



本期内容整理自九天老师B站视频,实测OpenAI最新发布的GPT-4.1模型,连夜追更不易,还请小伙伴们三连支持哦~
技术霸权没有永恒,但是知耻而后勇,敢于自我批评却能够让一个组织基业长青。OpenAI在经历了两个月的阵痛和反思之后,大刀阔斧的进行了技术路线调整,毅然决定放弃GPT-4.5,并且在重新评估了开发者的真实需求后,推出了全新一代旗舰模型GPT-4.1。
不出所料的是,这款模型也正是前段时间在OpenRouter上大杀四方的Optimus Alpha模型。在此前的匿名测评中,这款模型已经处理了700多亿个token,在编程、指令跟随和创意写作方面表现的都非常惊艳,短短两周的评测收获了大量开发者的一致好评,
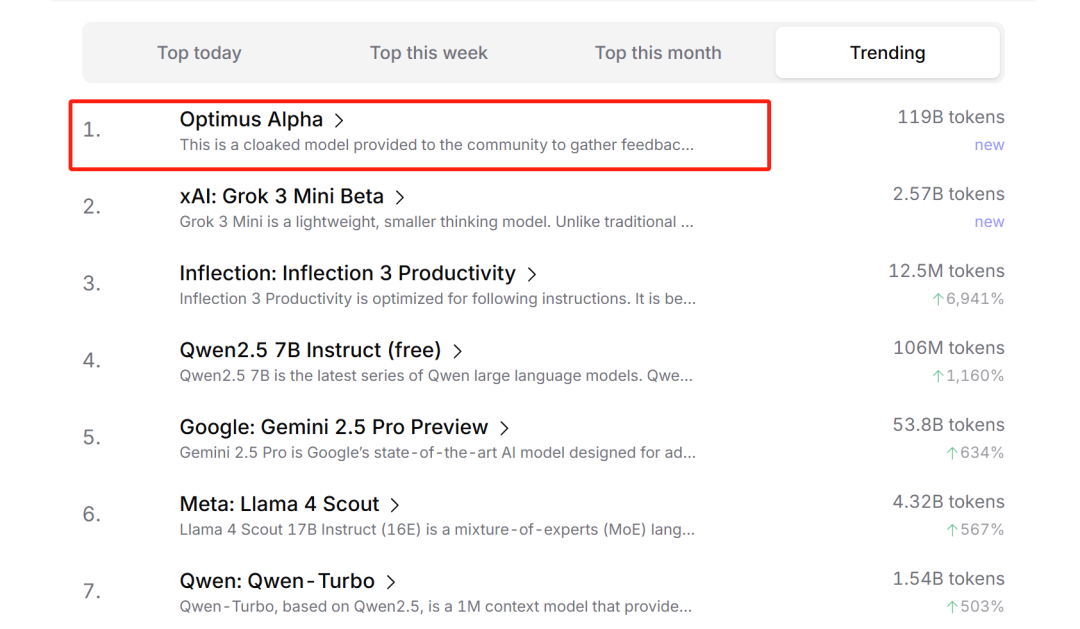
甚至不少开发者觉得这款模型就是现阶段,集对话、推理、编程能力于一身的最佳模型。
而现在本尊现世,GPT-4.1模型正式发布。有人嘲讽OpenAI不会取名,4.1模型居然在4.5模型之后发布,简直让人摸不着头脑,但我却认为,在经历了GPT-4.5模型的惨败之后,OpenAI有勇气给新模型取名为GPT-4.1,恰恰是敢于自我批判的一种表现。就在新模型发布的前两天,OpenAI先是官宣了GPT-4这个具有里程碑意义的模型即将下线,

然后又极为罕见的开设了一场直播来探讨GPT-4.5模型训练失败的惨痛教训。
而这次新模型的取名为GPT-4.1,很明显就是为了继承GPT-4模型的意志,继续扛起OpenAI旗舰模型的大旗,尽管看起来新模型在GPT-4.5的编号上降了级,但这恰恰体现了新模型不再走高举高打走激进路线,而更加专注于给开发者提供切实有价值服务的决心。
就冲着OpenAI这股劲头,我们团队也是连夜通宵翻译了本次GPT-4.1模型一万多字的技术文稿,并进行了多项模型功能测试,相关文档和OpenAI零门槛接入指南,大家扫码即可领取。

经测试,GPT-4.1模型效果确实非常惊艳,在长文档检索、前端编程、指令跟随和视觉推理这四个方面堪称当前业内SOTA(最强)模型,并且相比Claude 3.7、Gemini 2.5 Pro模型,定价和响应速度都有一定优势,
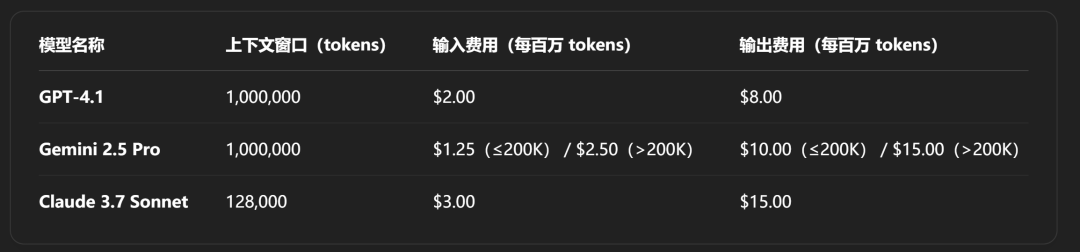
可以说是目前的顶流大模型了。接下来,就让我为大家详细介绍下这款GPT-4模型的继任者、OpenAI新一代旗舰模型,GPT-4.1。
本次GPT-4.1模型总共发布了三个版本,分别是GPT-4.1、GPT-4.1 mini和GPT-4.1 nano。三款模型都拥有100万tokens上下文长度,并且都具备文本编写、推理能力和视觉推理能力三项核心能力,三款模型性能和价格依次递减,而响应速度依次递增,其中nano模型是首次出现在GPT模型型号序列中的小号模型,适合执行繁琐类型任务。
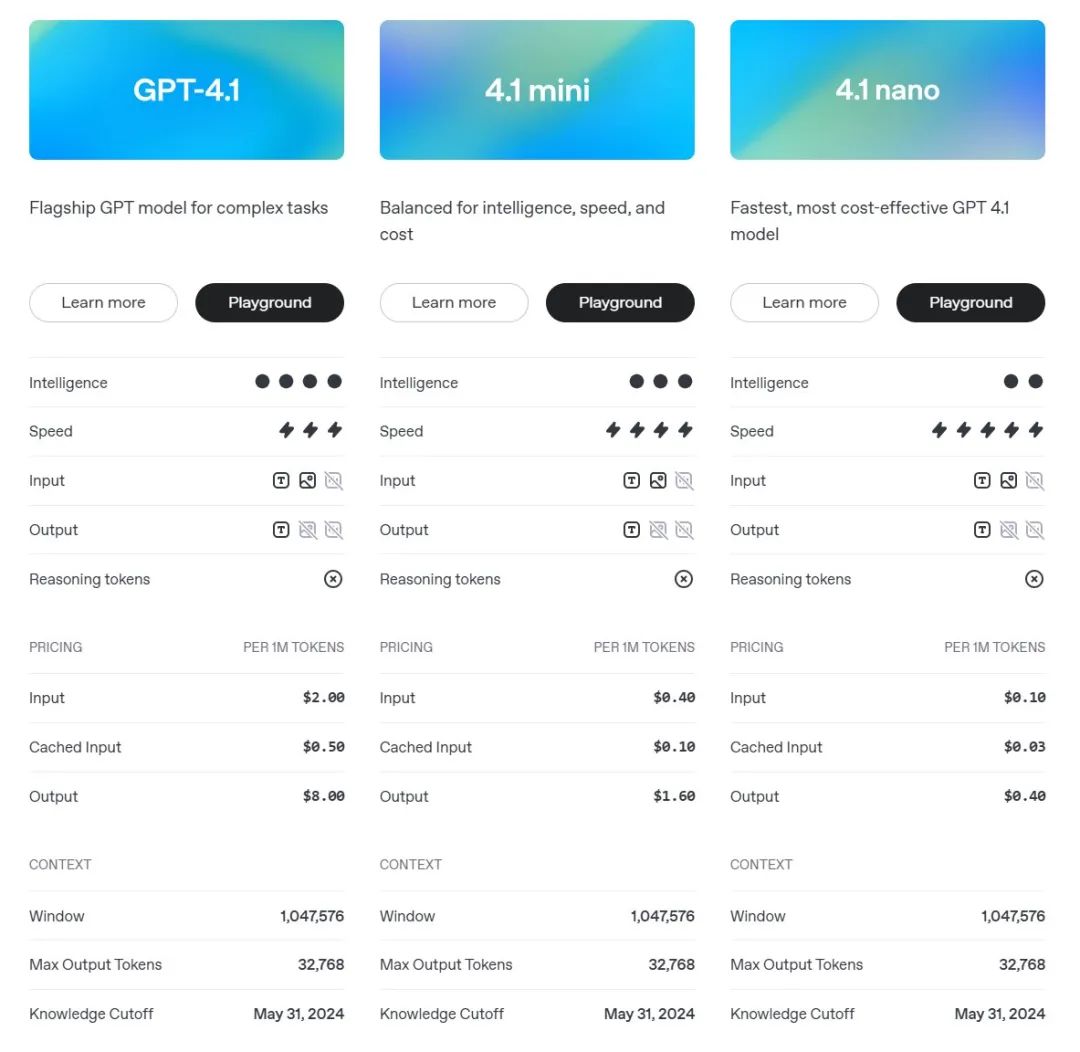
从模型整体来看,GPT-4.1模型同时融合了o3模型推理能力和GPT-4.5模型的对话能力,外界猜测模型可能同时由o3模型和GPT-4.5模型蒸馏而来,并且同时围绕超长文本检索、前端编程、指令跟随和视觉推理四个方面,进行特定领域的能力优化,使其实用性大幅增强。
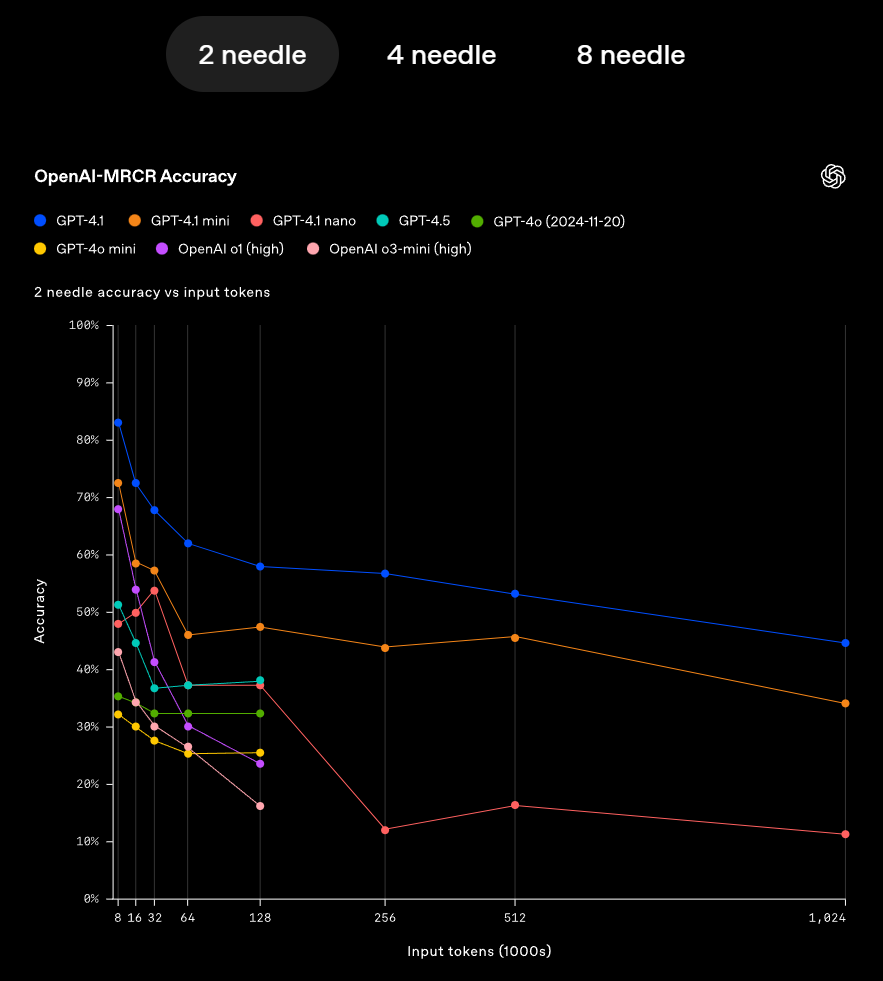
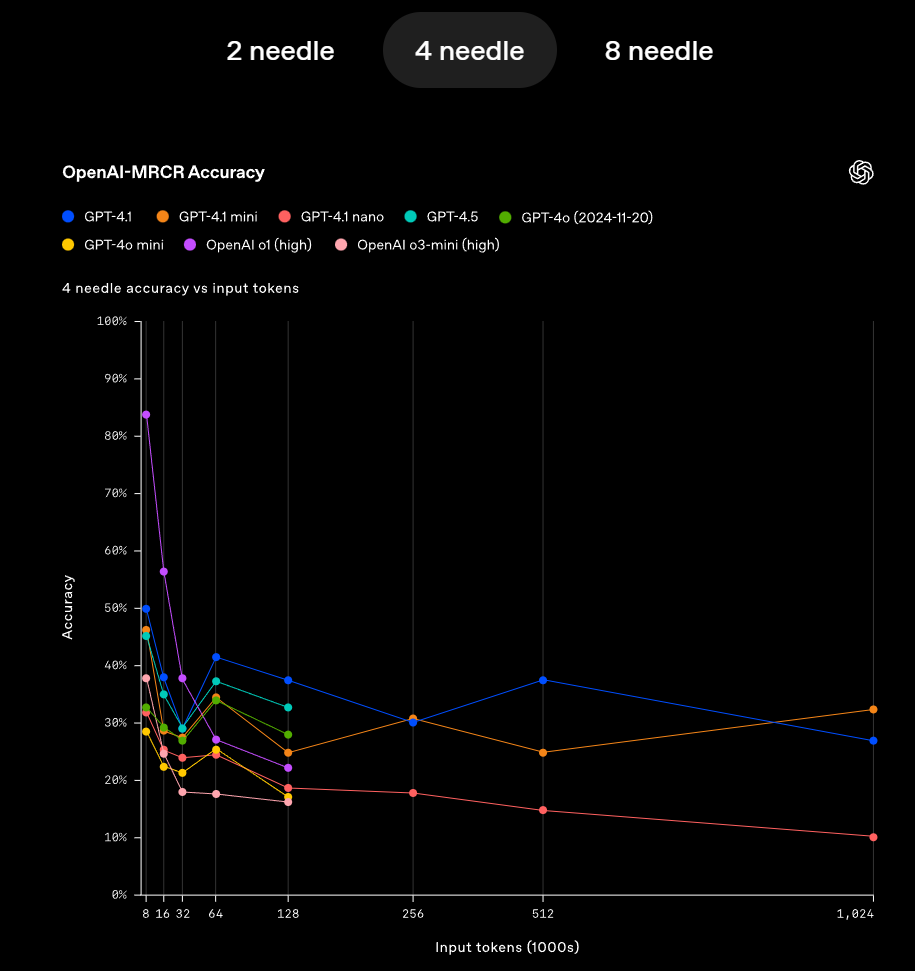
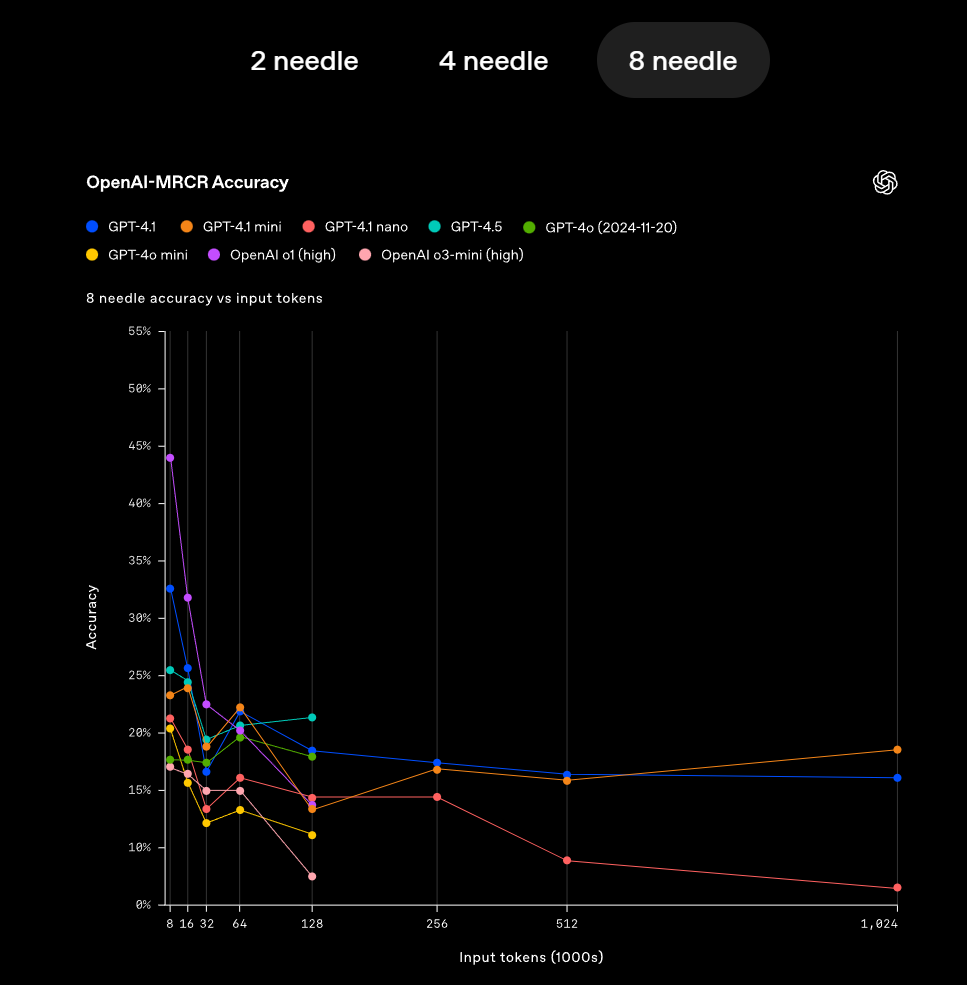
我们先来看模型长文档阅读能力,这次GPT-4.1全系列三款模型都拥有100万tokens上下文长度,并且检索精度非常高,三款模型在1M文本大海捞针测试上都达到了100%准确率,
甚至OpenAI为了拔高测试难度,还开创建并开源了mrcr和graphwalks两个数据集,
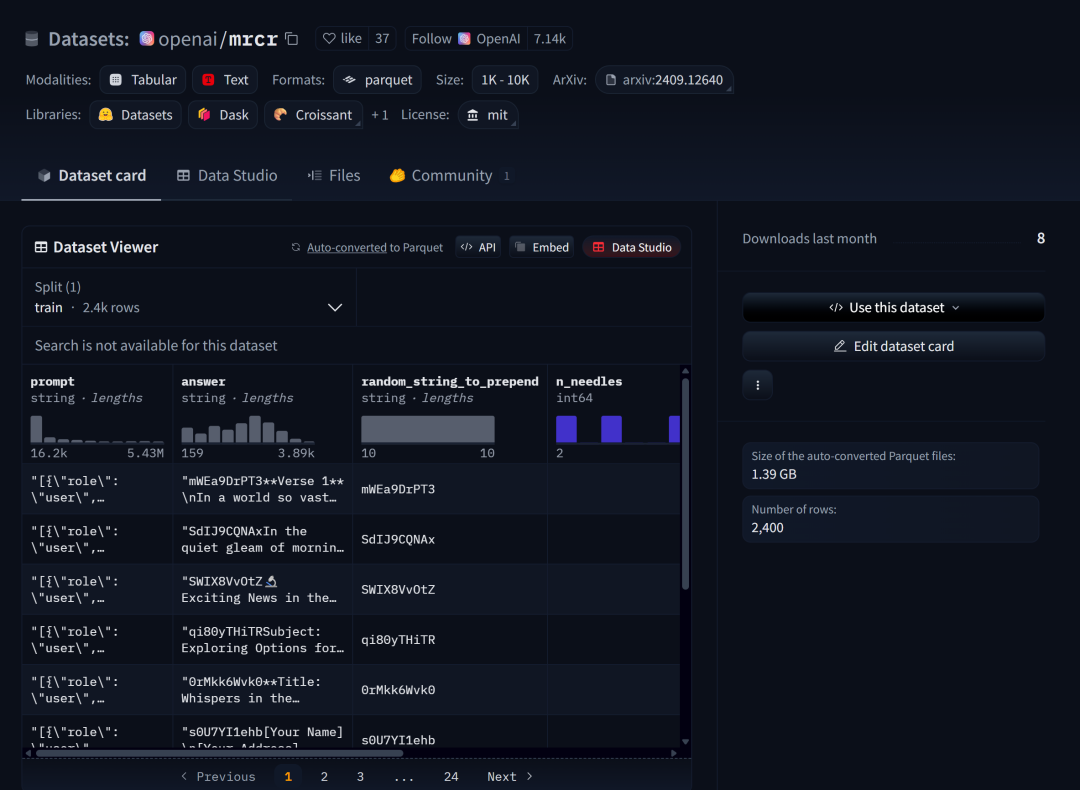
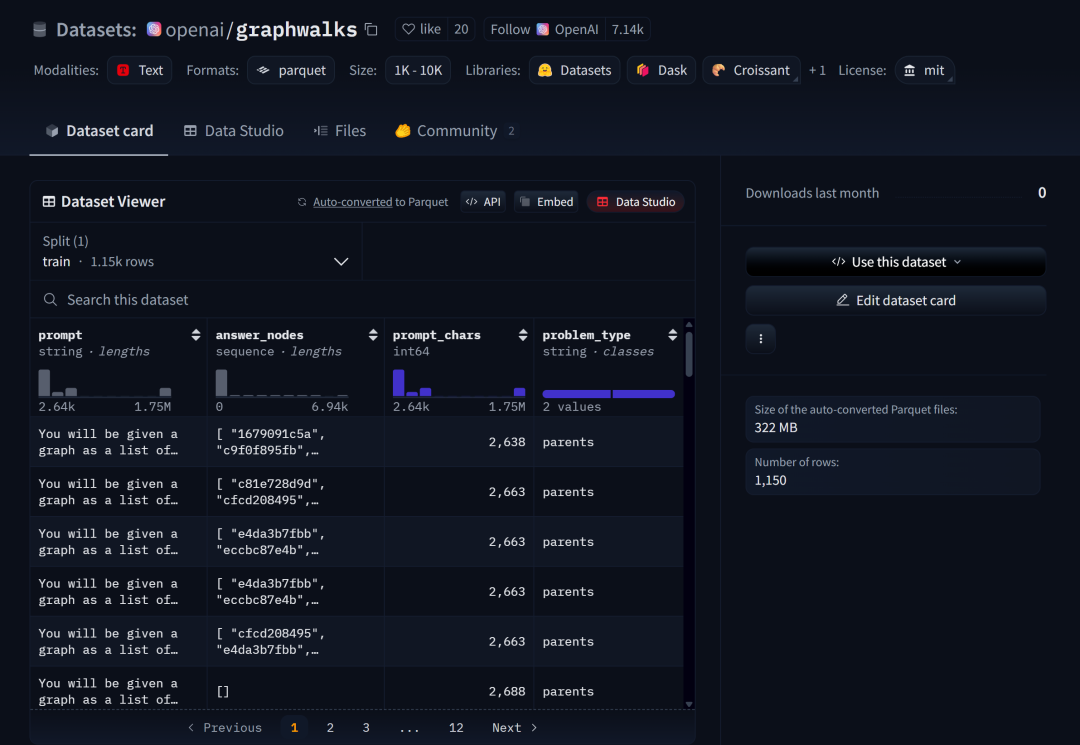
这两个数据集用以用于验证模型对于高相似问题的跨段落检索的能力,例如要“在一本诗集中查找顺序第三次出现的关于春天的诗作的标题”,这其实是一个非常实用但同时又很难的检索需求。
OpenAI-MRCR数据集:https://huggingface.co/datasets/openai/mrcr
而在这种检索要求下,GPT-4.1模型仍能保持较高的准确率,可以说检索能力是非常强悍了。
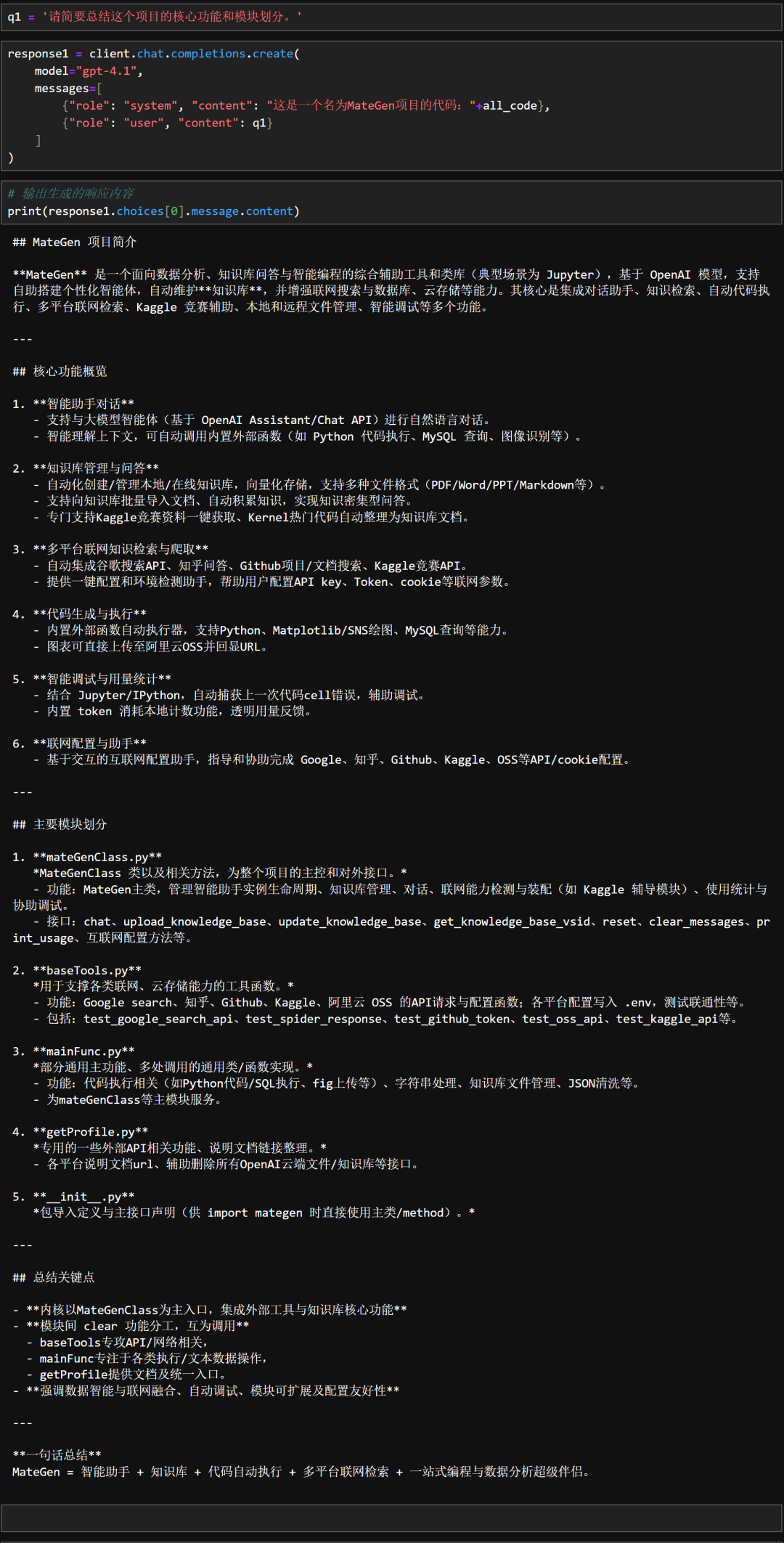
对此我们进行了实际测试,我将我们团队自主研发的AI数据分析智能体MateGen一部分源码、总共11万字符带入GPT-4.1模型中进行检索,
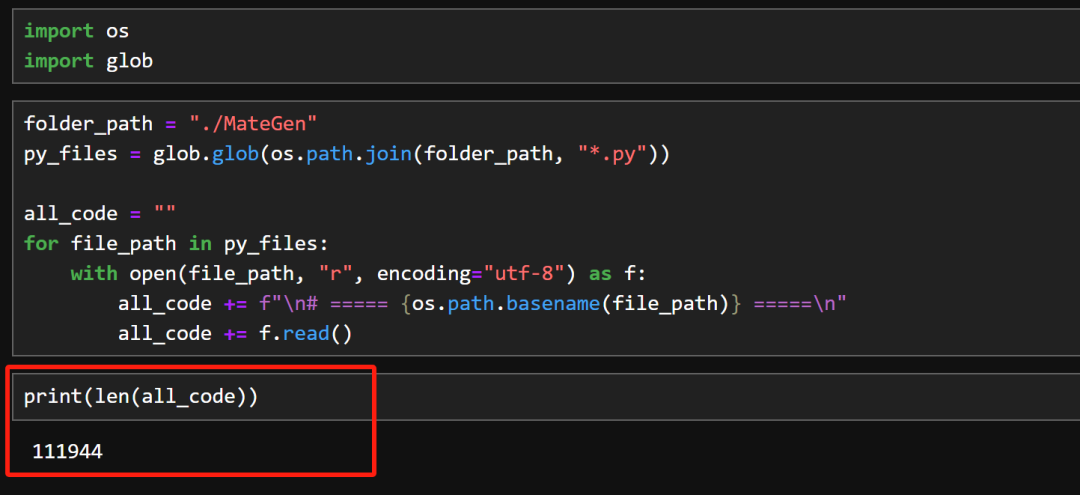
并且提问“帮我总结这个项目的核心功能和模块划分”,GPT-4.1回答如图所示。
看来代码逻辑关系难不倒它,那就再来个更“变态”的问题,我们让GPT-4.1“统计总共有几个函数,并总结彼此关系”,此时模型回答结果如图所示:

结果确实出乎意料,代码中90多个函数,GPT-4.1不到10秒就总结完了,而且函数彼此之间的依赖关系判断都非常准确,看来让模型一次性读懂一个复杂的开发项目肯定没有任何问题。
此外根据官网介绍,GPT-4.1在法律文档和财务数据文档中检索效果也堪称目前SOTA模型(最强模型),1M文档约30秒即可全部检索完成,整体性能非常强悍。

接下来我们再看模型的编程能力,还是以小球翻滚为例,GPT-4.1编程能力应该是GPT模型全系列最强,
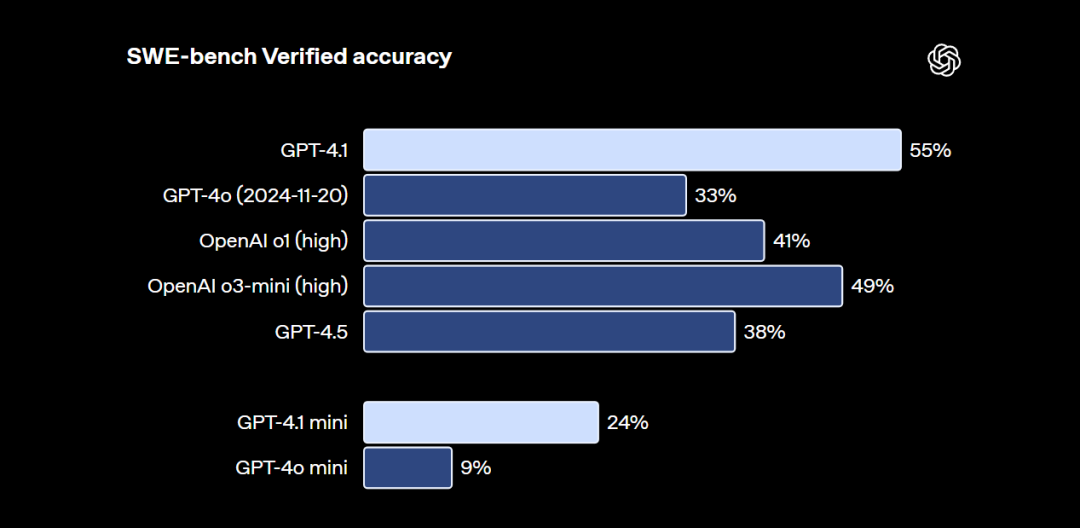
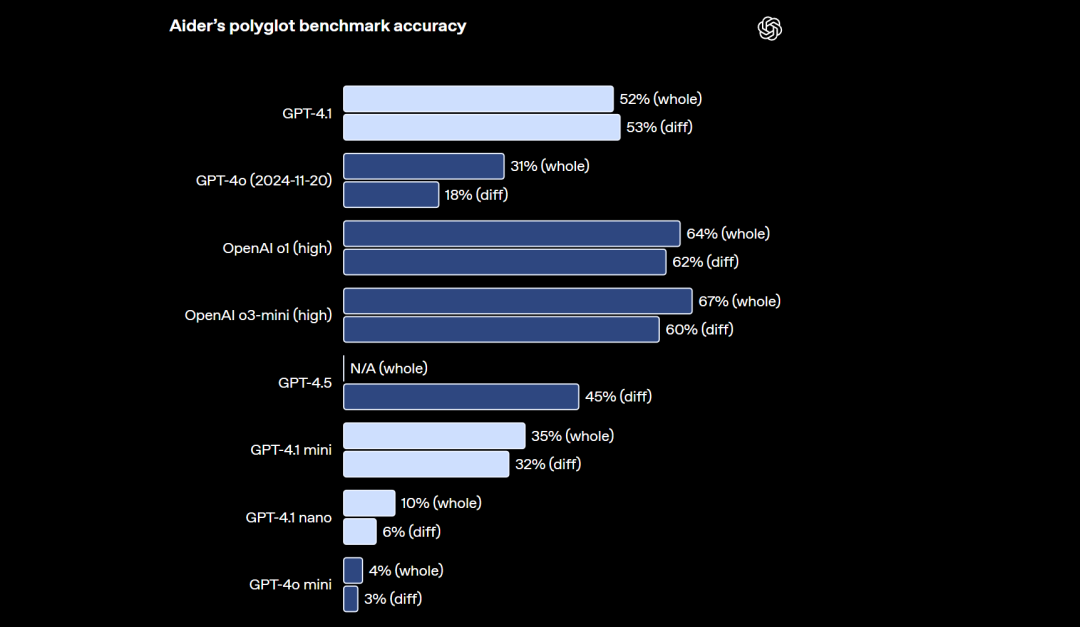
并且根据权威评测榜单,GPT-4.1在SWE-Bench中评分超过o3-mini(high)模型,但在Aider榜单中评分不如传统推理模型,也要弱于Gemini-2.5-pro和Claude 3.7模型。
不过呢,OpenAI再次敏锐的捕捉到了现阶程序员们对大模型编程的核心需求,那就是编写前端。因此GPT-4.1围绕前端代码开发这个具体场景进行了性能优化,能够更好的理解用户的意图,并且编写更加美观大方的前端。例如大家现在看到的就是我在Cursor中调用GPT-4.1模型,创建的一个单词抽认卡的前端展示效果,这是单独运行一次创建的结果,是不是效果非常不错。相关提示词包含在翻译的技术文档中,大家扫码即可领取。
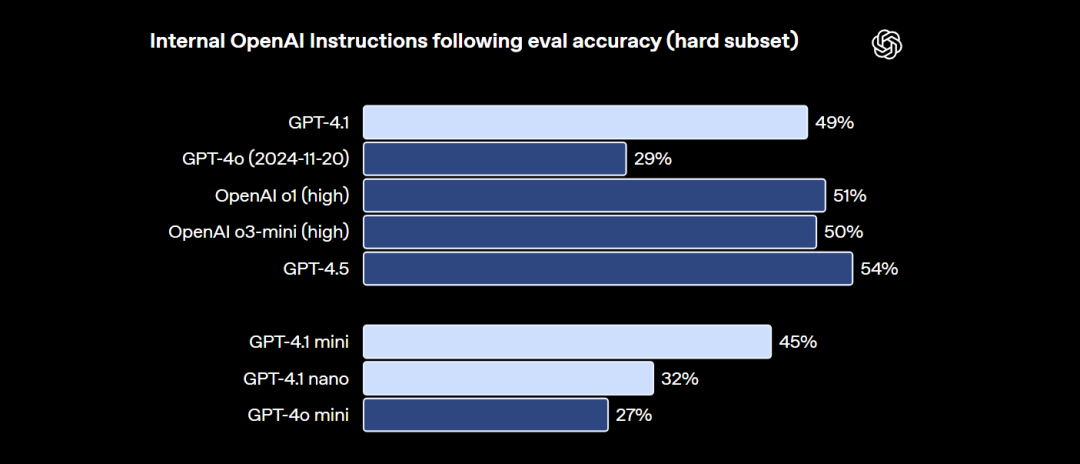
除了编程能力外,开发者往往还对大模型的指令跟随能力有较高要求。一个指令跟随能力更强的模型,外部工具识别准确率更高,Agent性能也会更强。而根据测试,新一代GPT-4.1模型几乎能达到GPT-4.5相同的指令跟随准确率,
我们也在第一时间将模型带入之前公开课讲解的手搓MiniManus项目中进行测试,
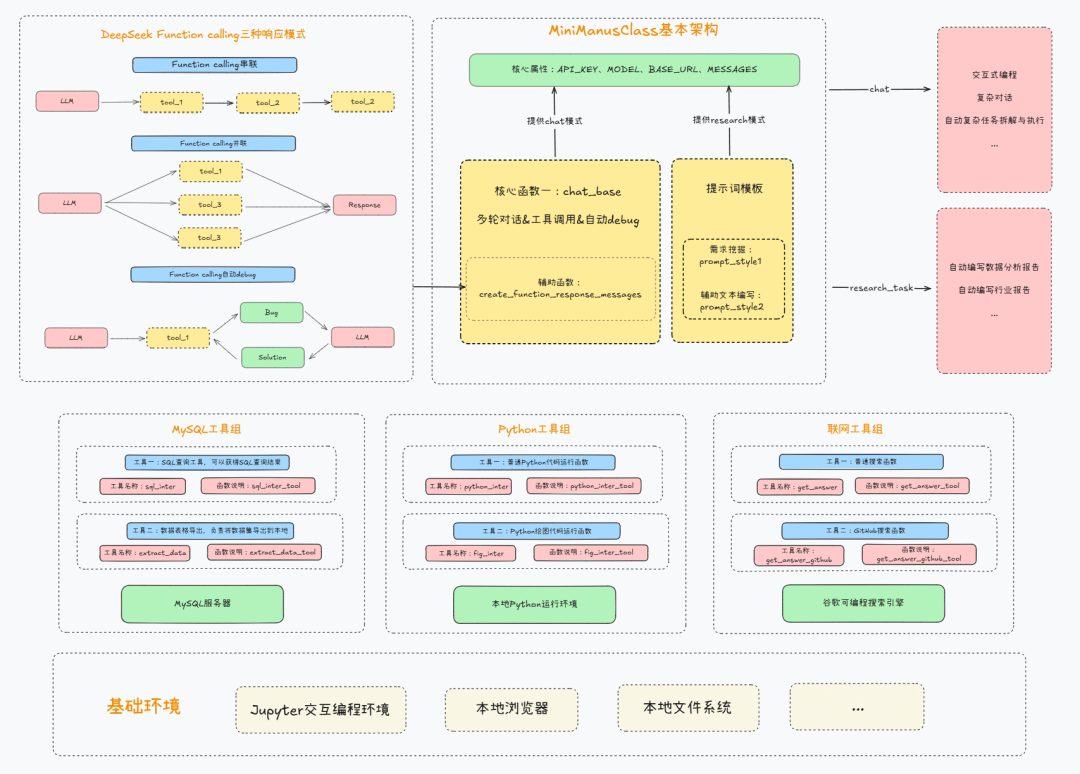
在多重意图匹配多项工具的情况下,GPT-4.1能自动编排工作流完成复杂任务,用户意图识别和工具调用准确率达到100%。
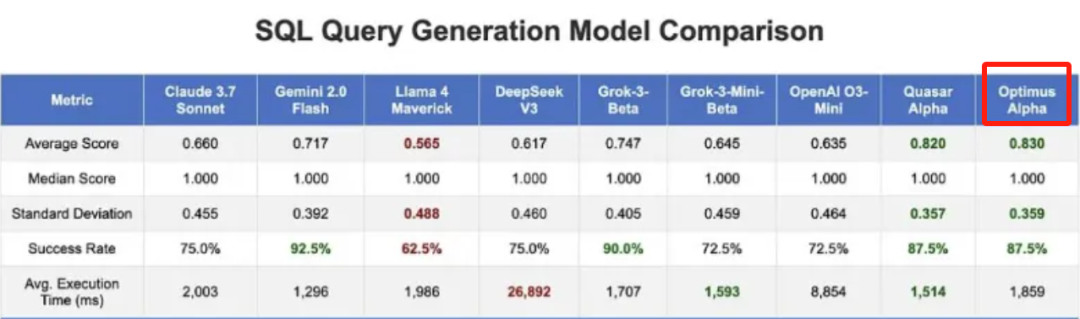
甚至啊,由于其强大的指令跟随能力,GPT-4.1还拿下了SQL代码编写排行榜的第一名,这又是一项非常实用的功能特性。
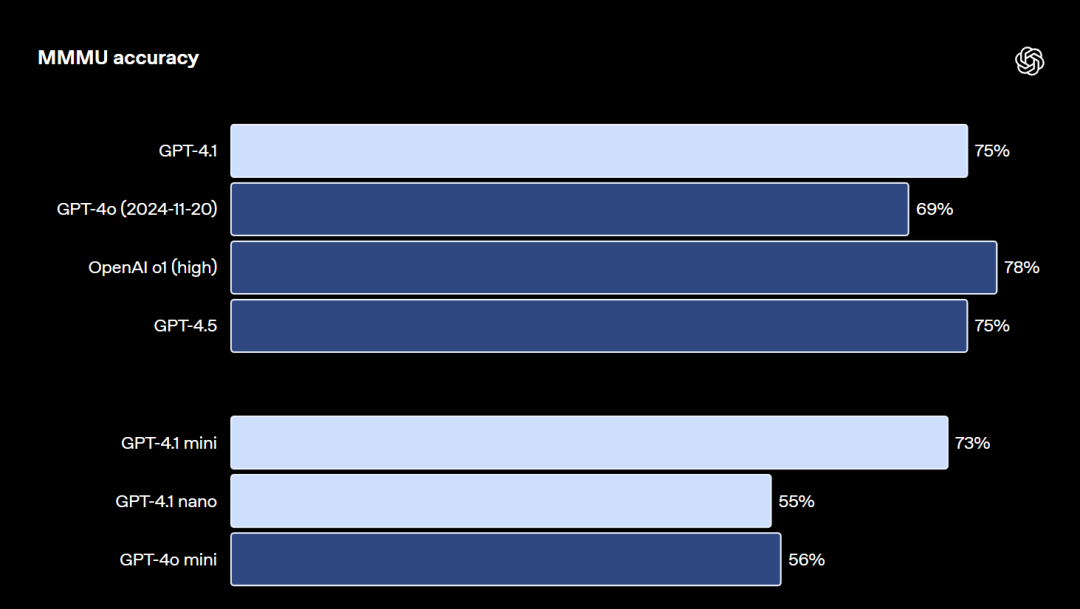
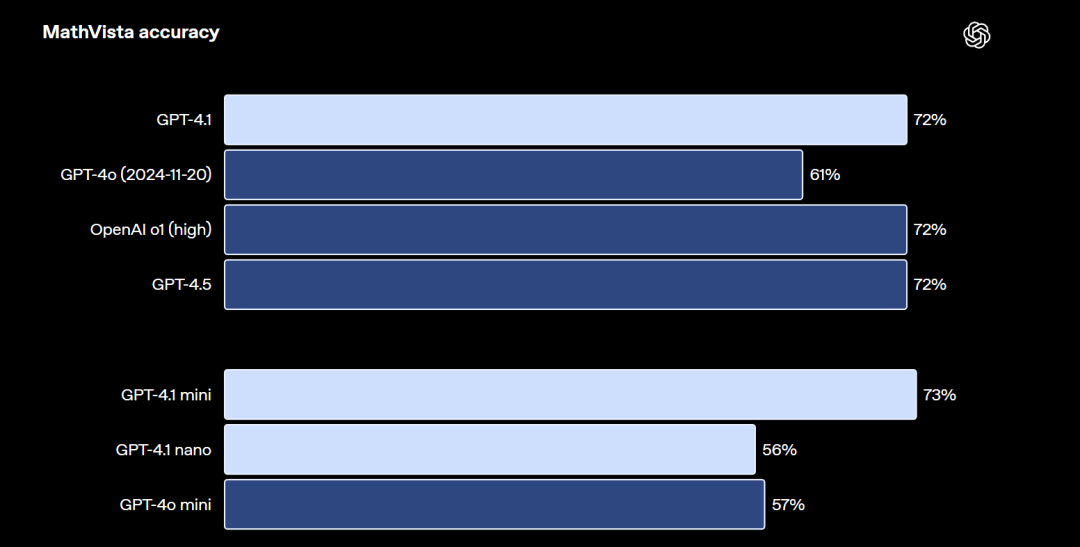
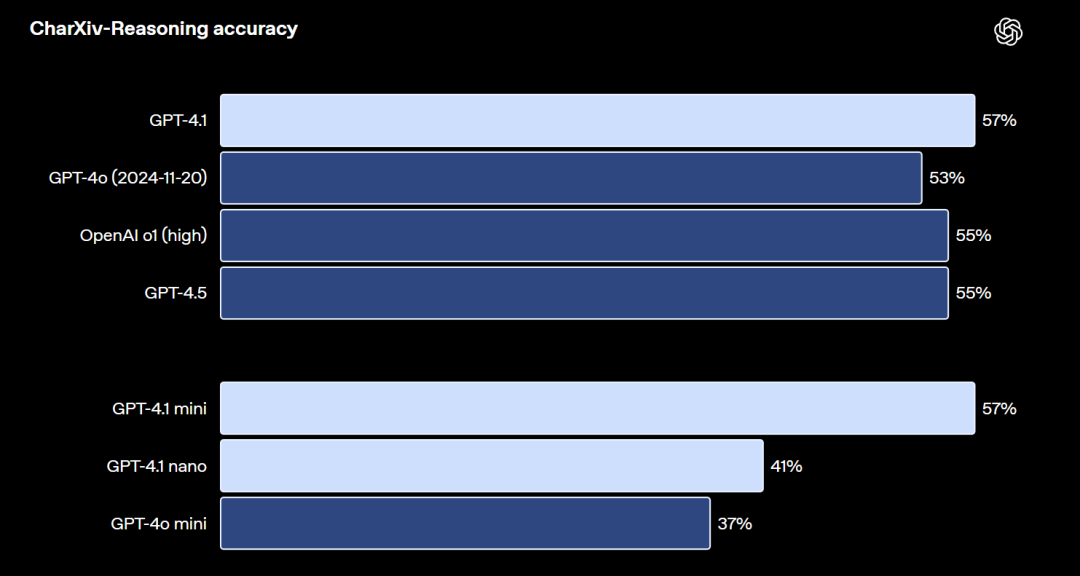
与此同时,GPT-4.1作为新一代旗舰模型,还具备强大的视觉推理能力,无论是通识问题、数学问题还是表格,GPT-4.1都能精准识别并进行解答,
通识问题识别与解答能力评分
数学问题识别与解答能力评分
表格识别能力评分
这里我们也进行了验证,让GPT-4.1识别之前谈到的MateGen项目完整流程图,
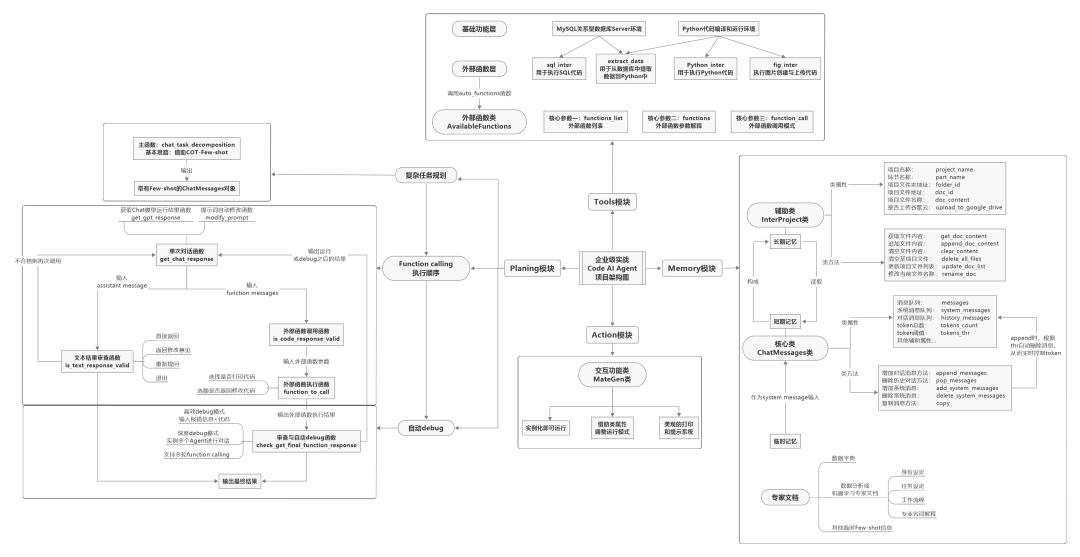
识别结果如图所示,可以说识别得非常精准,
并且,大家还记不记得我之前曾经把一个不完整的项目代码输入给了模型,接下来我让模型根据刚才流程图的识别结果,判断下我输入的代码缺失了哪些部分,
最终GPT-4.1模型列举了缺失的10个代码模块,回答仍然是全对。
而在拥有强大的文档检索、前端编程、指令跟随和视觉推理能力加持下,这次GPT-4.1模型定价,相比同级别Claude 3.7和Gemini 2.5 Pro还要低20%左右,可以说还是非常有性价比的,

此外,GPT-4.1 mini模型的定价和DeepSeek-V3接近,而小号模型则更便宜,百万输入仅需8毛,输出仅需3元。开发者在不同场景灵活使用不同模型,还能进一步节省成本。

整体来看,GPT-4.1绝对算得上当前顶流大模型之一,值得尝试使用。好了, 以上就是GPT-4.1模型深度解读的全部内容了,视频相关资料已上线至赋范大模型技术社区,同时,我们还为社区成员单独准备了一条直连OpenAI的专线,没有任何网络门槛即可使用官方API-KEY调用全系列GPT模型,大家扫码即可领取。
今年以来大模型技术发展势头迅猛,我也将持续为大家提供最前沿使用的技术教学,感谢大家的关注和三连支持。
📍更多大模型技术相关内容,⬇️请点击原文进入赋范大模型技术社区即可领取~

为每个人提供最有价值的技术赋能!【公益】大模型技术社区已经上线!
内容完全免费,涵盖20多套工业级方案 + 10多个企业实战项目 + 400万开发者筛选的实战精华~不定期开展大模型硬核技术直播公开课,对标市面千元价值品质,社区成员限时免费听!

















 551
551

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









