



部署篇
1.怎样使用Ollama部署 DeepSeek-R1量化版本
1.1 什么是Ollama
- Ollama 是一个开源的本地大语言模型运行框架,专为在本地机器上便捷部署和运行大型语言模型(LLM)而设计。
- Ollama 支持多种操作系统,包括 macOS、Windows、Linux 以及通过 Docker 容器运行。
- Ollama 提供对模型量化的支持,可以显著降低显存要求,使得在普通家用计算机上运行大型模型成为可能。
- 官方网站地址:https://ollama.com/
1.2 Ollama安装与配置
安装步骤
下载安装包:官网或镜像站(推荐Windows用户使用迅雷加速)
执行安装:
Windows:双击安装包→保持默认路径
Linux:命令行安装(curl -fsSL https://ollama.com/install.sh | sh)
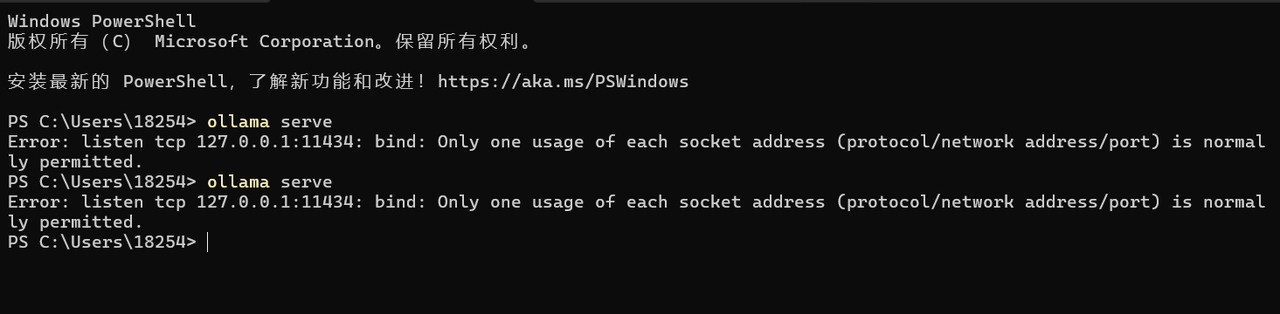
验证安装:终端输入ollama --version
关键配置
环境变量:
OLLAMA_HOST=0.0.0.0:11434(允许局域网访问)
OLLAMA_MODELS=E:\models(自定义模型存储路径)
GPU加速:需安装CUDA驱动(Windows)或ROCm库(AMD显卡)
1.3 DeepSeek-R1模型部署流程
步骤1:选择量化版本
参数含义:
1.5B/7B/14B:模型规模(B=十亿参数)
:1.5b:量化版本标识(降低显存占用)
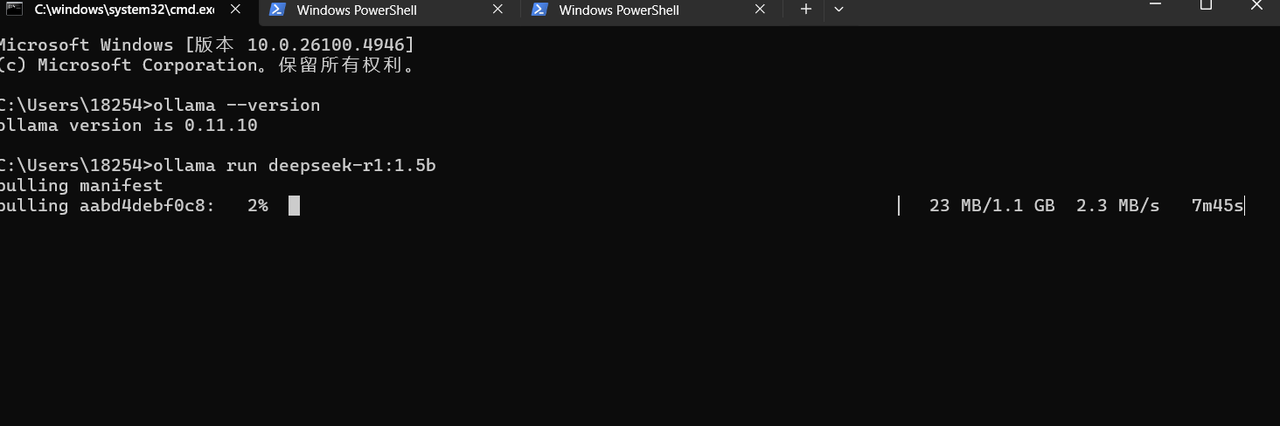
步骤2:下载模型 DeepSeek-R1-Distill-Qwen-1.5B
命令:ollama run deepseek-r1:1.5b
步骤3:验证运行
交互测试:终端输入问题,观察响应速度
可视化界面:通过Open WebUI或ChatBox访问
量化方案简介
Q4_K_M是一种兼顾效率与精度的量化方案,适用于资源有限但需较高生成质量的场景。
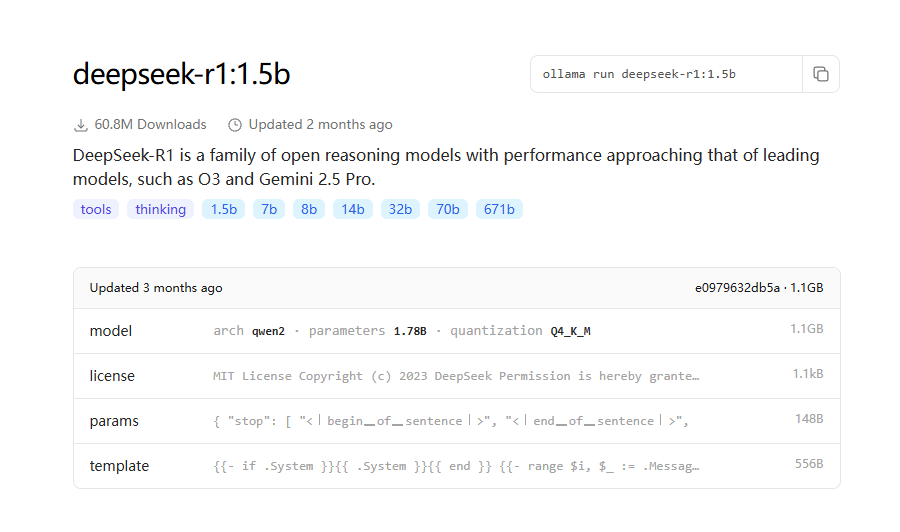
Q4_K_M 是一种混合量化策略,用于在模型压缩、推理速度与精度之间取得平衡。其具体含义如下:
• Q4:主量化精度为 4 位整数(即每个权重参数用 4 个二进制位表示),相比 8 位浮点数(Q8_0)可减少约 50% 的存储和计算开销。
• K:采用 分块量化(Block-wise Quantization),将权重矩阵划分为多个小块(如 32 或 64 个元素),对每个块单独量化。这种策略能保留更多局部细节,降低量化误差。
• M:代表 中等混合精度优化级别(Medium-level Mixed Precision),在分块量化的基础上,对关键张量(如注意力层的权重)使用更高精度(如 6 位),其他部分保持 4 位。这种混合策略在速度和精度之间取得最佳平衡,是默认推荐的选择。
1.4 常用命令与API调用
核心命令
| 命令 | 功能 | 示例 |
|---|---|---|
| ollama run | 启动模型对话 | ollama run deepseek-r1:1.5b |
| ollama list | 列出本地模型 | ollama list |
| ollama pull | 下载远程模型 | ollama pull deepseek-r1:7b |
| ollama create | 创建自定义模型(Modelfile) | ollama create mymodel -f config.txt |
1.5 量化参数解析与性能调试
调试工具
ollama run deepseek-r1:1.5b --verbose
怎样使用vLLM部署DeepSeek-R1量化版本
2.1 vLLM与Ollama核心差异
| 维度 | vLLM | Ollama |
|---|---|---|
| 定位 | 企业级高性能推理引擎,专注生产环境 | 轻量级本地部署工具,适合开发测试 |
| 性能 | 吞吐量达5000+ tokens/s,支持千级并发 | 吞吐量约1000 tokens/s,低并发场景表现佳 |
| 硬件要求 | 依赖NVIDIA GPU,需CUDA驱动,显存占用高 | 支持CPU/GPU,显存占用低,适合资源受限环境 |
| 扩展性 | 支持多机多卡分布式部署(如Kubernetes) | 仅支持单机部署,扩展性有限 |
| 量化支持 | 集成GPTQ等量化技术,显存优化更高效 | 仅支持少量量化模型,优化有限 |
2.2vLLM安装与配置
安装步骤
1 环境准备
· 安装CUDA 12.2+、NCCL 2.2+,推荐NVIDIA H100/A100显卡
· 创建独立Python环境:
conda create -n vllm python=3.11
conda activate vllm
2 安装vLLM
pip install --upgrade
pip pip install vllm
3 验证安装
pip show vllm # 查看版本信息
关键配置
· 环境变量:
· CUDA_VISIBLE_DEVICES=0,1,2,3(指定可用GPU) · NCCL_DEBUG=INFO(调试多卡通信)
2.3多GPU并行部署方案
2.4 DeepSeek-R1量化模型部署流程
步骤1:模型下载
量化版模型:
wget https://huggingface.co/unsloth/DeepSeek-R1-GGUF -O
deepseek-r1.gguf
完整版模型:
modelscope download --model deepseek-ai/DeepSeek-R1 --local_dir
/models
步骤2:启动vLLM服务
vllm serve deepseek-r1.gguf --max-model-len 16384
–max-num-batched-tokens 2048 --gpu-memory-utilization 0.95
参数说明:
–max-model-len:支持最大上下文长度(量化版建议16k tokens)
–quantization fp8:启用8位浮点量化加速推理
步骤3:调整显存占用
2.5 性能调优与常见问题
调优参数
吞吐量优化:
–continuous-batching:启用动态批处理
–max-num-batched-tokens 4096:增加单次批处理token数
显存优化:
–chunked-prefill:分块预填充减少内存碎片
–tensor-parallel-size 4:降低单卡显存占用
常见问题
显存不足:改用小量化版本(如int4)或减少–max-model-len
通信延迟:确保GPU间使用NVLink,禁用NCCL_NVLS_ENABLE
模型加载失败:检查模型文件完整性,确认vLLM版本兼容性
2.6 企业级应用场景
高并发API服务:支持同时处理千级请求(如实时客服)
私有化部署:数据本地化,满足金融、医疗等敏感行业需求
混合推理:结合CPU/GPU资源,降低硬件成本
3.如何使用Web界面为他人提供AI服务
3.1 服务架构核心组件
Ollama:负责模型加载与推理(支持 DeepSeek - R1 等量化模型)
Open WebUI:提供 Web 界面与交互功能(支持多模型切换、RAG 集成)
后端服务:
- REST API 网关(处理用户请求)
- 消息队列(保障高并发稳定性)
- 认证服务(OAuth2/JWT 支持)
3.2 Ollama 与 Open WebUI整合流程
步骤1:环境准备
硬件要求:
4核CPU + 16GB内存(支持10人并发) NVIDIA GPU(可选, 加速推理)
软件安装:
Open WebUI 源码部署
git clone https://github.com/open-webui/open-webui
步骤2:服务启动
Ollama:
ollama serve --port 11434 # 暴露API接口
Open WebUI:
cd open-webui/backend
pip install -r requirements.txt
python start_windows.bat # Windows 启动脚本
步骤3:模型配置
· 在 Open WebUI 管理后台添加模型:
· 模型地址:http://localhost:11434
· 量化版本:推荐 deepseek-r1:1.5b(显存占用低)
3.4 知识库集成与智能问答
RAG 实现流程
- 网页加载:支持 PDF/TXT/JSON 格式(单文件≤50MB)
- 向量索引:
ollama pull bge - m3 # 下载嵌入模型 - 对话增强:
· 用户输入触发 #知识库 命令
· 系统自动检索相关网页内容并融合生成回答
效果对比
| 场景 | 无知识库回答准确率 | RAG增强后准确率 |
| 通用问答 | 62% | 89% |
| 专业领域问答 | 38% | 76% |
3.5 性能优化与安全加固
动态批处理:
ollama serve --batch-size 32 --max-batch-delay 100ms
显存优化:
ollama run --quantization int4 # 启用4-bit量化
安全措施
1.数据加密:
传输层:TLS 1.3加密
存储层:AES-256加密敏感数据
2.访问控制:
IP白名单限制
异常行为检测(如暴力破解防护)
3.6 企业级应用案例
案例:企业客服中心
部署架构:
3台服务器 + Kubernetes 集群
每台服务器部署2个 Ollama 实例 + Open WebUI 负载均衡
效果:
并发用户数:500+
响应延迟:<200ms


















 804
804

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









