




大语言模型的本质是文字统计大师和模式识别高手,
LLM的全称是large language model,属于基础模型。
它并非”理解“语言,而是通过自监督学习,成为顶尖的文字统计与模式识别大师。
通过海里的数据, GPT-3 通过45TB的数据学习。45TB文本,相当于8万亿词,一个人需要数百年不眠不休才能读完。
为何大语言模型能写诗却算错数,那是因为它擅长模仿文字套路,却不具备人类的因果逻辑和真实世界的感官经验。
一个强大的模型等于海量优质的数据,加上精巧的架构,再加上科学的训练方法。
架构:Transformer, 其核心是”注意力机制“,赋予模型”上帝视角“,能同时关注句中所有词,动态判断关联性。
涌现能力:量变引发质变。
大语言模型擅长:
模式识别与信息处理:文本分类、情感分析、信息提取、高质量翻译等
内容生成与创意辅助:撰写文章、邮件、代码,以及头脑风暴
智能交互与对话:智能客服、虚拟助理、个性化教育辅导等;
第一个大坑: 幻觉
第二个大坑:常识与时效
第三个大坑:偏见与伦理问题
PMF: 理性应用,用对的锤子,敲对的钉子。
适合的场景:
(1)大量重复性的内容生成工作(如营销文案)
(2)需要快速原型设计的创意工作(如UI描述)
(3)繁琐的代码辅助与检查工作
(4)容错率较高的信息处理与对话
不适合的场景
(1)需要100%准确性的关键决策(如医疗诊断)
(2)需要最新实时信息的任务(如新闻报道)
(3)需深度专业判断和担责工作(如法官判案)
(4)涉及重大金融风险的自动化交易。
大模型微调
模型微调的概念:
通才模型的盲区,像百科全书,知识面广博,能谈天说地、写代码,但缺乏深度。根源在于”懂得多 ≠懂得精“。
模型微调,将通才塑造为专家。
模型微调的方法:
预训练模型,是通才,(通才)
模型微调,是注入领域数据,
微调后模型(专家)
第一步:参数优化
无需重训全部权重,仅调整1%~10%的关键参数,即可塑造专家模型。
LoRA技术: 通过低秩矩阵注入领域知识,如同给通才戴上一副“专家眼镜”,高效且低成本。
第二步:数据精炼
低效路径:海量泛数据
指望模型从维基百科、百度百科学习专业知识,如同大海捞针,效率低下且易产生幻觉。
高效路径:小而精数据
用1000条标准法律文书或1000条专业财报,直接告诉模型“什么才算对”
第三步:领域约束
天马行空:通用模型,自由发挥但易“胡说八道”;
绝对正确:约束后模型,输出可溯源,可验证
模型微调的策略:
策略一:QLoRA
针对硬件拮据场景,QLoRA通过量化(Quantization)与LoRA结合,
大幅降低训练门槛。显存占用减少90%,训练速度提升3-4x。
策略二:Prompt Engineering(提示词工程)
PE(Prompt Engineering)是微调的“前置试探”,先验证方向,再决定是否投入资源进行参数层面的“换锁”。
策略三:Llama Factory(微调界的万能工具箱)
LLaMA-Factory: Easy and Efficient LLM Fine-Tuning
支持:LoRA微调,全参微调,RLHF对齐。
大幅降低试错门槛,让零基础用户也能快速实验,对比方案。
模型微调的重要性:
“准、快、好”:
准:谁能精准满足专业场景需求,解决真实世界问题;
快:谁能快速迭代,以最小成本和周期交付可用模型;
好:谁能高质量落地、产生持续的商业价值和社会效益。
AI agent
参考读物:
-
《人工智能:现代方法》
-
《Intelligent agents:theory and practice》
-
《The rise and protential of large language model based agents: a survey>
-
《LLM Powered Autonous Agents》
LLM-based Agent的概念框架: 由大脑、感知、行动三个部分组成:
感知模块:负责感知和处理来自外部环境的多模态信息;
大脑模块:作为控制器,承担记忆、思考和决策等基本任务;
行动模块:负责使用工具执行任务并影响周围环境。
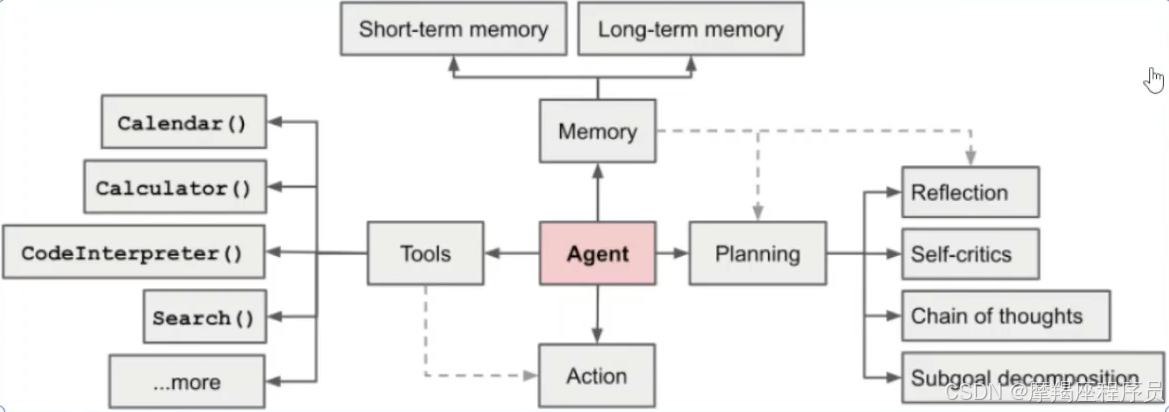
Agent=LargeModel + Memory + ActivePlanning + ToolUse
AI Agent vs AI助理聊天机器人 vs AI聊天机器人




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











