



LiteLLM + OpenRouter 打通 Nano Banana Pro:从 0 到 1 搭建私有文生图设计系统(附源码)
前言
Google 近期发布的 Gemini 3 Pro Image Preview 模型(Nano Banana Pro)在 AI 图像生成领域引起了巨大反响。然而,对于国内开发者而言,如何解决网络访问限制、实现 API 的稳定调用以及构建私有化的应用部署,始终是落地的难点。
本文将深入实战,详细讲解如何通过 LiteLLM + OpenRouter 接入 Nano Banana Pro 模型,并基于此实现一个具备国内网络环境直连 + 完全私有化部署的文生图设计系统。

本文核心实战内容:
- 低成本接入方案:通过 LiteLLM + OpenRouter 解决网络限制,实现超低成本调用(最低单张仅需 0.8 元);
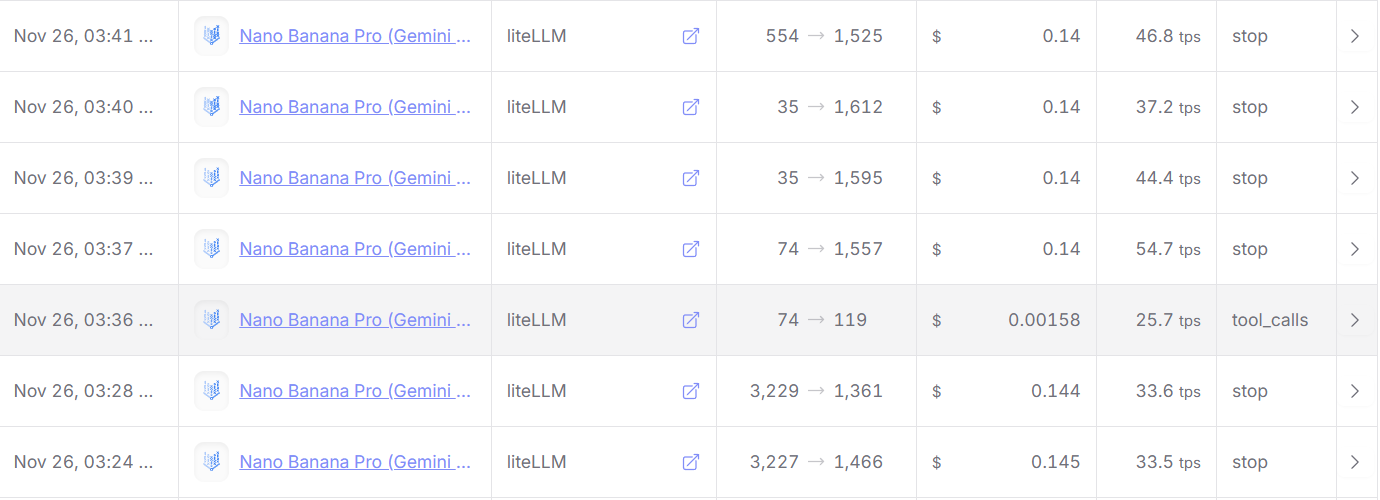
- 高阶生图能力:实现 2K/4K 分辨率、任意比例调整及并发生成;
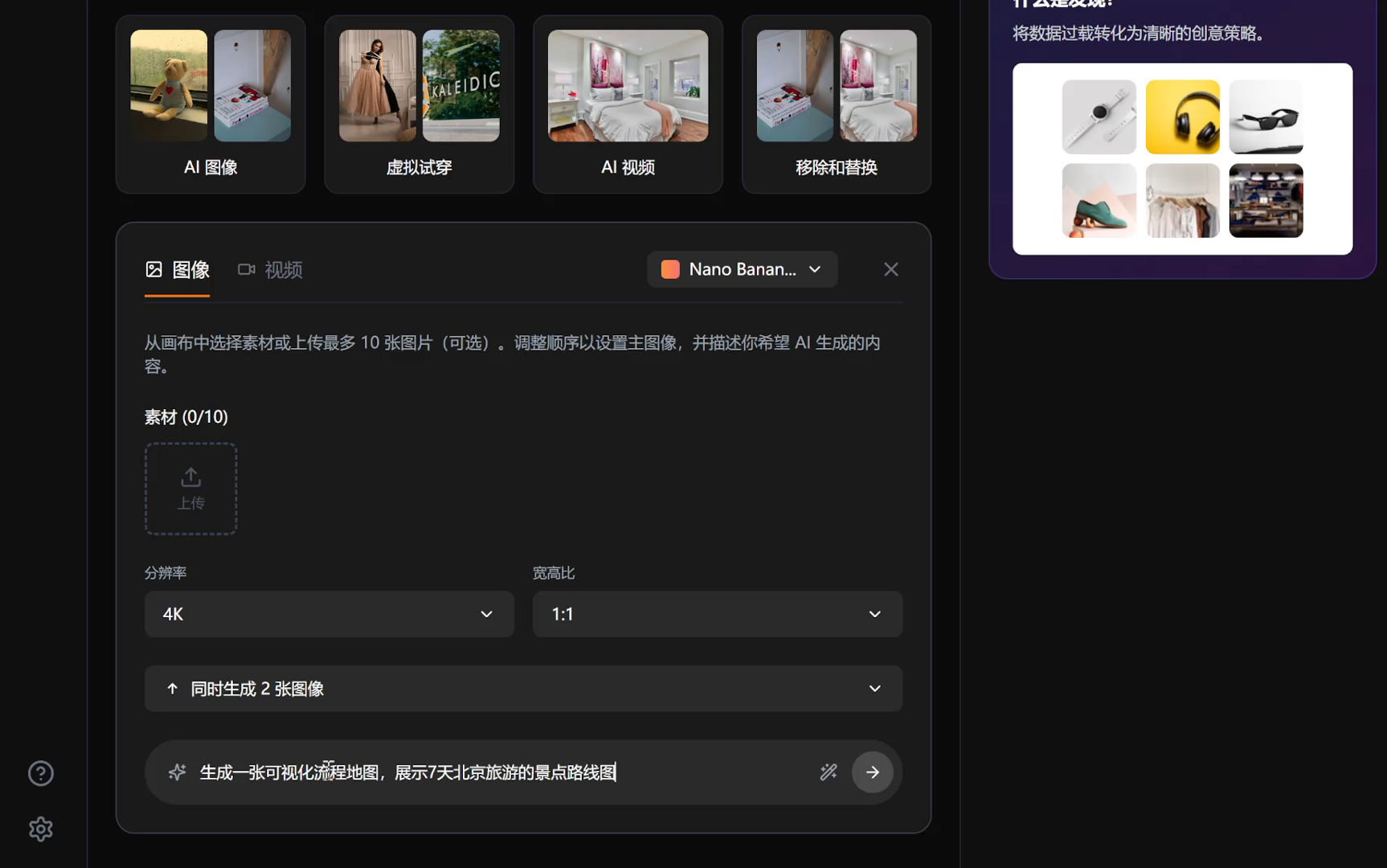
- 全栈系统开发:从后端 API 到前端 UI,构建**支持“文生图”、“图生图”及“多轮修复”**的完整设计系统。

一、Nano Banana Pro 模型深度解析
Nano Banana Pro 作为 Google 图像生成技术的集大成者,相比前代模型实现了质的飞跃。

根据官方文档与实测数据,Nano Banana Pro 具备以下9大核心技术突破
| 序号 | 技术突破 | 核心能力描述 |
|---|---|---|
| 1 | 图像生成质量大幅提升 | 细节更加丰富,光影与色彩还原度极高 |
| 2 | 多语种文本生成能力 | 解决了传统 AI 模型在图片中生成清晰文字(尤其是多语种)的痛点 |
| 3 | 原生图像推理能力 | 能够深度理解图像间的逻辑关系与上下文 |
| 4 | 真实物理世界理解 | 物理规律符合度大幅增强(如重力、反射、材质质感) |
| 5 | 专业摄影级控制 | 支持对色彩、光效、景深等专业摄影参数的精细控制 |
| 6 | 4K 高清分辨率 | 最高支持 4K 分辨率</font> 生成,满足专业设计需求 |
| 7 | 任意比例与扩写 | 支持 Outpainting(画幅拓展),且保持风格高度一致 |
| 8 | 多实体一致性 | 精准识别并组合多达十几个实体</font>,保持画面主题统一 |
| 9 | 写实感提升 | 大幅降低“AI味”,生成的生物照片(如红眼树蛙)几可乱真 |
值得注意的是,Nano Banana Pro 是 Gemini 模型生态的重要组成部分,支持与 Gemini 3 等模型进行多模态协作,甚至结合 Voe 3 模型实现静态图片转动态视频。
详细的模型能力及玩法演示可参考 Nano Banana Pro 零门槛上手+7类核心玩法教程
二、现有调用方式与痛点分析
目前官方提供了多种使用途径,但在实际开发集成中存在一定局限性:
- Gemini 主页(Web端):适合C端用户,操作简单,但无法集成到代码中,且有每日生成额度限制。

-
Google AI Studio & 原生 API:
官方提供了 Python SDK (google.genai),代码如下:from google import genai # ...省略部分配置代码... response = client.models.generate_content(model="gemini-3-pro-image-preview", ...)痛点:原生 API 对网络环境要求极高(魔法上网环境不稳定),且 Google 的风控策略导致国内开发者账号容易受限。

解决方案:为了解决上述问题,本文采用 LiteLLM + OpenRouter 的架构方案。
三、技术架构设计:LiteLLM + OpenRouter

本项目的架构核心在于引入了中间层,解耦了业务逻辑与具体模型提供商:
- OpenRouter(统一网关):作为模型聚合层,它聚合了 Google、OpenAI、Anthropic 等多家厂商的模型。我们只需一个 API Key 即可访问 Nano Banana Pro。
- LiteLLM(统一接口):作为 Python 库,它抹平了不同模型 API 格式的差异(如 OpenAI 格式 vs Google 格式)。
调用链路:
Python 业务代码 -> LiteLLM (统一封装) -> OpenRouter (API 网关) -> Google Gemini 3 Pro
四、开发环境与 API 配置
可加入 赋范空间 免费领取 完整源代码 以及 详细的提示词工程文档,还有更多AI前沿技术讲解、Agent开发、模型微调等相关内容。

1. 基础依赖安装
项目依赖 litellm 进行模型调用,pillow 进行图像处理。
pip install litellm python-dotenv Pillow
2. 获取 OpenRouter API Key
访问 OpenRouter 官网 注册并创建 API Key。
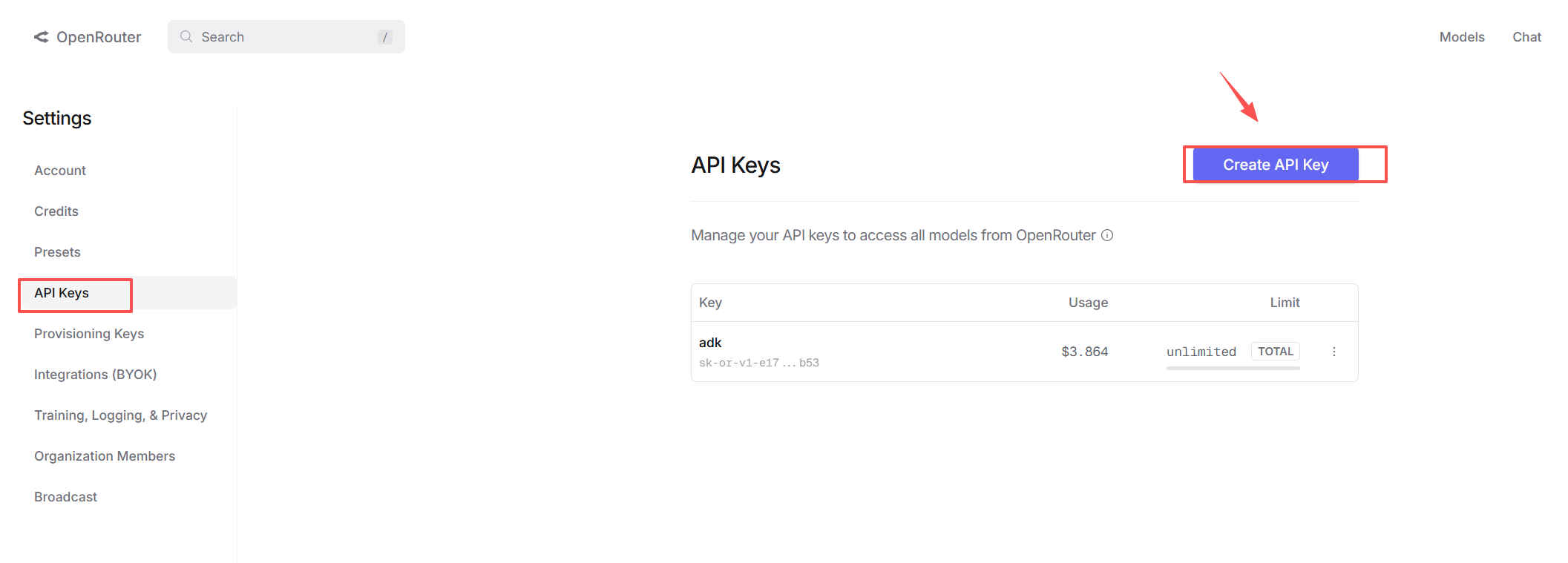
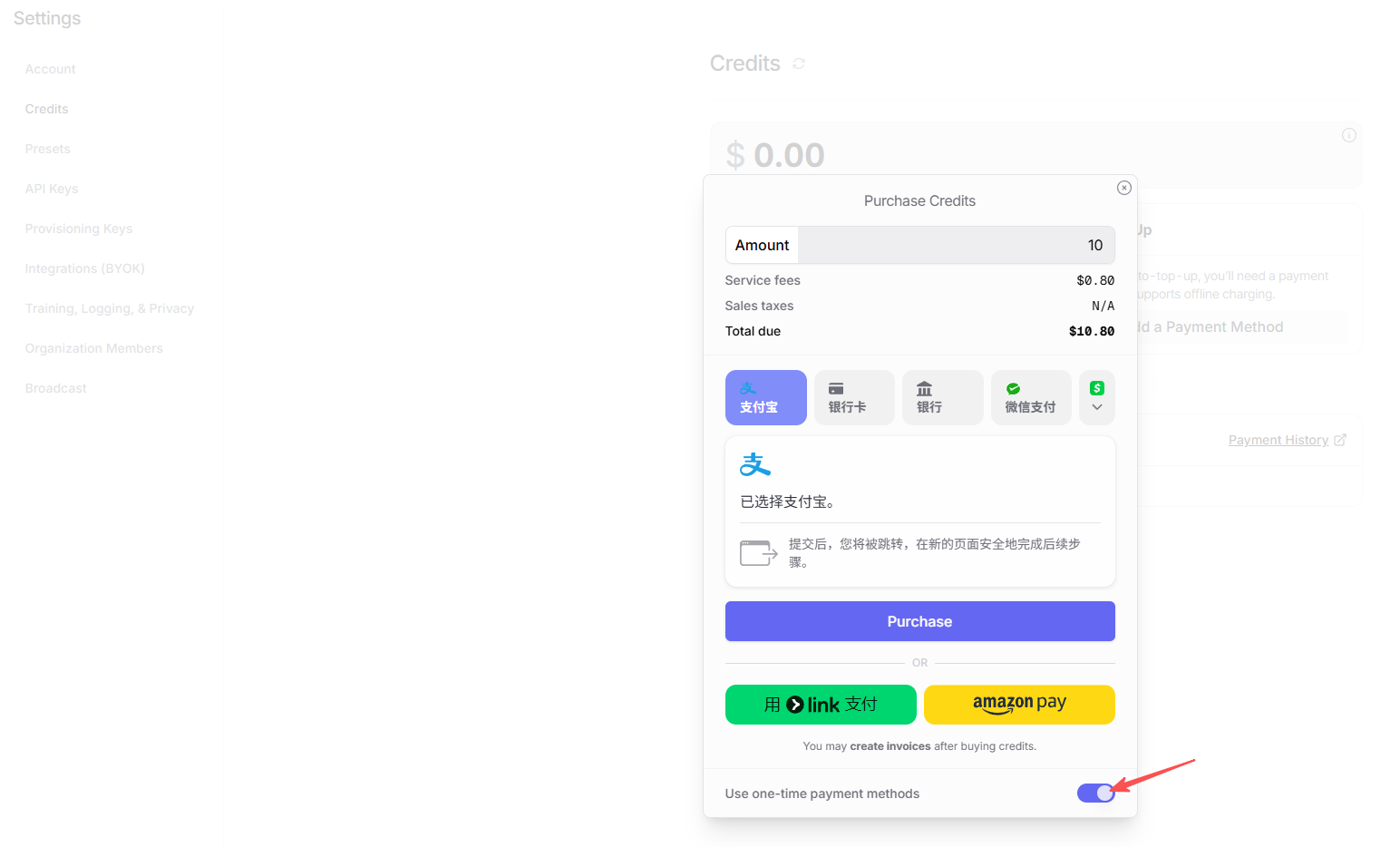
OpenRouter 支持国内支付方式,且按量计费,无须购买昂贵的月度订阅。
3. 配置环境变量
为了安全起见,推荐使用 .env 文件管理密钥:
# .env 文件内容
OPENROUTER_API_KEY=sk-or-v1-xxxxxxxxxxxxxxxxxxxx
# 代码中加载
from dotenv import load_dotenv
import os
load_dotenv(override=True)
api_key = os.getenv("OPENROUTER_API_KEY")
模型标识:在 OpenRouter 中,Nano Banana Pro 的模型 ID 为 openrouter/google/gemini-3-pro-image-preview。
五、核心功能一:Nano Banana Pro 文本对话
首先实现基础的文本对话能力,这是构建 Agent 的基础。利用 litellm.completion 接口,我们可以轻松实现对话,为接下来的文生图和图生图提供基础能力。
核心代码实现
from litellm import completion
# 维护对话历史
conversation_history = []
def chat(user_message):
conversation_history.append({"role": "user", "content": user_message})
response = completion(
model="openrouter/google/gemini-3-pro-image-preview",
messages=conversation_history,
temperature=0.7,
max_tokens=2048,
)
ai_message = response.choices[0].message.content
conversation_history.append({"role": "assistant", "content": ai_message})
return ai_message
六、核心功能二:Nano Banana Pro 文本生成图片(Text-to-Image)
这是本系统的核心功能。与普通 LLM 调用不同,生成图片需要指定 modalities 参数。
核心代码实现
def generate_image(prompt, filename=None):
print(f"正在生成: {prompt}")
try:
response = completion(
model="openrouter/google/gemini-3-pro-image-preview",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": prompt} # 结构化 Content
]
}
],
modalities=["text", "image"], # 关键参数:指定输出图片模态
temperature=0.7,
)
# 解析返回的图片数据
message = response.choices[0].message
image_data = message.images[0]
# ... (此处省略 Base64 解码与 Pillow 保存代码,见完整源码,可免费领取) ...
print("图片保存成功")
return save_path
except Exception as e:
print(f"生成失败: {e}")
return None
生成效果演示
Prompt: “宁静的海面上,夕阳西下,波光粼粼,天空被染成了橙色和粉色。”

Prompt (复杂架构图): “请生成一张架构图,内容基于以下描述的三者关系:LiteLLM…OpenRouter…Gemini…”

七、核心功能三:Nano Banana Pro 多图混合与编辑(Image Blending)
Nano Banana Pro 支持 最多 14 张图片 的混合输入。这使得我们可以实现 “换装”、“场景合成”、“风格迁移” 等高级功能。
实现逻辑
- 读取本地图片并转为 Base64 编码。
- 构建包含多个
image_url和text指令的 Message体。 - 调用 API。
核心代码实现
# 构建多模态输入内容
content_parts = []
# 1. 添加图片资源
for img_path in image_paths:
base64_str = encode_image_to_base64(img_path)
content_parts.append({
"type": "image_url",
"image_url": {"url": base64_str}
})
# 2. 添加编辑指令
content_parts.append({
"type": "text",
"text": "根据提供的主体人物照片,替换服饰,使用提供的背景图片作为最终背景..."
})
# 3. 发送请求
response = completion(
model="openrouter/google/gemini-3-pro-image-preview",
messages=[{"role": "user", "content": content_parts}],
modalities=["text", "image"],
temperature=0.7,
)
生成效果演示

可加入 赋范空间 免费领取 完整源代码 以及 详细的提示词工程文档,还有更多AI前沿技术讲解、Agent开发、模型微调等相关内容。
八、私有化系统全栈部署
基于上述核心技术,我们构建了一个前后端分离的完整 Web 应用(见完整源码,可免费领取)。
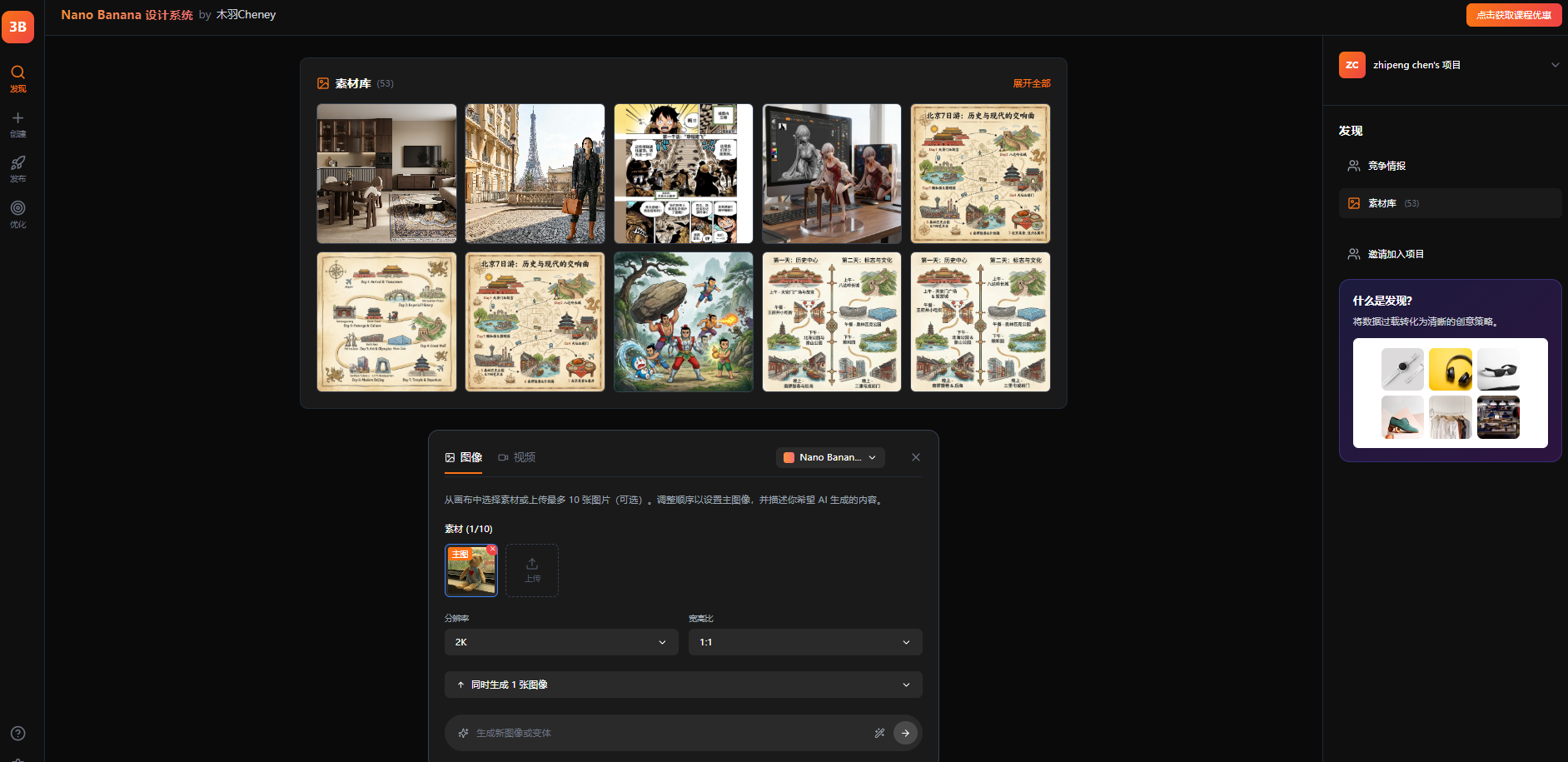
1. 技术栈选型
- 前端:React 18 + TypeScript + Vite + Tailwind CSS (现代化 UI 体验)
- 后端:FastAPI (异步高性能) + LiteLLM
- 架构:前后端分离,RESTful API 交互
2. 目录结构
Gemini3_to_image/
├── frontend/ # React 前端
├── backend/ # FastAPI 后端
│ ├── app/
│ │ ├── services/ # 图像生成核心逻辑
│ │ └── api/ # 接口定义
│ ├── .env # 配置文件
│ └── run.py # 启动脚本
3. 本地部署指南
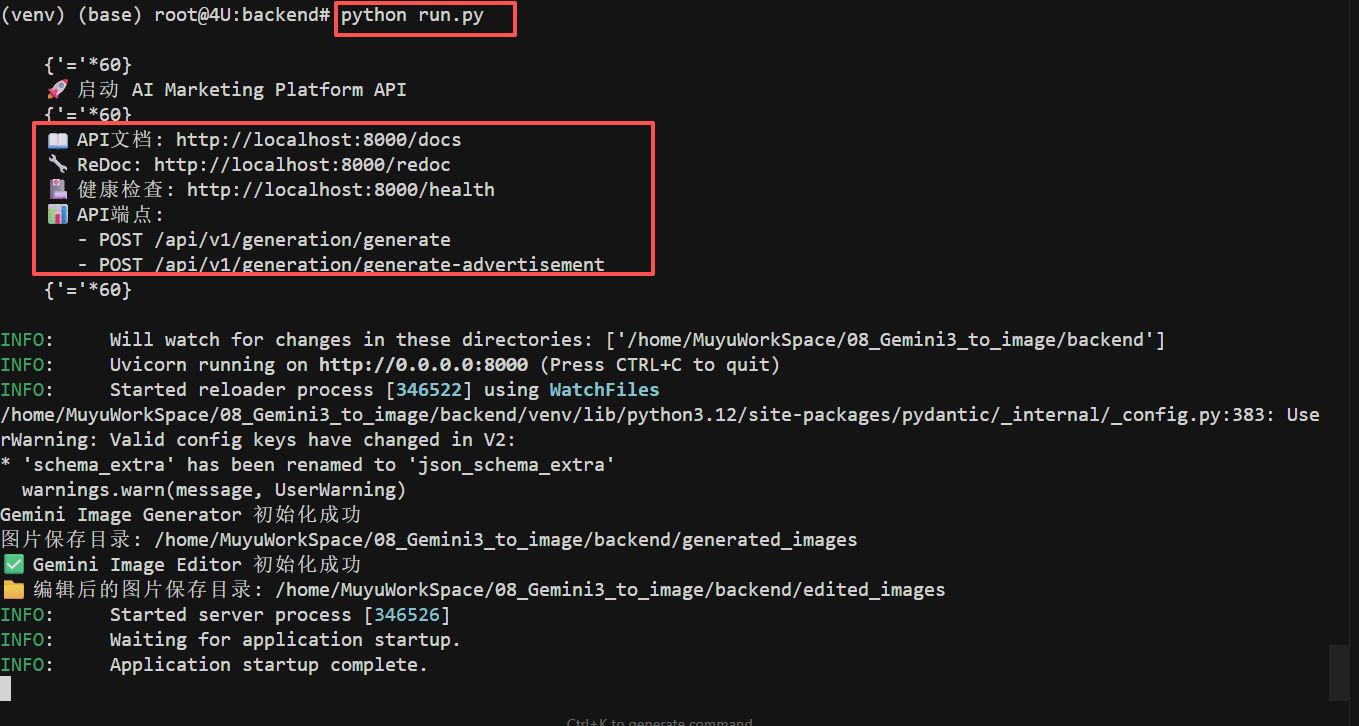
后端启动
- 进入
backend目录,创建并激活虚拟环境。 - 安装依赖:
pip install -r requirements.txt - 配置
.env文件填入OPENROUTER_API_KEY。 - 运行服务:
python run.py(默认端口 8000)
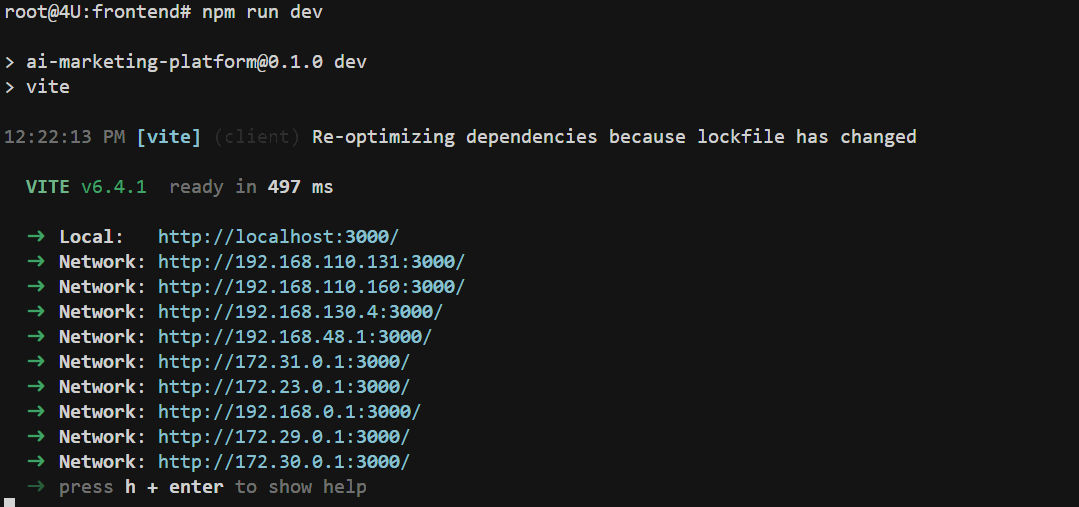
前端启动
- 进入
frontend目录。 - 安装依赖:
npm install - 启动开发服:
npm run dev(默认端口 3000)
部署完成后,浏览器访问 http://localhost:3000 即可使用属于你自己的私有化文生图工作站。
总结
通过 LiteLLM 和 OpenRouter 的组合,我们成功绕过了复杂的网络配置和繁琐的官方 SDK 鉴权,以极低的门槛将 Google 最先进的 Gemini 3 Pro 图像生成能力集成到了私有应用中。希望本文能为各位开发者的 AI 应用落地提供帮助。
当然如果只是想要国内免费线上试用 NanoBananaPro 可参考 白嫖 NanoBananaPro:国内免费体验与 API 接入全指南


















 3545
3545



 到【灌水乐园】发言
到【灌水乐园】发言








