






 本文介绍了如何使用scrapy框架来爬取BOSS直聘网站上的职位数据。首先找到BOSS直聘的接口URL,然后创建scrapy项目,包括spider文件s_boss.py、items.py和pipelines.py。在请求URL时,需要注意设置请求头的USER_AGENT。同时,在items.py中定义数据结构,pipelines.py中配置数据处理流程。
本文介绍了如何使用scrapy框架来爬取BOSS直聘网站上的职位数据。首先找到BOSS直聘的接口URL,然后创建scrapy项目,包括spider文件s_boss.py、items.py和pipelines.py。在请求URL时,需要注意设置请求头的USER_AGENT。同时,在items.py中定义数据结构,pipelines.py中配置数据处理流程。
BOSS直聘:https://www.zhipin.com/
创建scrapy 项目:
scrapy startproject scrapyProject创建spider文件:
scrapy genspider s_boss zhipin.com目录
1.找接口 url
page后面传的是页数
https://www.zhipin.com/c101010100/?query=python&page={}&ka=page-next
2.s_boss.py
# -*- coding: utf-8 -*-
import scrapy
from scrapyProject.items import BossItem
from lxml import etree
class SBossSpider(scrapy.Spider):
name = 's_boss'
allowed_domains = ['zhipin.com']
start_urls = []
for page in range(1, 11):
url = 'https://www.zhipin.com/c101010100/?query=python&page={}&ka=page-next'.format(page)
start_urls.append(url)
def parse(self, response):
content = response.body.decode('utf-8')
tree = etree.HTML(content)
li_list = tree.xpath('//div[@class="job-list"]/ul/li')
print(len(li_list))
for li in li_list:
item = BossItem()
# 职位名称
title = li.xpath('.//a//text()')[1]
# 工资水平
salary = li.xpath('.//span/text()')[0]
# 职位要求
demand = li.xpath('.//div[@class="info-primary"]/p//text()')
demand_info = ' '.join(demand)
# 公司情况
company_name = li.xpath('.//div[@class="info-company"]//h3//text()')[0]
company_info = li.xpath('.//div[@class="info-company"]//p//text()')
company = company_name + ':' + ' '.join(company_info)
item['title'] = title
item['salary'] = salary
item['demand_info'] = demand_info
item['company'] = company
yield item
注意一下:在进行请求url的时候,需要请求头,scrapy框架的请求头需要在settings.py中设置:
在网页上打开network:
找到user_agent:
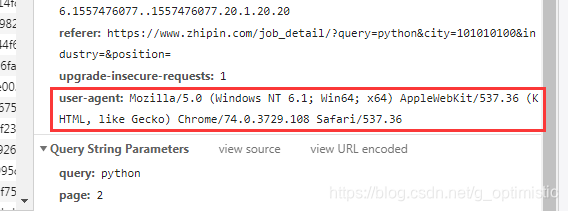
写在settings.py的USER_AGENT

3.items.py
class BossItem(scrapy.Item):
title = scrapy.Field()
salary = scrapy.Field()
demand_info = scrapy.Field()
company = scrapy.Field()4.pipelines.py
class BossPipeline(object):
def process_item(self, item, spider):
fp = open('boss.json', 'a', encoding='utf-8')
json.dump(dict(item), fp, ensure_ascii=False)
# fp.write(item)
return item需要在settings.py中配置pipeline


















 5112
5112

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









