



CloudNet反恶意软件引擎:面向云服务的GPU加速的网络监控
摘要
在现代物联网(IoT)和信息物理系统(CPSs)应用中,异构嵌入式设备交换大量数据,与云服务的互联日益普及。因此,增强安全性至关重要,但网络监控具有较高的计算开销。利用图形处理单元(GPU)进行并行编程,是显著减少计算密集型领域计算时间的成熟实践。
本文提出CloudNet——一种轻量级且高效的GPU加速反恶意软件引擎,采用CUDA通用目的GPU(GPGPU)技术。该系统核心通过CUDA优化的SHA‐3哈希机制计算文件摘要。恶意软件摘要存储于特定数据结构中,以便在网络流量处理过程中实时进行检测判断。研究工作包括对三种数据结构(哈希表、树和数组)的对比分析,以确定最适合该领域的结构类型。我们开发了两种基本应用的多个版本,并对GPU加速实现与参考及优化的CPU实现进行了性能比较。CloudNet旨在保护向工业云传输信息的信息物理系统。评估过程中采用一段工业风电场流量轨迹数据,结果表明CloudNet的网络监控速度比典型CPU解决方案快两倍。
关键词
云 Industrial云 Network监控 反恶意软件 Parallel 计算 GPU CUDA SHA-3 信息物理系统 IoT IIoT
1 引言
如今,大多数用户都不会忽视保护他们的计算机和笔记本电脑免受各种恶意软件的侵害。然而,在物联网(IoT)和信息物理系统(CPSs)领域的设备上,却并不总是采用同样的防护方法。
这些设备与云 [1, 2] 交换信息。因此,恶意实体可能找到攻击这些防护较弱组件的新机会,并渗透到整个网络 [3]。这些问题主要源于 [3, 4]:(i)设备端安全防护薄弱或缺失;(ii)网络分段不佳,导致设备直接暴露在互联网上;(iii)基于通用开发流程遗留了不必要的功能;以及(iv)使用通常被硬编码的默认凭据。因此,对从设备到云的流量进行网络监控和检查正变得至关重要,同时也需要开发新的高效且可扩展的解决方案,以应对这些系统产生的大量数据处理需求。
图形处理单元(GPU)是一种专用的电子电路,旨在显卡上快速处理数据。最初,GPU被用于大量图像处理,但后来其强大的并行计算能力被众多需要执行计算密集型操作的应用程序所利用。
为此,英伟达[5]推出了统一计算设备架构(CUDA,[6])——一种并行计算平台和编程模型。通过使用CUDA,显卡可以被用作通用处理单元,这一概念被称为通用GPU(GPGPU)计算。因此,任何应用程序都有可能利用现代显卡的强大处理能力和高度并行的特性,从而实现相较于仅CPU版本显著的加速比。
一些安全敏感应用需要实时处理大量数据。此类应用包括反恶意软件系统,它们通过监控网络流量或扫描个人计算机的硬盘来查找恶意数据。
本文提出了一种高效且轻量级的用于哈希计算和哈希查找的GPU加速器,称为 CloudNet。该系统在GPU上采用优化实现的SHA‐3[7]算法,作为计算待检测恶意软件摘要的核心哈希函数。随后,我们设计并比较了多种用于存储处理后数据的数据结构,并选择了其中最合适的结构。我们将所提出的方案应用于安全相关的场景中,实现对网络流量的反恶意软件检测和实时恶意软件入侵检测。
本文其余部分组织如下:第2节讨论该领域的相关研究。第3节介绍 CloudNet。第4节包含系统的实现细节,并对底层哈希函数及数据结构的不同参考实现和优化实现进行对比分析。最后,第5节总结全文并指出未来工作。
2 相关工作
所提出的努力集中在显卡上已知安全解决方案的适配。在将反恶意软件解决方案应用于GPU时,性能评估旨在提升系统整体运行效率或特定的内部核心组件。
CloudNet反恶意软件引擎:GPU加速的网络监控 123
在[8, 9]中提出了基于GPU的反病毒引擎。GrAVity [8], 是一种大规模并行的反病毒引擎,它修改了ClamAV(一款开源反病毒软件,[10]),并利用现代图形处理器的计算能力,实现了比仅使用CPU的CalmAV高出100倍的性能。
在[9], 中,作者提出了一种高效的内存压缩方法,用于GPU加速的病毒特征匹配。他们实现了Aho‐Corasick和Commentz‐Walter自动机,结合来自 ClamAV的一组病毒签名,执行GPU加速病毒扫描。他们的反病毒引擎适用于现实世界的软硬件系统。
在[11]和[12]中,报道了利用GPU计算能力的网络安全入侵检测机制。
Gnort [11], 基于开源NIDS Snort,是一种应用于GPU的入侵检测系统,用于将高成本的模式匹配操作从CPU卸载。它提高了整体吞吐量,既可以用于处理合成的网络流量,也可以通过以太网接口监控真实流量。在[12], 中,作者提出了一种用于GPU上入侵检测的正则表达式匹配机制。他们的系统相比传统的 CPU实现实现了48倍加速。
创建恶意软件特征的主要方法是使用哈希函数。为了提高反恶意软件系统的性能,可以加快处理数据摘要的计算过程。为了利用CPU以及后来GPU中的并行计算特性,人们致力于设计可并行化的哈希函数,或设计可用于并行化任意哈希函数的通用机制。SHA‐3竞赛旨在确立新的哈希函数标准。然而,赢得该竞赛的哈希函数Keccak [16], 本身不具备内在的并行性。为了创建能够充分利用GPU潜力的并行实现,必须借助其他机制。这可以通过引入默克尔树[11]结构来实现;该技术可用于并行化任何哈希函数,也是本文所述系统所采用的方法,后文将对此进行详细说明。
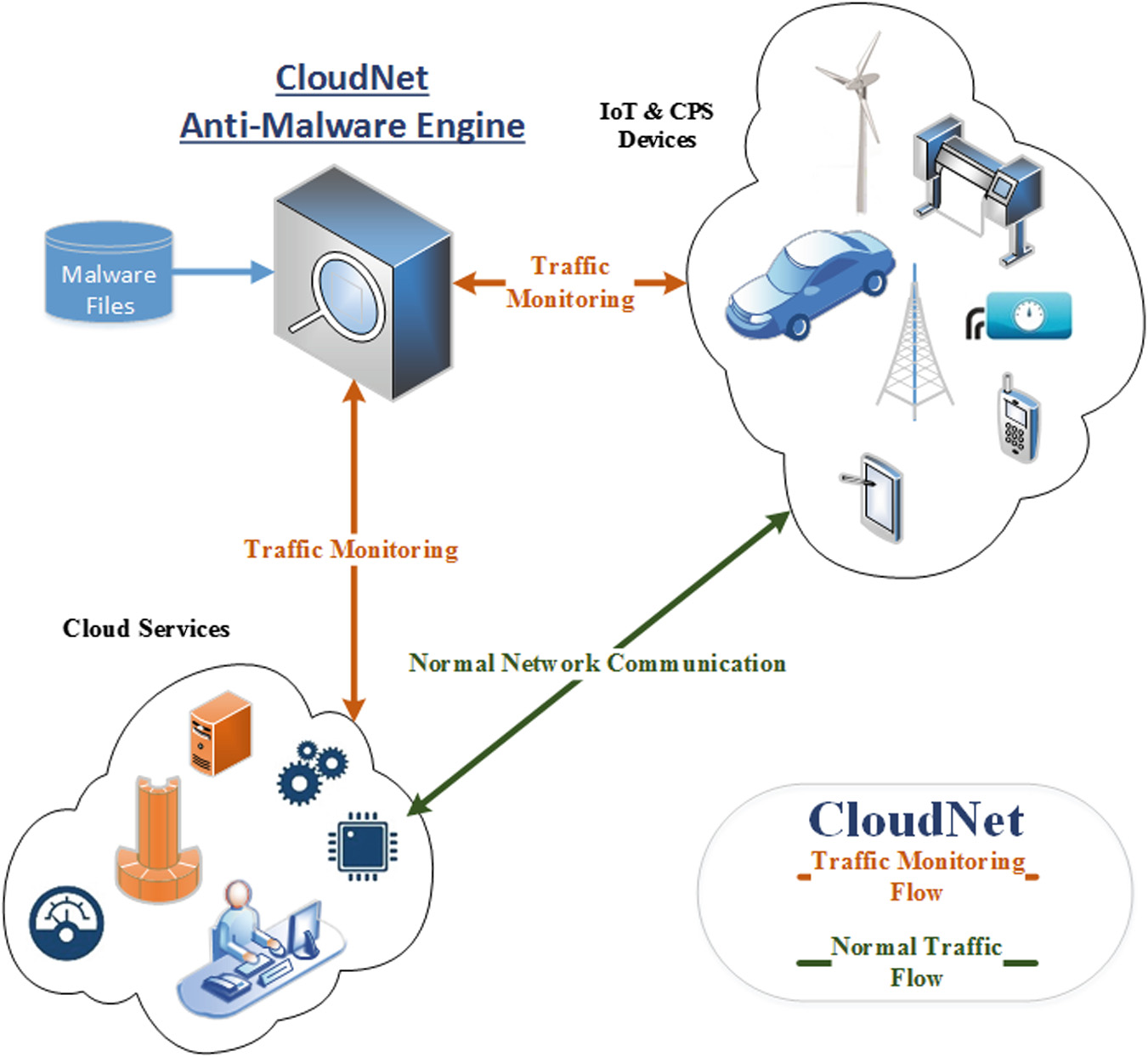
CloudNet 是一种新型反恶意软件引擎,可高效利用先进的 SHA‐3 函数来检测恶意软件流量。该系统在设计时充分考虑了现代物联网和云计算应用(例如 [13, 14])的内在特征和性能要求。该系统保护一个真实的工业环境,其中支持物联网的智能设备和风力涡轮机向工业云交换信息 [15]。关于 GrAVity 和 Gnort,它们可用于进一步提高内部扫描过程的并行化程度。
3 CloudNet
该实现涉及基于SHA‐3[16]哈希函数开发一种轻量级且高效的GPU加速恶意软件识别/哈希查找机制。CloudNet利用CUDA工具包和现代GPU的并行处理能力,提升摘要计算的性能,即在GPU上运行所选加密哈希函数的内部计算。
124 G.哈齐瓦西利斯 等
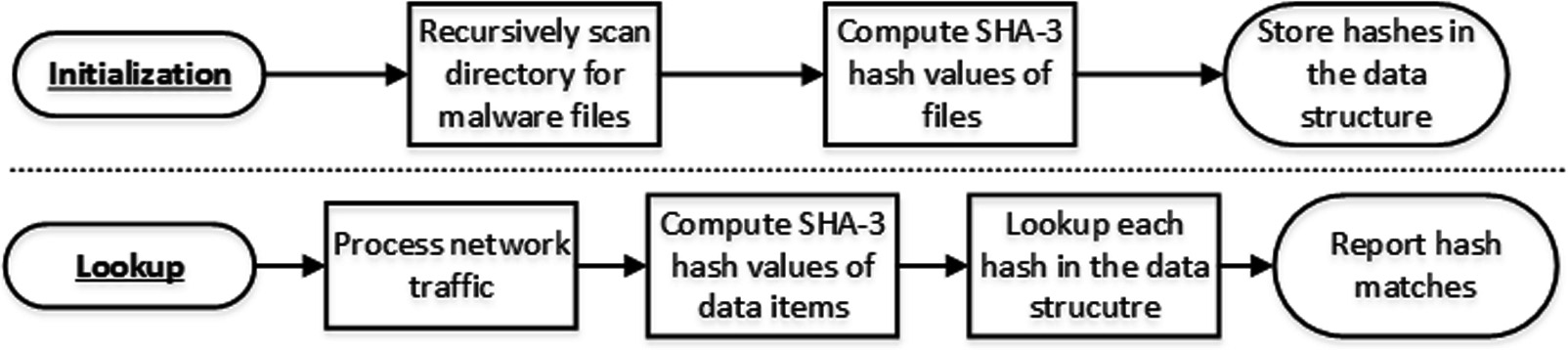
该解决方案实现了两个主要操作。在初始化阶段,系统以包含恶意软件的目录作为输入,计算每个项目的摘要,并将其存储在数据结构中。在处理阶段,系统以网络流量作为输入,计算相关数据段的摘要,并将其与数据结构中维护的信息进行比对。图1展示了恶意软件识别的各个阶段。

对于反恶意软件引擎而言,无论是在CPU还是GPU上,从头开始对整个文件进行哈希计算都是对资源的浪费。你可以改为仅对文件的一小部分(例如前2 KB)进行哈希计算,然后如果在初步哈希表中找到该哈希值,再对文件其余部分计算哈希值。对于大多数被扫描的文件,第一次哈希计算的结果不会在表中找到(我们假设大多数文件是干净的),从而避免了对整个文件进行哈希计算。然而,在本文其余部分中,我们仍会提及对整个文件进行哈希计算的结果,因为整体设置也可应用于其他需要完整处理的相关领域,例如区块链 [17]。
该工具可以扫描整个哈希表,查找其刚刚计算出的特定哈希值的匹配项。
通过这种方式,它可以报告该特定数据是否存在于初始哈希表中,以及该项的具体内容。这种识别机制可用于网络监控或本地磁盘上的恶意软件检测(例如,检测网络中的恶意或标记文件)。
该系统在初始化阶段创建一个哈希表,其中包含已知恶意软件的哈希值 (签名)。在执行查找阶段时,系统使用相同的哈希函数计算输入痕迹的摘要,并在哈希表中预计算的值中查找匹配项。
主要操作包括:
• 计算摘要
• 比较两个摘要
• 在哈希表中插入新摘要
• 在哈希表中搜索摘要
• 报告恶意软件识别
• 删除或移动检测到的恶意流量(可选)。
为了提升GPU加速识别与验证方案的性能,我们专注于内部摘要计算的优化以及
一种用于维护已处理数据的数据结构。我们利用针对CUDA优化的SHA‐3[12]实现来改进内部操作,其中需要计算输入数据的摘要。接下来,我们将分析在不同应用场景下,SHA‐3在CPU和GPU上不同实现方式的性能。此外,我们对三种可用于维护已处理数据的数据结构(哈希表、二叉树和数组)进行了对比分析。
4 性能评估
本节介绍了CloudNet的实现细节。所提出的系统在配备Intel Core i7处理器 (6 MB缓存,2.1 GHz)、8 GB内存、NVIDIA GeForce GTX 1050 GPU (640核,2 GB缓冲区,6Gbps内存速度,1.4 GHz时钟)[19], 和Ubuntu 17.10操作系统的测试平台上进行开发和评估。
初步的CUDA实现的SHA‐3哈希机制与参考串行实现以及优化后的串行实现进行了比较,后两者均可在官方网站[7]上获取。
我们在物联网环境中部署了 proposed solution,其中 CloudNet 监控信息物理系统与云服务之间的网络流量。fic between CPSs and cloud services. 图 2 2展示了应用场景。
126 G.哈齐瓦西利斯 等
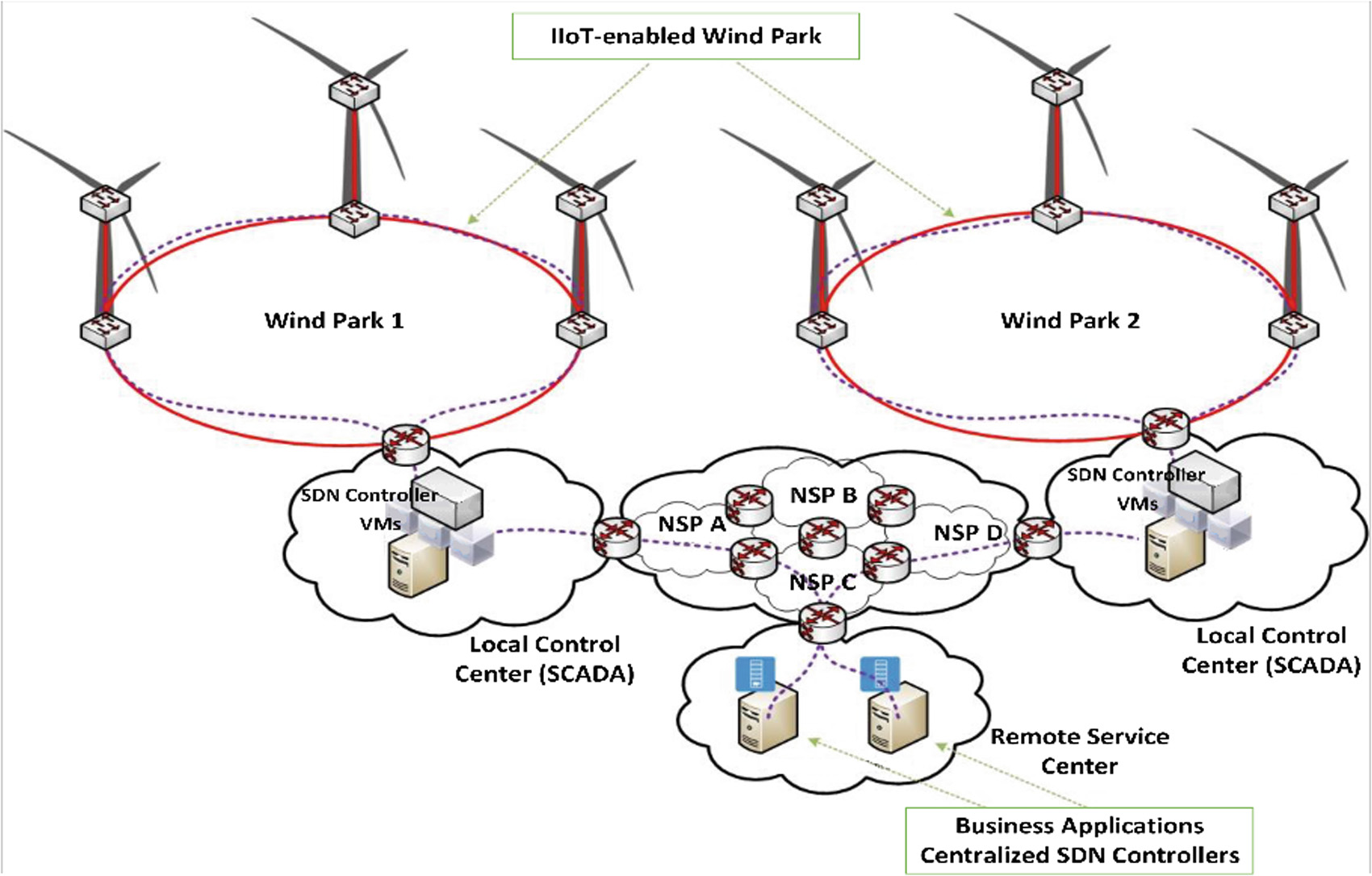
作为基准测试,我们使用了来自丹麦布兰德一个真实工业风电场的流量追踪数据。所研究的软件定义网络(SDN)和网络功能虚拟化(NFV)使能的风电场,是运行在5G通信基础设施之上的下一代网络的一个典型应用场景。多个传感器设备和风力涡轮机向后端数据采集与监控系统(SCADA)服务器传输数据,用于监测和/或响应环境或其他运行参数。该追踪数据聚焦于进出SCADA 服务器的流量,捕获时间约为1000秒的运行时长。总共包含超过20,000个低数据速率的连接。TCP连接根据服务需求表现出100毫秒、250毫秒和500毫秒的端到端延迟。UDP连接则具有更严格的10毫秒通信要求。这些数值被用作 CloudNet适用性的性能阈值。图3展示了工业物联网(IIoT)风电场的部署情况。
4.1 选择数据结构
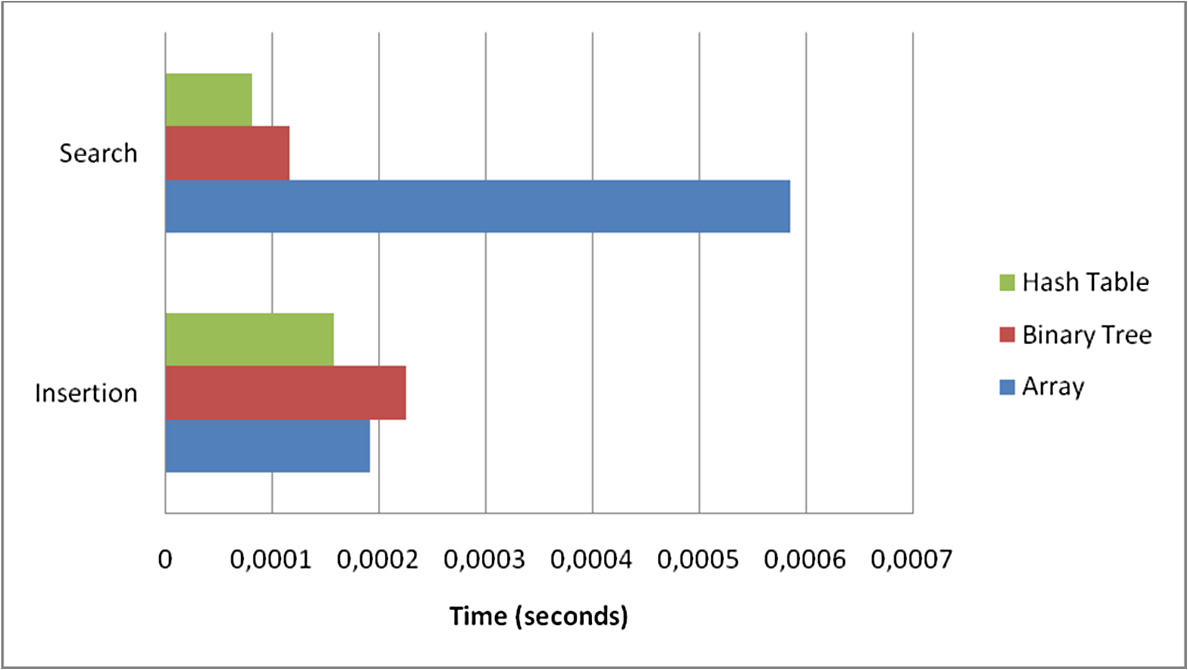
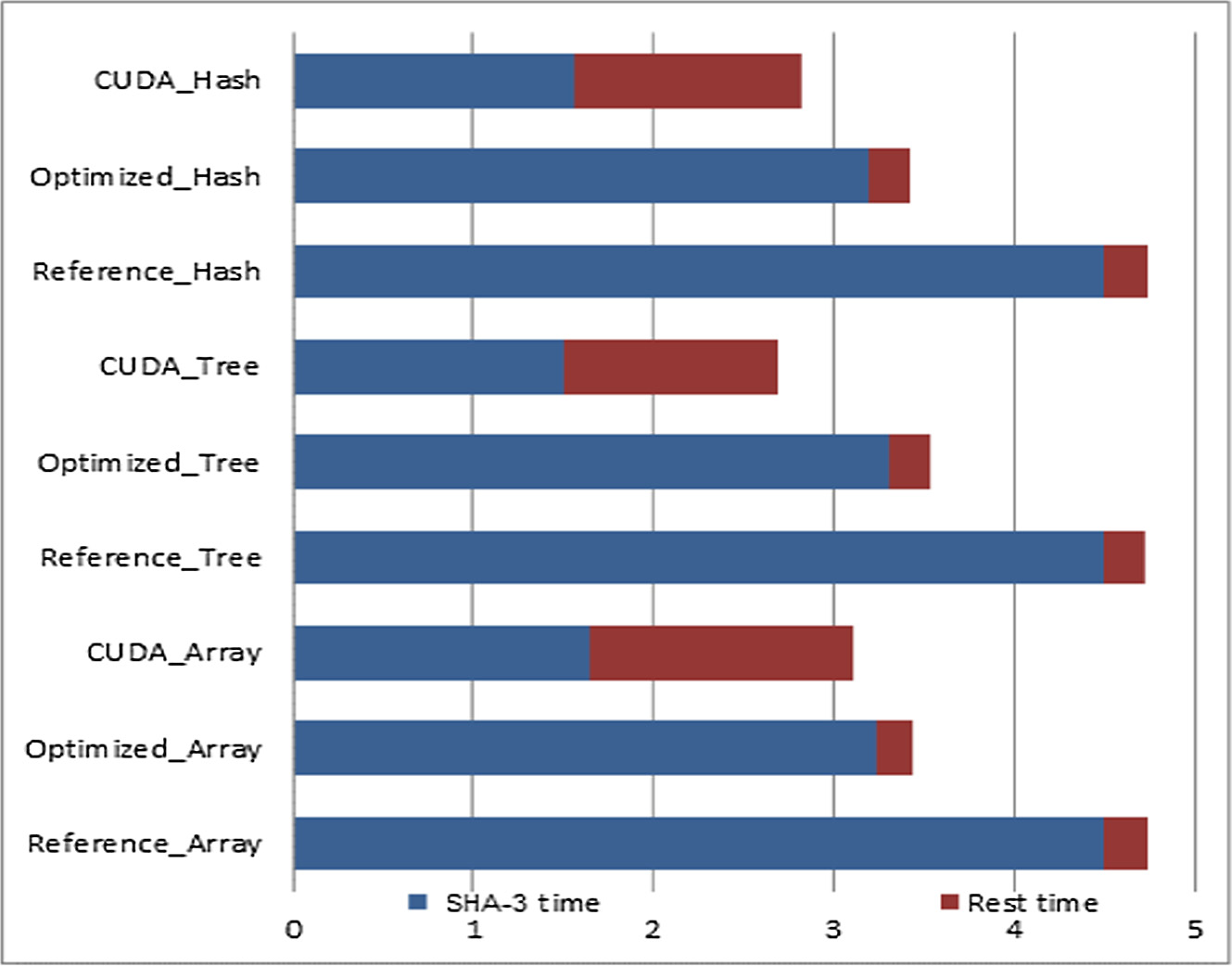
在进行GPU实现之前,必须先确定要使用的数据结构。为此,对不同结构的性能进行了考察和比较。具体而言,研究了数组、二叉树和哈希表结构,重点关注插入时间(即初始化期间将新条目插入数据结构所需的时间)和搜索时间 (即在数据结构中查找特定条目所需的时间)。该比较结果如图4所示,显然哈希表相较于其他结构具有优势。
CloudNet反恶意软件引擎:GPU加速的网络监控 127
4.2 GPU结果
在确定了要使用的数据结构后,工作重点可以放在CUDA哈希机制的开发和优化上。
并行化任何哈希函数的一种方法是在其内部函数中寻找并行性,但由于哈希函数本身通常复杂且串行化,这种方法并不总是可行。SHA‐3 的 CUDA 实现基于一种可用于并行化任意哈希函数的技术,即使用树形哈希模式,也称为默克尔树 [20]。通过该方法,并行性在哈希函数外部实现,即同时运行多个实例(树的叶节点),然后在树的更高层级汇总每个实例的结果。有关常用技术的更多细节可参见 [21]。
此外,程序会检查机器是否配备支持CUDA的GPU,并根据检查结果运行加密哈希函数的优化的CPU代码或CUDA代码。在支持CUDA的设备上,该工具还会检查GPU的硬件特性(支持的CUDA版本),以选择支持重叠的树哈希模式或基本树哈希模式。
简单哈希树机制的一些初步结果如图5所示。这些结果是在配备NVIDIA GeForce GTX 1050 GPU的测试系统上获得的[19]。从图中可以明显看出,哈希机制的GPU加速版本在实际哈希性能方面具有显著优势,但由于数据从主机传输到GPU,也带来了额外的I/O开销。
128 G.哈齐瓦西利斯 等
4.3 进一步优化
通过利用新一代GPU上的特性,成功改进了哈希机制的执行。重叠GPU和 CPU的计算,即在GPU处理其他内核的同时,由CPU计算之前GPU计算任务的树的顶层节点,可以带来显著的性能提升。此外,如果硬件支持,还可以重叠 GPU上的数据传输与计算,从而获得进一步的好处。为实现这一点,必须使用页锁定内存和CUDA流,以允许每个流中数据传输和计算依次进行,如CUDA编程指南[18]所述。
为了评估使用GPU加速所开发应用程序的哈希机制带来的性能优势,创建了一个测试文件夹,并将其用作应用程序执行时间的基准测试。该文件夹包含200个相对较小的恶意软件文件(最小大小3 MB,最大大小50 MB,平均大小20 MB)和 100个较大的文件(最小大小70 MB,最大大小170 MB,平均大小123 MB),并在应用程序的初始化阶段作为输入。因此,应用程序递归地对所有文件进行哈希计算,并将结果存储在哈希表中。
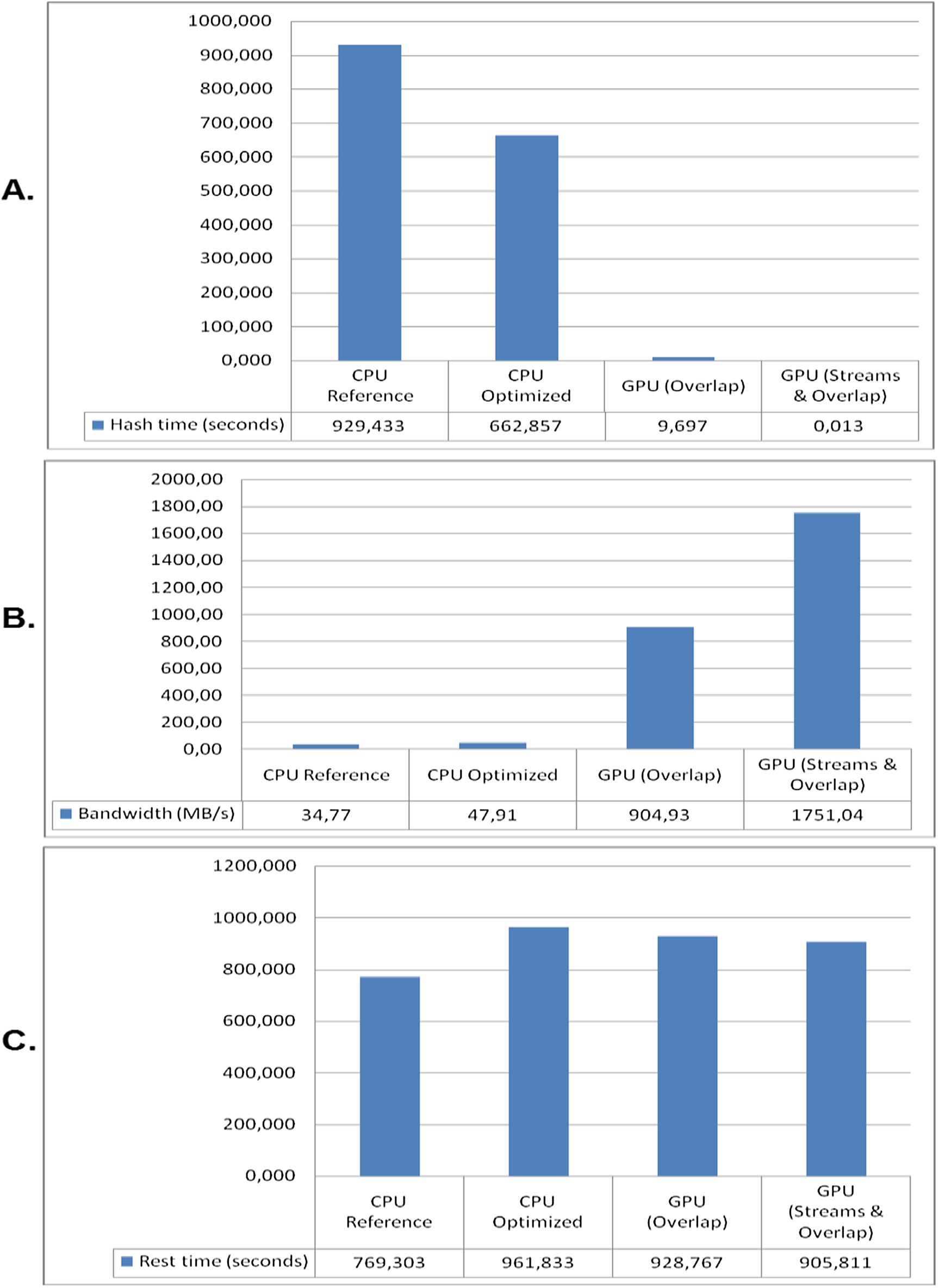
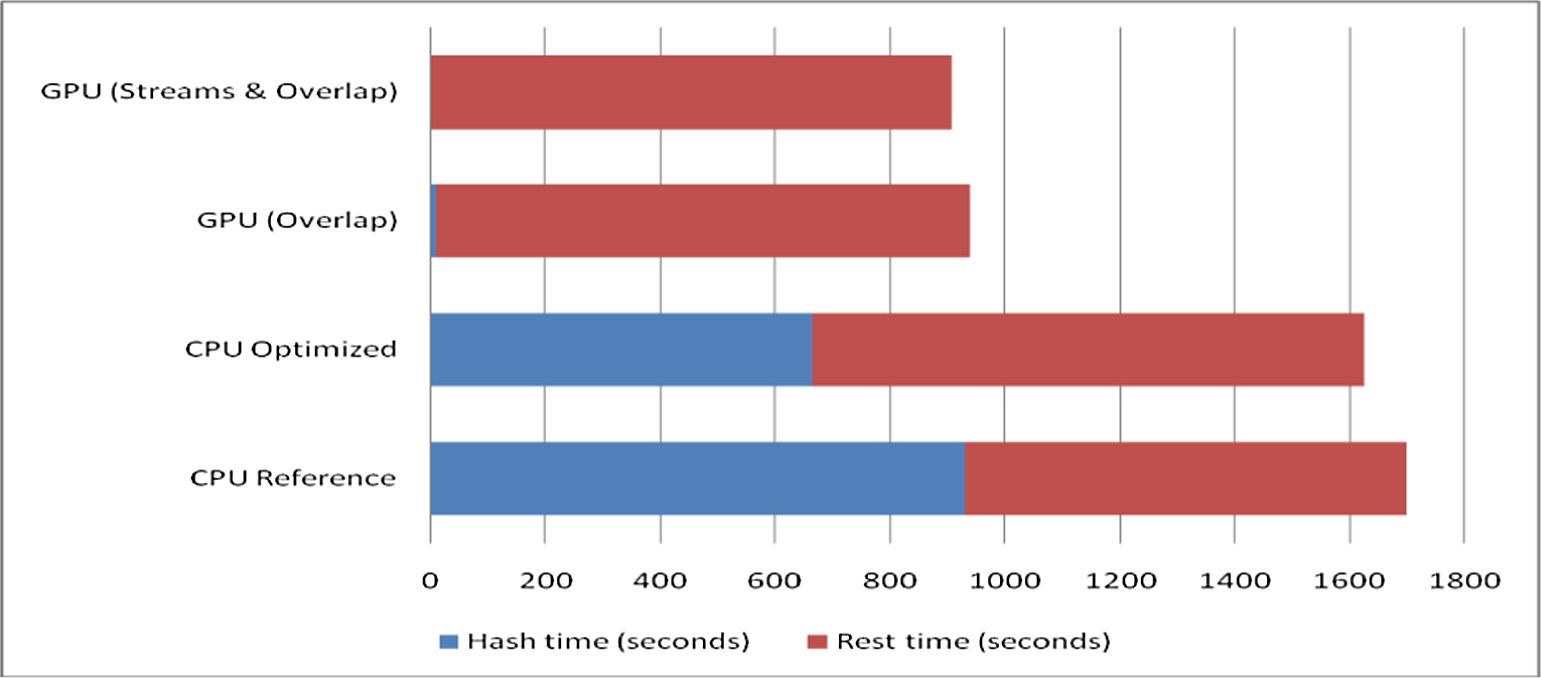
采用改进的GPU实现所带来的性能增益,即重叠GPU和CPU(顶部节点)计算,以及结合GPU传输与计算重叠所获得的额外性能提升,在图6A和B中显而易见。除了显著提升哈希计算速度本身外,如图fi所示,重叠技术还能够最大限度地减少主机到GPU和GPU到主机传输带来的性能开销,这些传输在 GPU实现中是不可避免的。6C。
130 G.哈齐瓦西利斯 等
关于查找阶段,GPU实现’的性能比CPU替代方案稍慢,如图8B所示。这是可以预期的,因为存在将文件传输到GPU以及从GPU传出的额外开销。这可以通过并行化哈希表搜索来解决,但这种尝试只有在大表(即存储多个文件值的表)的情况下才能带来显著的收益。在其当前形式下,所开发的应用程序不会获得明显的好处,因为在查找阶段花费的时间与其他更耗时的部分(如初始化和哈希本身,特别是在CPU上运行时)相比并不显著。
5 结论
本文提出了一种基于CUDA通用图形处理器计算工具包的轻量级且高效的 GPU加速哈希计算与哈希查找机制。我们将所提出的系统应用于一种名为 CloudNet的反恶意软件入侵检测应用中。实现了CPU和GPU上底层原语的参考版本和优化版本,并进行了对比分析以选择最高效的版本。
CloudNet反恶意软件引擎:GPU加速的网络监控 131
系统在真实风电场的流量轨迹下进行了评估,具有工业物联网环境的特性。最高效率的GPU版本比CPU上的参考实现速度快近2倍,几乎消除了哈希计算的开销,执行时间主要消耗在输入/输出操作上。
任何进一步加快应用程序执行时间的尝试,主要应集中在初始化阶段,旨在缓解上述硬盘I/O的瓶颈。此外,可以考虑采用一种结合架构,同时利用 CPU和GPU进行并行计算,其中CPU核心将处理不同的网络流量并将其传递给所提出的GPU加速器。无论如何,在使用SHA‐3算法对文件进行哈希计算时,采用GPU加速的优势是显著的,对各种应用都非常有益,尤其是在不受输入/输出操作性能限制的情况下。


















 841
841

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









