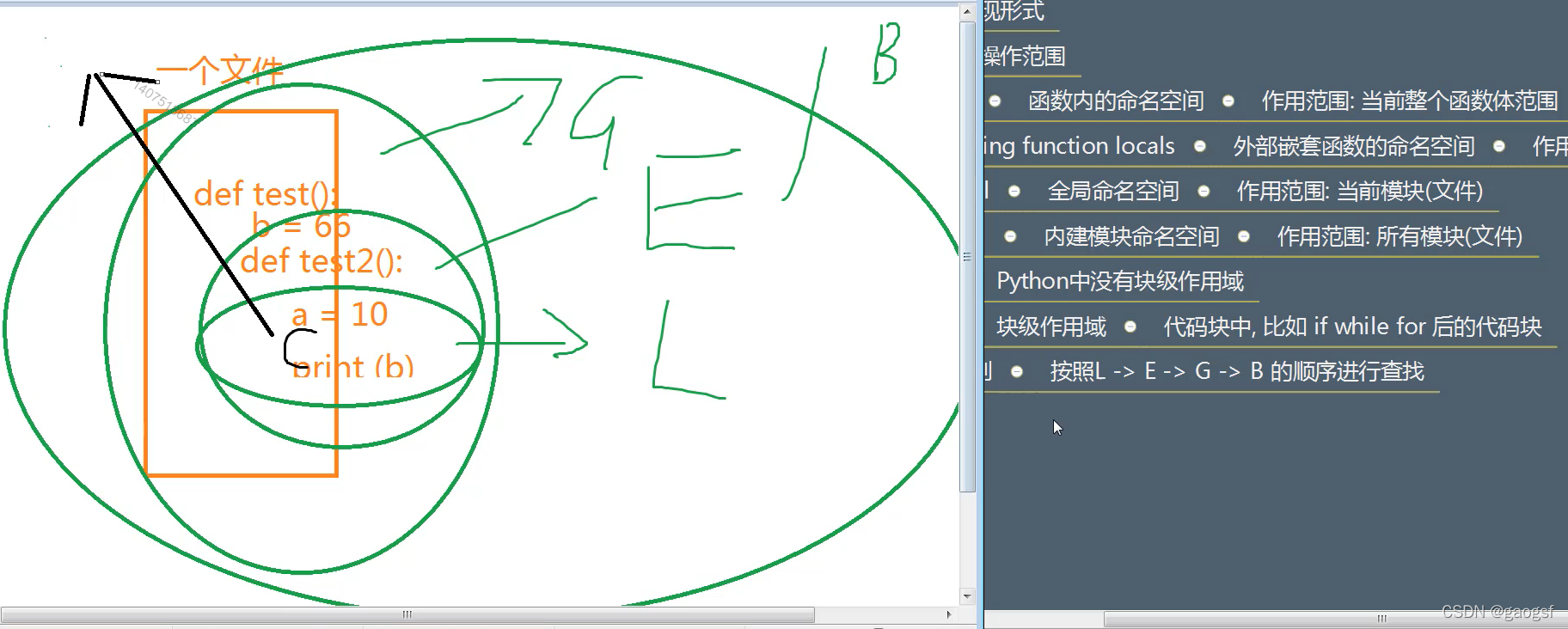
======================函数的作用域=
python不存在块级作用域的,比如if,while等,其他语言是有块级作用域(块外不能访问)
a = 10 # a是G,全局变量,作用域是整个文档内
def test3():
b = 9 # b是E,外部嵌套函数的命名空间
print(b)
def test4():
c = 8 # c是L,局部变量
print(b)
return c
return test4
print(__name__) # __name__是B, python内建变量,每个文件里面都可以使用
print(a)
newFunc = test3()
res = newFunc()
print(res)

















 7568
7568




 到【灌水乐园】发言
到【灌水乐园】发言







