




(5)limit优化
select * from tb_sku limit 1000000, 10; 当分页很大时,查询数据变慢。
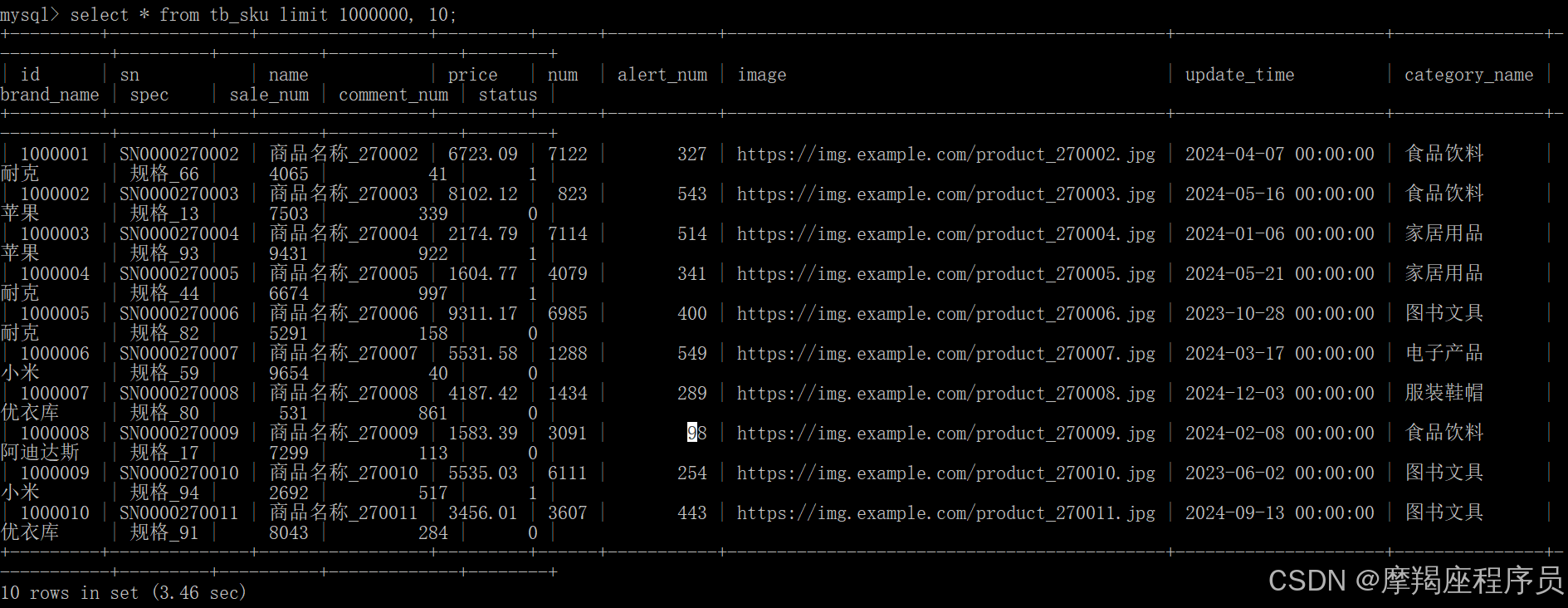
一个常见又非常头疼的问题就是 limit 2000000,10,此时需要MySQL排序前2000010记录,仅仅返回200000 ~ 2000010的记录,其他记录丢弃,查询排序的代价非常大。
通过覆盖索引的方式查询
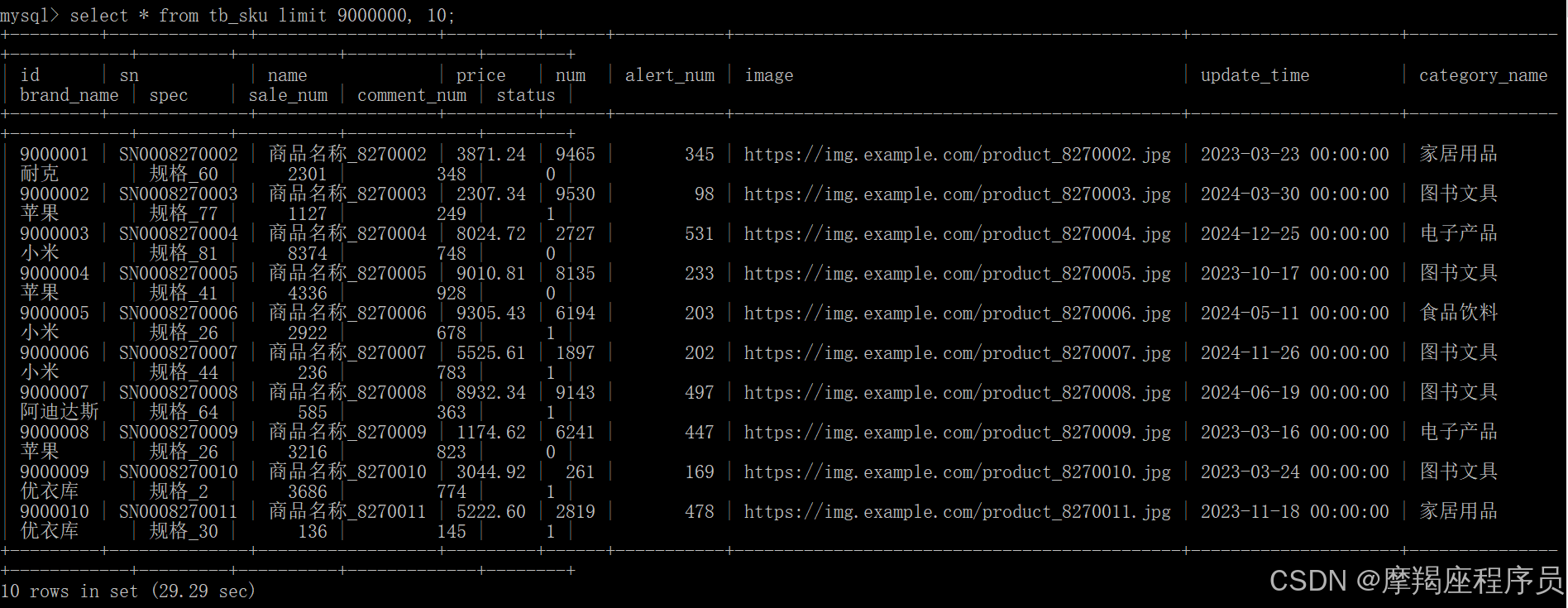
select id from tb_sku order by id limit 9000000,10;

比没有覆盖索引的查询快了很多:
通过子查询的方式,优化limit查询
select s.* from tb_sku s, (select id from tb_sku order by id limit 9000000,10) a where s.id=a.id;

一般分页查询时,通过创建覆盖索引能够比较好地提升性能,可以通过覆盖索引加子查询形式进行优化。
(6)count优化
MyISAM引擎把一个表的总行数存在了磁盘上,因此执行count(*)的时候会直接返回这个数,效率很高;
InnoDB引擎就麻烦了,它执行count(*)的时候,需要把数据一行一行地从引擎里面读出来,然后累积计数。
优化思路:自己计数
count的几种用法:
count()是一个聚合函数,对于返回的结果集,一行行地判断,如果count函数的参数不是NULL, 累计值就加1,否则不加,最后返回累计值。
用法:count(*)、count(主键)、count(字段)、count(1);
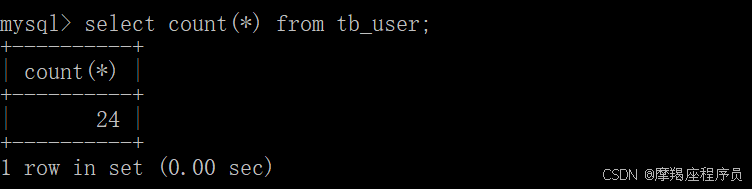
select count(*) from tb_user;
select count(id) from tb_user;
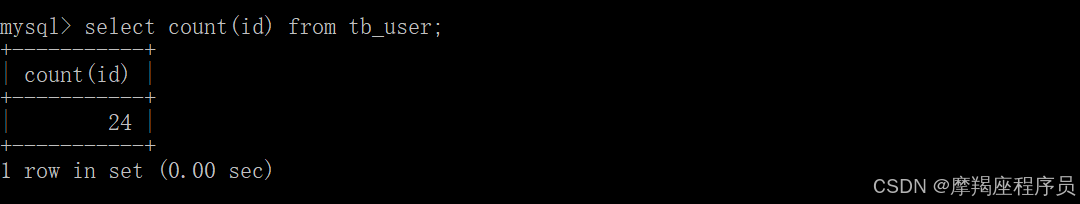
select count(profession) from tb_user;
count(字段)时,如果这行的字段是null,那么就不会被统计进去;这先将某行的profession字段设置为NULL;
update tb_user set profession=null where id=24;

再执行count(profession)
select count(profession) from tb_sku;
count(主键)
InnoDB引擎会遍历整张表,把每一行的主键id值都取出来,返回给服务层。服务层拿到主键后,直接按行进行累加(主键不可能为null)。
count(字段)
没有not null约束:InnoDB引擎会遍历整张表把每一行的字段值都取出来,返回给服务层,服务层判断是否为null,不为null,计数累加。有not null约束;InnoDB引擎会遍历整张表把每一行的字段值都取出来,返回给服务层,直接按行进行累加。
count(1)
InnoDB引擎遍历整张表,但不取值。服务层对于返回的每一行,放一个数字“1”进去,直接按行进行累加。
count(*)
InnoDB引擎并不会把全部字段取出来,而是专门做了优化,不取值,服务层直接按行进行累加。
按照效率排序的话:count(字段) < count(主键id)
(7)update优化
InnoDB的行锁是针对索引加的锁,不是针对记录加的锁,并且该索引不能失效,否则会从行锁升级为表锁。
插入数据:
insert:批量插入、手动控制十五、主键顺序插入
主键优化:
主键长度尽量短、顺序插入 AUTO_INCREMENT
order by优化
using index: 直接通过索引返回数据,性能高
using filesort: 需要将返回的结果再排序缓冲区排序
group by优化:
索引、多字段分组满足最左前缀法则
limit优化:
覆盖索引 + 子查询
count优化:
性能 count(字段) < count(主键) < count(1) ~ count(*)
update优化:
根据索引字段去更新,避免行锁变成表锁。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











