



七大场景 企业级RAG检索实战(附源码)
RAG 落地生产环境,如何解决 “检索准确性”(事实一致性/语境完整性/领域术语召回)和 “多模态解析”(PDF 图表、图片甚至视频)两大难题?
本文通过 Llama-Index 七大企业实战场景,全面解析高精准文本检索与Excel/PDF/视频全模态处理。拒绝理论空谈,全篇代码实战,完整源码可免费领取!
🛠️ Part 1. 快速热身:3分钟搭建 RAG 基线
在开始介绍进阶技术之前,我们先用最精简的代码跑通一个基础 RAG 流程。这几行代码在后台完成了 ETL、索引构建、检索生成的全流程。
1.1 环境准备
import os
from dotenv import load_dotenv
import llama_index.core
# 1. 加载环境变量
load_dotenv()
# 2. 检查 Llama-Index 版本
print(f"Llama-Index Version: {llama_index.core.__version__}")
1.2 加载数据与查询
import os
file_path = "./data/创新科技股份有限公司员工手册.txt"
with open(file_path, "r", encoding="utf-8") as f:
md_content = f.read()
# 预览前1000字符
md_content[:1000]

from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
# 1. 数据摄入 (Loading)
documents = SimpleDirectoryReader("data").load_data()
# 2. 索引构建 (Indexing)
index = VectorStoreIndex.from_documents(documents)
# 3. 引擎配置 (Query Engine)
query_engine = index.as_query_engine()
# 4. 执行查询 (Execution)
response = query_engine.query("请问,我们公司有病假政策么?请用中文进行回复。")
# 配置 LLM (如 GPT-4o)
from llama_index.core import Settings
from llama_index.llms.openai import OpenAI
base_url=os.getenv("BASE_URL")
api_key=os.getenv("OPENAI_API_KEY")
Settings.llm = OpenAI(
model="gpt-4o",
api_key=api_key,
api_base=base_url
)
🚀 Part 2. 拒绝断章取义:Small-to-Big 策略 (Sentence Window)
痛点:切片太小,LLM 看不懂上下文;切片太大,检索全是噪声。
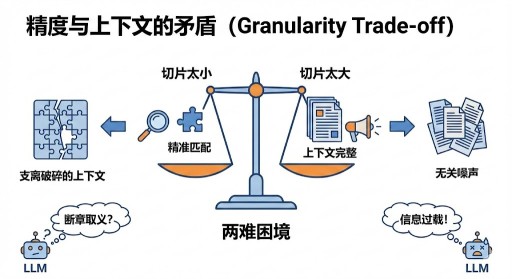
解法:“搜的时候用句子,给的时候用窗口”。索引时只存单句向量(保证精准),检索后将该句前后的上下文(大窗口)提供给 LLM(保证完整)。
2.1 核心代码
# 检查数据
if not os.path.exists("./data/创新科技股份有限公司员工手册.txt"):
print("❌ 错误:请确保 './data' 目录下存放了员工手册 txt 文件!")
else:
print("✅ 环境检查通过,正在加载数据...")
documents = SimpleDirectoryReader("./data").load_data()
print(f"📄 成功加载文档,共 {len(documents)} 页/部分。")
# === 构建进阶 RAG (Small-to-Big) ===
from llama_index.core.node_parser import SentenceWindowNodeParser
from llama_index.core.postprocessor import MetadataReplacementPostProcessor
import re
print("🚀 正在构建进阶 RAG 索引 (Small-to-Big)...")
# --- 🛠️ 关键修复:定义中文句子切分函数 ---
def chinese_sentence_splitter(text):
# 按中文标点切分,保留标点
return re.split(r'(?<=[。?!\n])', text)
# 1. 定义窗口切分器
node_parser = SentenceWindowNodeParser.from_defaults(
sentence_splitter=chinese_sentence_splitter,
window_size=3, # 核心:前后各取3句
window_metadata_key="window",
original_text_metadata_key="original_text",
)
# 2. 手动切分文档
nodes = node_parser.get_nodes_from_documents(documents)
print(f"🔪 文档被切分为 {len(nodes)} 个句子节点")
# 3. 建立索引 (对单句进行向量化)
advanced_index = VectorStoreIndex(nodes)
# 4. 创建引擎 (带偷梁换柱功能的后处理器)
advanced_engine = advanced_index.as_query_engine(
similarity_top_k=5,
node_postprocessors=[
MetadataReplacementPostProcessor(target_metadata_key="window")
]
)
print("✅ 进阶 RAG 系统就绪!")

2.2 效果对比
# === 效果对比展示 ===
from IPython.display import display, Markdown
# 建立一个普通 Baseline 对比
base_index = VectorStoreIndex.from_documents(documents)
base_engine = base_index.as_query_engine(similarity_top_k=2)
test_questions = [
"Q1: 如果我这个月迟到了 4 次,会受到什么样的具体处理?如果连续 3 天没打卡呢?",
"Q2: 我想周末和春节都来公司加班多赚点钱,工资分别怎么算?我一年最多能加多少小时班,有没有封顶?",
"Q3: 我还在试用期,最近家里有事想请半个月(15天)的假,按规定可以请吗?会不会影响我转正?"
]
def compare_answers(question):
response_base = base_engine.query(question)
response_adv = advanced_engine.query(question)
display(Markdown(f"### ❓ 提问: {question}"))
table_md = f"""
| 🤖 普通 RAG (Baseline) | 🚀 进阶 RAG (Small-to-Big) |
| :--- | :--- |
| {response_base.response} | {response_adv.response} |
"""
display(Markdown(table_md))
display(Markdown("---"))
for q in test_questions:
compare_answers(q)
🔍 Part 3. 拯救“搜不到”:混合检索 (Hybrid Search)
痛点:搜“ROWE工作制”或具体人名,向量模型完全懵圈,因为它只懂语义不懂字符。
解法:“左手向量,右手关键词”。结合 Vector Search(懂语义)和 BM25(懂字面),用 RRF 算法进行排名融合,专治各种生僻词和精准匹配。
3.1 核心代码
import nest_asyncio
import jieba
from typing import List
from llama_index.core.node_parser import SentenceSplitter
nest_asyncio.apply()
# 1. 定义中文分词函数 (给 BM25 用)
def chinese_tokenizer(text: str) -> List[str]:
return list(jieba.cut(text))
# 2. 切分文档
splitter = SentenceSplitter(chunk_size=512, chunk_overlap=50)
nodes = splitter.get_nodes_from_documents(documents)
# 3. 构建向量索引
vector_index = VectorStoreIndex(nodes)
# === 构建混合检索系统 ===
import inspect
from llama_index.retrievers.bm25 import BM25Retriever
from llama_index.core.retrievers import VectorIndexRetriever, QueryFusionRetriever
from llama_index.core.query_engine import RetrieverQueryEngine
print("🚀 正在构建混合检索系统 (Hybrid Search)...")
# --- 🛠️ 自动侦测 FusionMode 类型 (防御性编程) ---
try:
sig = inspect.signature(QueryFusionRetriever.__init__)
ModeEnum = sig.parameters['mode'].annotation
if hasattr(ModeEnum, 'RECIPROCAL_RANK'):
target_mode = ModeEnum.RECIPROCAL_RANK
else:
target_mode = "reciprocal_rank"
except Exception:
target_mode = "reciprocal_rank"
# 1. 创建 BM25 检索器 (字面匹配)
bm25_retriever = BM25Retriever.from_defaults(
nodes=nodes,
similarity_top_k=2,
tokenizer=chinese_tokenizer
)
# 2. 创建向量检索器 (语义匹配)
vector_retriever = VectorIndexRetriever(index=vector_index, similarity_top_k=2)
# 3. 创建融合检索器 (RRF 算法)
fusion_retriever = QueryFusionRetriever(
[vector_retriever, bm25_retriever],
similarity_top_k=4,
num_queries=1,
mode=target_mode,
use_async=True
)
# 4. 组装引擎
hybrid_engine = RetrieverQueryEngine.from_args(retriever=fusion_retriever)
print("✅ 混合检索就绪!")
3.2 效果对比
# 针对生僻词和实体的测试
questions = [
"Q1: 请问法务合规部的负责人是谁?我想发邮件给他,邮箱是多少?",
"Q2: 公司关于 BYOD (自带设备) 的具体政策要求是什么?",
"我是研发部的老员工,听说有个‘ROWE’工作制,具体需要满足哪些硬性条件才能申请?"
]
# 普通向量引擎
vector_engine = vector_index.as_query_engine(similarity_top_k=2)
def compare_hybrid(question):
response_base = vector_engine.query(question)
response_hybrid = hybrid_engine.query(question)
display(Markdown(f"### ❓ 提问: {question}"))
table_md = f"""
| 🤖 普通 RAG (Vector Only) | 🚀 混合检索 (Vector + BM25) |
| :--- | :--- |
| {response_base.response} | {response_hybrid.response} |
"""
display(Markdown(table_md))
display(Markdown("---"))
for q in questions:
compare_hybrid(q)
🚦 Part 4. 告别“一刀切”:智能路由 (Router Query Engine)
痛点:问细节(如“补贴多少钱”)需要精准切片,问总结(如“公司价值观”)需要全文档摘要。普通 RAG 只能二选一。
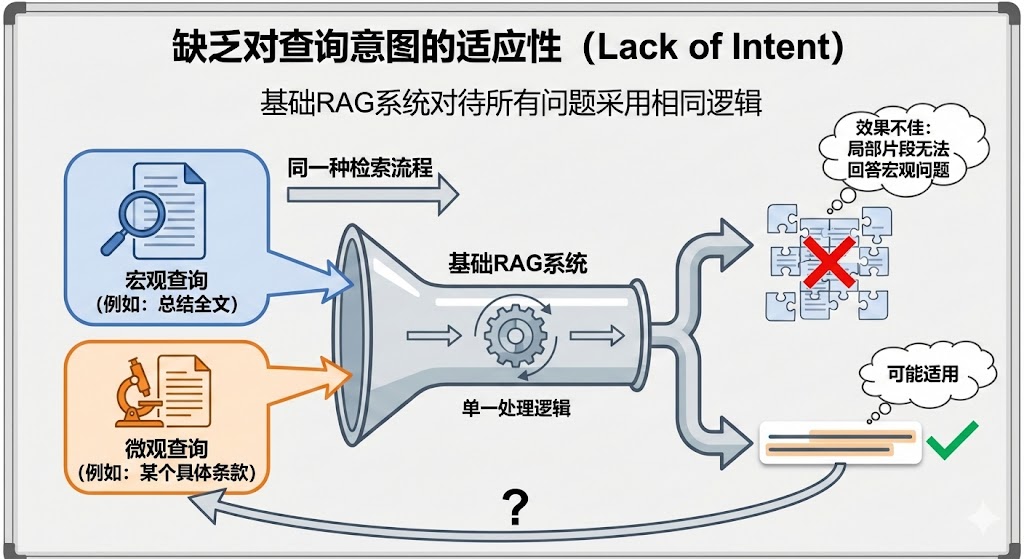
解法:“给系统装个大脑”。构建两个工具(细节工具 + 总结工具),让 Router 根据用户问题自动判断该派谁上场。
4.1 核心代码
from llama_index.core import SummaryIndex, VectorStoreIndex
# 1. 构建双索引
# 向量索引 (查细节)
vector_index = VectorStoreIndex(nodes)
# 摘要索引 (查全貌)
summary_index = SummaryIndex(nodes)
from llama_index.core.tools import QueryEngineTool
from llama_index.core.selectors import LLMSingleSelector
from llama_index.core.query_engine import RouterQueryEngine
# 2. 定义工具 (Description 是关键,写给 AI 看的)
vector_tool = QueryEngineTool.from_defaults(
query_engine=vector_index.as_query_engine(similarity_top_k=2),
description="专门用于查询具体的、特定的事实细节,例如补贴金额、电话号码、具体政策条款等。"
)
summary_tool = QueryEngineTool.from_defaults(
query_engine=summary_index.as_query_engine(response_mode="tree_summarize"),
description="专门用于对文档进行宏观的总结、概括全文主题、分析整体结构或提取跨章节的综合信息。"
)
# 3. 构建 Router 引擎
print("🚦 正在构建智能路由引擎...")
router_engine = RouterQueryEngine(
selector=LLMSingleSelector.from_defaults(),
query_engine_tools=[summary_tool, vector_tool],
verbose=True # 开启日志,看它怎么思考
)
print("✅ Router 引擎就绪!")
4.2 智能分发测试
questions = [
# 宏观总结题 -> 应该走 Summary Tool
"Q1: 这份员工手册主要包含了哪几个章节?请简要列出目录结构并概括每个章节的主题。",
# 微观细节题 -> 应该走 Vector Tool
"Q2: 公司的健身房补贴每年最高是多少钱?"
]
base_engine = vector_index.as_query_engine(similarity_top_k=2)
def clean_text(text):
return str(text)[:300].replace("\n", "<br>") + "..."
for q in questions:
display(Markdown(f"### ❓ 提问: {q}"))
response_base = base_engine.query(q)
response_router = router_engine.query(q)
table_md = f"""
| 🤖 普通 RAG (Top-2) | 🚦 智能路由 (Router) |
| :--- | :--- |
| {clean_text(response_base.response)} | {clean_text(response_router.response)} |
"""
display(Markdown(table_md))
display(Markdown("---"))
💡 中场小结:从文本到多模态
如果说前四章解决了“非结构化文本”的检索难题,那么接下来的四章,我们将挑战更复杂的数据形态——表格、PDF、图片和视频。让我们看看 LlamaIndex 如何“降伏”这些异构数据。
📊 Part 5. 让 RAG 看懂 Excel:Pandas 结构化数据分析实战
痛点:问“流失用户平均消费多少”,普通 RAG 只会搜文本,不会算数。
解法:Pandas Query Engine。它不是去搜答案,而是把自然语言翻译成 Python 代码,直接在 DataFrame 上执行运算,精准度 100%。
5.1 核心代码
import pandas as pd
from llama_index.experimental.query_engine import PandasQueryEngine
from llama_index.core import Settings
from llama_index.llms.openai import OpenAI
from dotenv import load_dotenv
load_dotenv(override=True)
Settings.llm = OpenAI(model="gpt-4o")
# 1. 加载数据
df = pd.read_csv("telco_data.csv")
# 2. 注入中文指令 (让 AI 用中文回答,且代码不许乱写)
chinese_instruction_str = (
"你是一位精通 Python Pandas 的数据分析专家。\n"
"你的任务是将用户的自然语言问题转换为可执行的 Python 代码,并基于执行结果回答问题。\n"
"请严格遵守以下规则:\n"
"1. 代码必须是有效的 Pandas 操作。\n"
"2. 代码的最后一行必须是一个返回结果的表达式,不要用 print()。\n"
"3. **最终结果必须强制使用中文回答**。\n"
)
# 3. 初始化引擎
query_engine = PandasQueryEngine(
df=df,
verbose=True, # 显示生成的代码,方便调试
synthesize_response=True, # 让 LLM 把运算结果翻译成人话
instruction_str=chinese_instruction_str
)
# 4. 复杂统计提问
query_str = "按合同类型(Contract)分组,统计流失和未流失用户的数量。"
print(f"❓ 问题: {query_str}")
response = query_engine.query(query_str)
print("\n🤖 分析结果:")
print(response)
print("\n💻 生成的代码:")
print(response.metadata["pandas_instruction_str"])
5.2 进阶:让 AI 画图
# 明确要求画图
query_str_viz = (
"Visualize the churn count by Contract type using a bar chart. "
"Use distinct colors for Churn vs Non-Churn. "
"Make sure to set the title as 'Churn Distribution by Contract Type'."
)
response_viz = query_engine.query(query_str_viz)
print("\n🤖 AI 已执行绘图操作")
📑 Part 6. 图表不再是盲区:MinerU + Qwen-VL 搞定复杂 PDF
痛点:PDF 里的架构图、统计表,普通解析工具直接丢弃,导致关键信息丢失。
解法:MinerU (解析) + Qwen-VL-Embedding (向量化)。先用 MinerU 提取出 markdown 和图片,再用多模态模型把图文都变成向量存起来。
6.1 定义 MinerU 解析器
import requests
import zipfile
import shutil
import os
from pathlib import Path
from typing import List
from llama_index.core import Document
from llama_index.core.schema import ImageDocument
class MinerUAPIReader:
def __init__(self, api_key: str, output_dir="./mineru_output"):
self.api_key = api_key
self.base_url = "https://mineru.net/api/v4"
self.output_dir = Path(output_dir)
def load_data(self, pdf_url: str) -> List[Document]:
# 1. 提交任务
print(f"🚀 [MinerU] 提交解析任务...")
headers = {"Authorization": f"Bearer {self.api_key}"}
data = {"url": pdf_url, "model_version": "vlm", "is_ocr": True, "lang": "auto"}
resp = requests.post(f"{self.base_url}/extract/task", headers=headers, json=data)
task_id = resp.json()['data']['task_id']
# 2. 轮询等待 (简化版代码,生产环境需增加超时处理)
import time
while True:
time.sleep(3)
status = requests.get(f"{self.base_url}/extract/task/{task_id}", headers=headers).json()['data']
if status['state'] == 'done':
result_url = status['full_zip_url']
break
# 3. 下载解压并封装 Document (代码略,见完整版)
return self._process_zip(result_url, str(task_id))
# _process_zip 方法实现略,核心逻辑是读取 full.md 和 images 目录
6.2 构建多模态索引与问答
from llama_index.core.indices.multi_modal import MultiModalVectorStoreIndex
from llama_index.llms.openai import OpenAI
# 1. 解析数据
reader = MinerUAPIReader(api_key=os.getenv("MINERU_API_KEY"))
documents = reader.load_data("https://example.com/tech_report.pdf")
# 2. 构建图文索引 (需自定义 Qwen Embedding 类,见完整版)
index = MultiModalVectorStoreIndex.from_documents(
documents,
embed_model=qwen_embed_model, # 文本向量化
image_embed_model=qwen_embed_model # 图片向量化
)
# 3. 多模态问答
llm = OpenAI(model="gpt-4o")
query_engine = index.as_query_engine(llm=llm, image_similarity_top_k=1)
response = query_engine.query("根据文档内容,LangChain 的整体架构包含哪几个核心层?请结合架构图进行说明。")
display(Markdown(f"### 🤖 AI 回答:\n\n{response.response}"))
🖼️ Part 7. 以图搜图:构建企业级多模态图片知识库
痛点:只有一张家具照片,想在产品库里找同款;或者想用文字搜“男士穿搭推荐”。
解法:CLIP / Qwen-VL 向量空间对齐。将图片和文本映射到同一个向量空间,计算 Cosine 相似度。
7.1 核心代码
from llama_index.core import SimpleDirectoryReader
from llama_index.core.indices import MultiModalVectorStoreIndex
# 1. 加载图片库
documents = SimpleDirectoryReader("test_images").load_data()
# 2. 构建索引
index = MultiModalVectorStoreIndex.from_documents(
documents,
image_embed_model=qwen_embed_model # 使用 Qwen2.5-VL
)
# 3. 文搜图
retriever = index.as_retriever(image_similarity_top_k=1)
results = retriever.text_to_image_retrieve("最近家里装修,希望推荐一些好看的家具")
# 4. 图搜图
results = retriever.image_to_image_retrieve("./test_images/query_chair.png")
🎬 Part 8. 视频也能 RAG:Twelve Labs 带来的时空对齐技术
痛点:传统方法把视频切成图片,丢失了动作连贯性和声音信息。
解法:Twelve Labs (Marengo/Pegasus)。专门为视频设计的向量模型,能理解“时空”概念,直接返回精确到秒的视频片段。
8.1 核心代码
from twelvelabs import TwelveLabs
# 1. 初始化客户端
client = TwelveLabs(api_key=os.getenv("TL_API_KEY"))
# 2. 创建索引 (Marengo + Pegasus)
index = client.indexes.create(
index_name="video_rag",
models=[
{"model_name": "marengo2.6", "model_options": ["visual", "audio"]},
{"model_name": "pegasus1.1", "model_options": ["visual", "audio"]}
]
)
# 3. 上传视频
with open("DeepSeek-V3.mp4", "rb") as f:
task = client.tasks.create(index_id=index.id, file=f)
client.tasks.wait_for_done(task.id)
# 4. 语义检索 (找片段)
results = client.search.query(
index_id=index.id,
query="找到解释模型架构的部分",
options=["visual", "audio"]
)
for clip in results.data:
print(f"🎬 片段: {clip.start}s - {clip.end}s (置信度: {clip.score})")
# 5. 生成式问答 (Pegasus)
answer = client.generate.text(
video_id=results.data[0].video_id,
prompt="DeepSeek-V3 的模型架构有什么创新点?"
)
print(f"🧠 AI 回答: {answer.data}")
🎯 总结与展望
从 Small-to-Big 的上下文窗口优化,到 Hybrid Search 的混合检索增强;从 Router Engine 的智能意图分发,到 Pandas Engine 的精准数据分析;再到 MinerU + Qwen-VL 的复杂文档解析、CLIP 的以图搜图以及 Twelve Labs 的视频理解。
我们通过七大实战场景,完整构建了一个能处理文本、表格、图片、视频的全能型 RAG 系统。LlamaIndex 强大的组件化设计,让我们能够像搭积木一样灵活组合这些核心技术。
RAG 的进化还在继续,希望这份指南能成为你打造企业级 AI 应用的坚实基石!

















 1306
1306

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









