




-
论文:Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
-
连接:https://arxiv.org/pdf/1609.04802.pdf
-
代码:
1.https://github.com/brade31919/SRGAN-tensorflow
2.https://link.zhihu.com/target=https%3A//github.com/OUCMachineLearning/OUCML/blob/master/GAN/srgan_celebA/srgan.py -
背景:本文针对的是SISR问题。主要需要强调的是,超分算法的评估指标多为SSIM,PSNR,传统深度残差网络训练好后,结果指标通常很好,但细节纹理上与人眼感觉上通常效果欠佳,如下图,而生成类网络可以较好的解决这类问题{不过同样,也带来了像素级评价指标下降的问题,因此文章中使用了一种新指标}。

作者认为MSE损失函数类网络会让超分这一多解问题最后算出一个解空间的平均,而生成类网络则更倾向于一个特解,更plausible-looking。
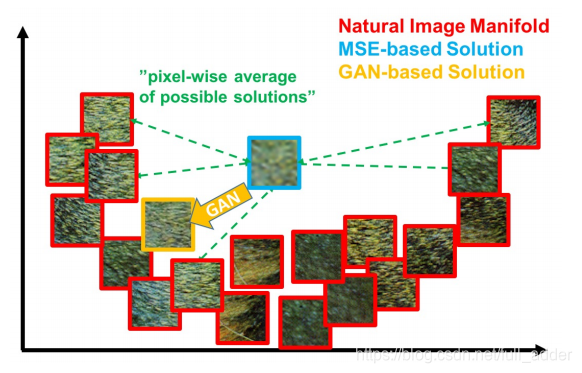
-
文章主要贡献:
1.针对MSE损失函数,训练了具有16块的deepResNet网络,超分倍数为(4×),以PSNR,SSIM为评估指标,获得了当前算法中最好的结果。
2.提出基于GAN网络的SRGAN网络。同时把MSE loss替换为了一种基于VGG网络特征图上计算的loss。
3.对来自三个公共基准数据集的图像进行了广泛的平均意见评分(MOS)测试,确认SRGAN结果在人眼感知上的优越性。 -
网络结构:
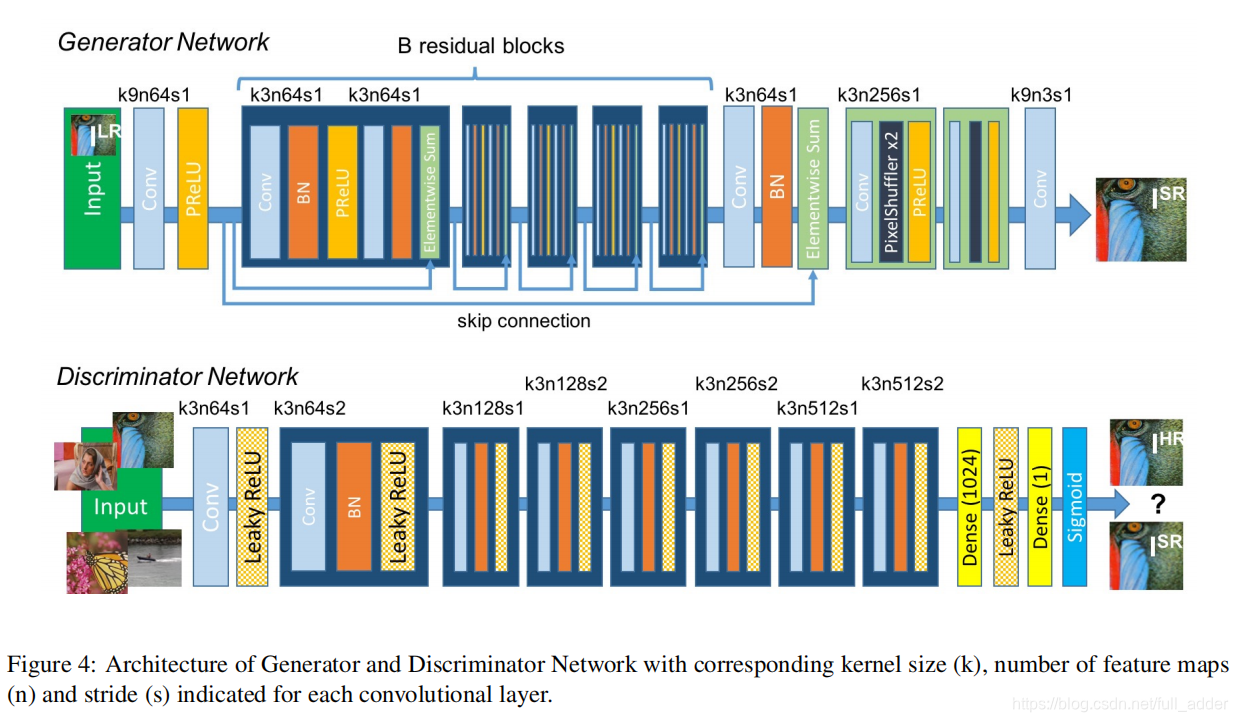
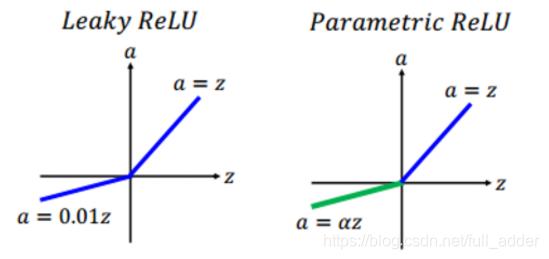
这个结构中不太熟悉的主要是损失函数ParametricReLU,其与LeakRelu的区别如下图,主要是将负数部分的直线斜率设为可训练的参数而不是提前预设的常数。
另外网络的具体设计灵感来源看起来有挺多GAN的论文可看,有时间补充。
网络生成器更新规则为:
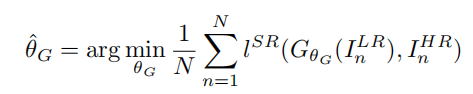
网络
论文阅读笔记:SRGAN
最新推荐文章于 2024-11-28 10:06:37 发布
 本文探讨了超分辨率重建(SISR)问题,指出传统的深度学习方法虽然在PSNR和SSIM等指标上表现良好,但在视觉效果上往往不足。作者提出了一种名为SRGAN的基于生成对抗网络(GAN)的解决方案,该方案用VGG网络特征匹配的损失函数替代了MSE损失。SRGAN在主观评价MOS测试中表现出色,尽管在像素级指标上有所下降。网络结构包括ParametricReLU激活函数,并且训练策略包括了生成器和判别器的特定更新规则。实验结果显示,SRGAN在人眼感知上优于其他方法。
本文探讨了超分辨率重建(SISR)问题,指出传统的深度学习方法虽然在PSNR和SSIM等指标上表现良好,但在视觉效果上往往不足。作者提出了一种名为SRGAN的基于生成对抗网络(GAN)的解决方案,该方案用VGG网络特征匹配的损失函数替代了MSE损失。SRGAN在主观评价MOS测试中表现出色,尽管在像素级指标上有所下降。网络结构包括ParametricReLU激活函数,并且训练策略包括了生成器和判别器的特定更新规则。实验结果显示,SRGAN在人眼感知上优于其他方法。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 594
594

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









