






 本文介绍了如何在Windows平台上使用Scrapy爬虫框架来抓取Boss直聘网站上的职位信息,包括职位、办公地点、工作经验等12项关键数据。通过F12开发者工具分析CSS和XPath选择器,编写Item、Spider并配置settings,最后成功运行爬虫。
本文介绍了如何在Windows平台上使用Scrapy爬虫框架来抓取Boss直聘网站上的职位信息,包括职位、办公地点、工作经验等12项关键数据。通过F12开发者工具分析CSS和XPath选择器,编写Item、Spider并配置settings,最后成功运行爬虫。
一、Windows平台创建项目
scrapy startproject toscrape_book
cd toscrape_book
scrapy genspider books books.toscrape.com
二、需求分析
 |
|
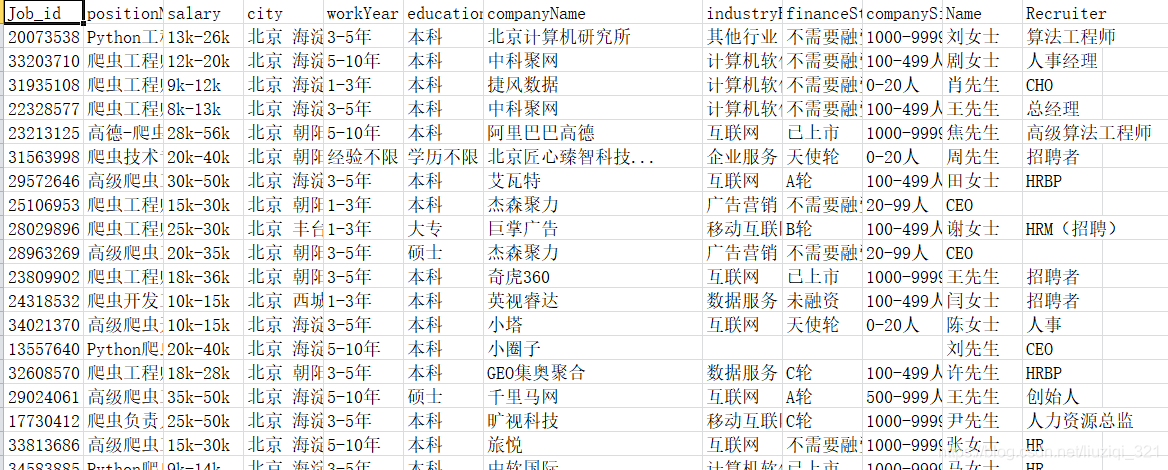
我们爬取页面中每个公司的岗位信息,包括职位、办公地点、工作经验…上图中的11个加上boss直聘的jobid共12个信息
三、信息提取
打开shell
scrapy shell https://www.zhipin.com/job_detail/?query=%E7%88%AC%E8%99%AB&city=101010100&industry=&position=
view(response)
#发现返回403
#尝试把headers一并给出
from scrapy import Request
data = Request('https://www.zhipin.com/job_detail/?query=%E7%88%AC%E8%99%AB&city=101010100&industry=&position=',headers={'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64;x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'})
#下载页面
fetch(data)
view(response)
可以看到本地已经下载了
 |
|
F12大法,CSS、xpath交替查找需要的数据
 |
|
四、编写代码
编写代码定义Item
import scrapy
class WwwZhipinComItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
Job_id= scrapy.Field()
positionName = scrapy.Field()
salary= scrapy.Field()
city= scrapy.Field()
workYear= scrapy.Field()
education= scrapy.Field()
companyName= scrapy.Field()
industryField= scrapy.Field()
financeStage= scrapy.Field()
companySize= scrapy.Field()
Name= scrapy.Field()
Recruiter= scrapy.Field()
编写Spider
import scrapy
from www_zhipin_com.items import WwwZhipinComItem
import time
class ZhipinSpider(scrapy.Spider):
name = 'zhipin'
allowed_domains = ['www.zhipin.com']
start_urls = ['https://www.zhipin.com/c101010100/?query=%E7%88%AC%E8%99%AB']
positionUrl = 'https://www.zhipin.com/c101010100/?query=%E7%88%AC%E8%99%AB'
curPage = 1
# 发送 header,伪装为浏览器
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'}
def start_requests(self):
return [self.next_request()]
def parse(self, response):
print("request -> " + response.url)
job_list = response.css('div.job-list > ul > li')
for job in job_list:
item = WwwZhipinComItem()
job_primary = job.css('div.job-primary')
item['Job_id'] = job.xpath('.//a/@data-jobid').extract_first().strip()
item['city'] = job_primary.xpath('./div/p/text()').extract_first().strip()
item['workYear'] = job_primary.xpath('./div/p/text()[2]').extract_first().strip()
item['education'] = job_primary.xpath('./div/p/text()[3]').extract_first().strip()
item["positionName"] = job_primary.xpath('./div[1]/h3/a/div[1]/text()').extract_first()
item["salary"] = job_primary.xpath('./div[1]/h3/a/span/text()').extract_first()
item['companyName'] = job_primary.css('div.info-company > div.company-text > h3 > a::text').extract_first().strip()
company_infos = job_primary.xpath('./div[2]/div/p/text()').extract()
#main > div > div.job-list > ul > li:nth-child(1)
if len(company_infos) == 3: # 有一条招聘这里只有两项,所以加个判断
item['industryField'] = company_infos[0].strip()
item['financeStage'] = company_infos[1].strip()
item['companySize'] = company_infos[2].strip()
item['Name'] = job_primary.xpath('./div[3]/h3/text()[1]').extract()
item['Recruiter'] = job_primary.xpath('./div[3]/h3/text()[2]').extract()
yield item
self.curPage += 1
time.sleep(5)
yield self.next_request()
# 发送请求
def next_request(self):
return scrapy.http.FormRequest(self.positionUrl + ("&page=%d" %(self.curPage)),headers=self.headers,callback=self.parse)
设置setting
FEED_FORMAT = 'csv'
FEED_EXPORT_ENCODING = 'utf-8'
FEED_EXPORT_FIELDS = ['Job_id','positionName','salary','city','workYear','education','companyName','industryField','financeStage','companySize','Name','Recruiter']
五、运行
scrapy crawl zhipin -o job.csv

















 1880
1880

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









