



概念篇
1.推理大模型与普通大模型
1.1 什么是推理模型
| 不同角度 | 观察到的结果 | 带来的影响 |
| 从直观感受来看 | 在输出最终回答之前,模型会先输出一段思维链内容,以提升最终答案的准确性。 | 过程透明 |
| 从发展历史来看 | 用自己的方法复现 OpenAI o1 模型 | 错误定位能力提升(用户可指 |
| 从架构上来看 | 集成规则引擎增强推理的可靠性,通过中间步骤(如数学推理中的分步计算)提升容错性,引入回溯机制修正错误推理分支,输出推理轨迹增强可解释性 | 分步呈现比黑箱输出更易验证(尤其关键领域如医疗诊断) |
| 从开源上来看 | 遵循 MIT License,开源周:“显卡超频”,“降低延时”,“通用矩阵”,“负载均衡”,“数据加速”等 | 可私有化部署,并提升Infra能力 |
1.2 推理模型与通用大模型的应用场景有什么差异
- 并非所有计算都适配推理模型
- 推理大模型(如 DeepSeek - R1、OpenAI O1)会把复杂代码任务拆解为多步骤逻辑链。这种分步推理模式与人类程序员的思考过程相似,有助于降低代码逻辑错误的几率。
- 普通大模型(如 GPT - 4、DeepSeek - V3)更倾向于单次推理直接生成完整代码,可能会忽略中间逻辑验证环节,致使代码片段看似合理,实则存在隐藏缺陷。
- 可解释性在一次性问题上并无价值
- 推理大模型会输出详细的推理轨迹,这一特性对于开发者理解代码逻辑、教学场景以及代码评审都具有重要意义。
- 普通大模型通常直接返回最终结果,不过时效性更佳。
- 在代码生成过程中,需权衡资源消耗与响应效率
- 推理大模型由于要执行多步推理,生成代码的响应时间较长(约为普通模型的 3 - 5 倍),且计算资源消耗更高。例如,DeepSeek - R1 在生成复杂算法代码时,会激活更多专家模块(MoE 架构)以支持深度思考。
- 普通大模型响应速度更快,适合生成简单代码片段(如数据清洗脚本),但难以应对需要深度分析的场景。
1.3 推理大模型在开发领域是否可以完全替代普通大模型?
推理大模型通过分步逻辑验证和自我纠错机制,显著提升了代码生成的可靠性和可解释性,尤其适合复杂系统开发;而普通大模型凭借快速响应特性,仍是简单脚本编写的有效工具。
未来两者可能形成互补协作模式:推理模型负责架构设计与核心算法,普通模型辅助实现基础模块
| 场景 | 推理大模型优势场景 | 普通大模型适用场景 |
| 算法实现 | 动态规划、图论等复杂算法设计 | 简单数据处理脚本生成 |
| 代码优化 | 性能调优(时间复杂度分析、并行化改造) | 基础代码格式标准化 |
| 系统设计 | 微服务架构拆分、接口协议设计 | 单功能模块实现 |
| 异常处理 | 多线程死锁检测、分布式系统容错机制 | 基础异常捕获语法生成 |
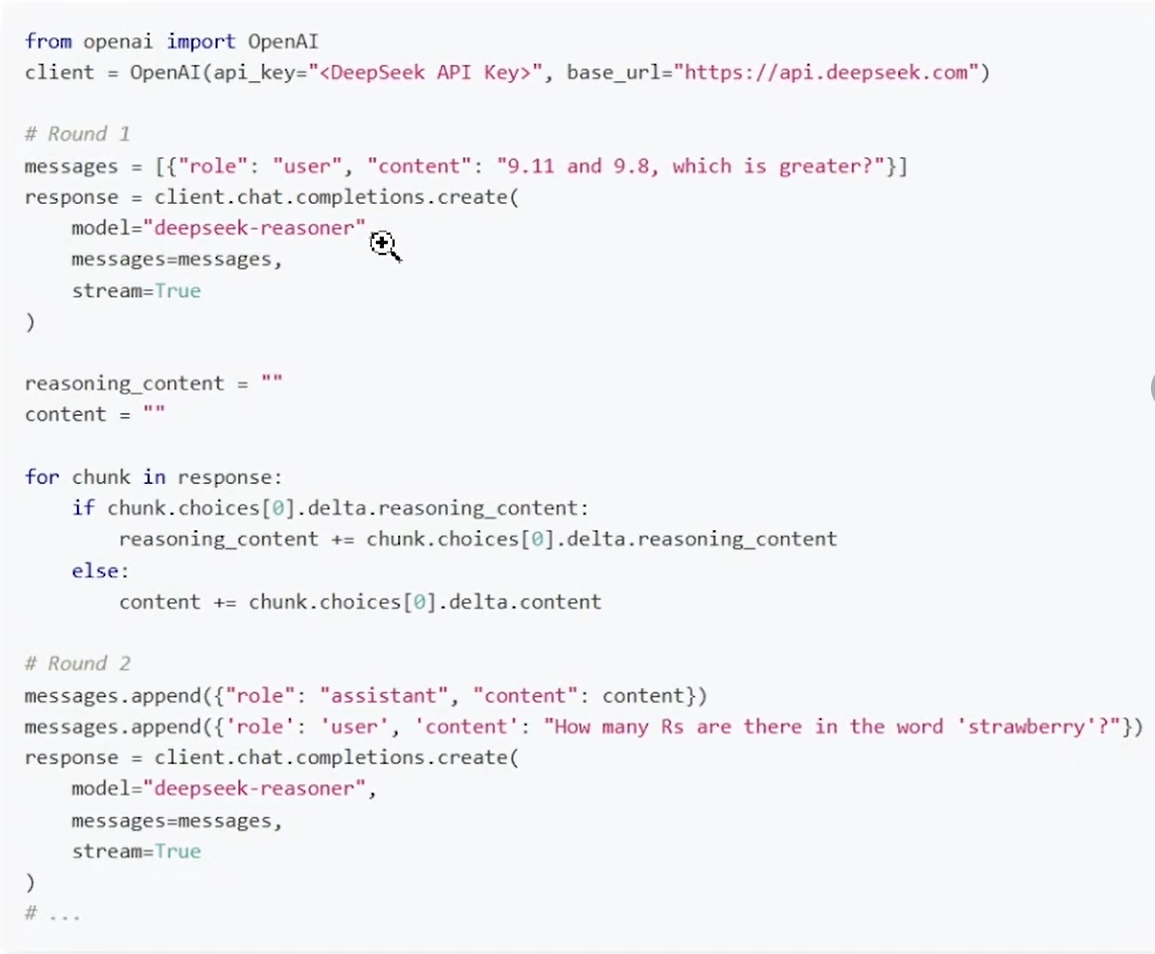
1.4 访问推理大模型的方式
- Chat对话方式访问DeepSeek R1
- 基于API访问 DeepSeek R1
1.5 如何从实用的角度来评测模型
| 关键指标 | 含义 |
| 首 Token 时间 | • 用户体验:决定用户首次感知的响应速度 |
| 总耗时 时间 | • 服务效率:直接影响业务吞吐量与终端用户等待时长。 • 资源利用率:关联计算成本与规模化能力。 |
| 输出 tokens/s | "• 处理能力:衡量系统实时性能与业务承载上限。 |
| • 成本效益: | 高吞吐量可摊薄单位请求成本。" |
| 共调用 tokens | • 资源消耗:直接关联算力成本与预算规划。 |
**本质影响:**优化运营效率、控制成本、提升用户体验、支持规模化决策
小结
- DeepSeek - R1 在需要逻辑推理的场景生成结论和稳定性优于通用大模型
- 基于 Web 访问会因为资源紧张,出现无法访问等情况
- 借助公有云采用 API 方式能缓解无法访问的问题,仍要注意数据隐私和数据安全
2.如何最大程度发挥DeepSeek R1的优势
2.1 推理模式擅长的领域
DeepSeek-R1在数学、代码、自然语言推理等任务上,性能比肩OpenAI o1正式版。
思维链的可解释性: 通过生成清晰的推理步骤,直观展示复杂问题的解决逻辑,提升决策透明性。
结构化推理能力:将复杂问题分解为多层级逻辑框架,实现高效、系统化的分步推理与分析。
动态推理控制: 根据输入动态调整推理路径,灵活优化策略以应对实时变化或不确定性问题。
模型蒸馏:将复杂模型的推理能力高效迁移至轻量化架构,平衡性能与资源消耗,适配低算力场景。
2.2 思维链的可解释性
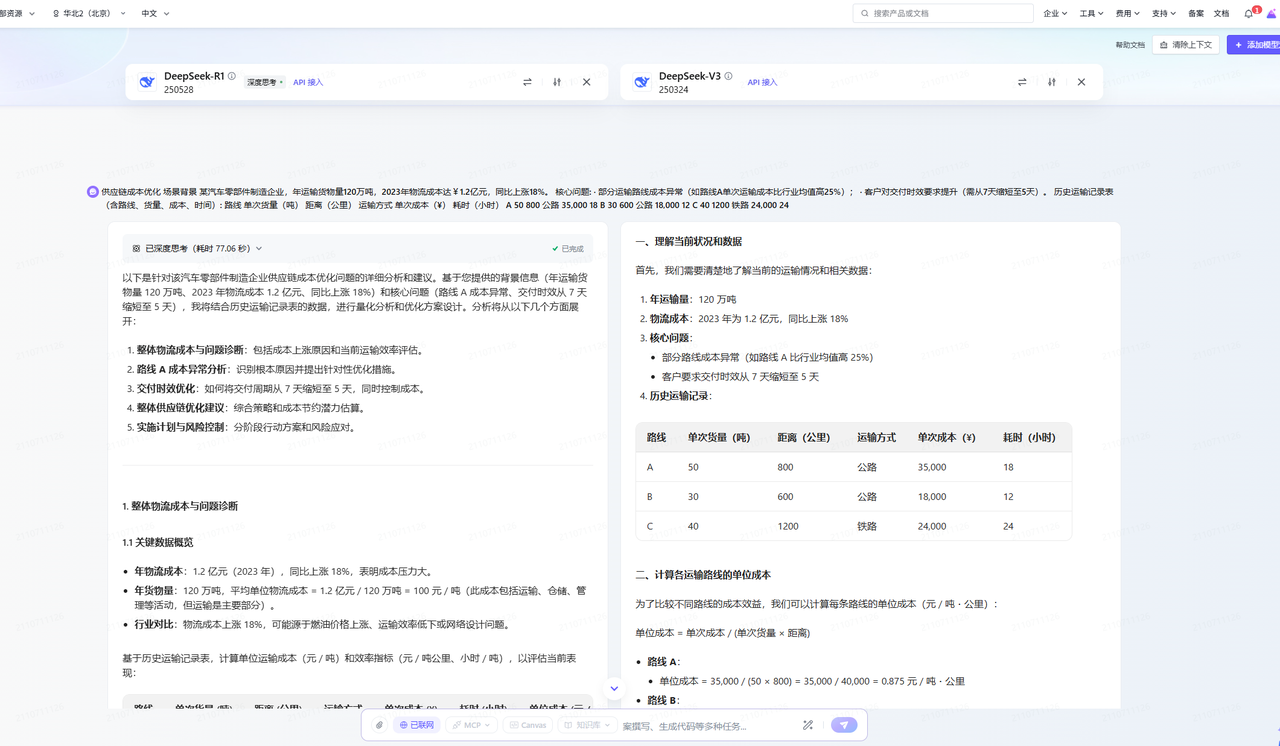
案例一:供应链成本优化
场景背景
某汽车零部件制造企业,年运输货物量120万吨,2023年物流成本达¥1.2亿元,同比上涨18%。
核心问题:
· 部分运输路线成本异常(如路线A单次运输成本比行业均值高25%);
· 客户对交付时效要求提升(需从7天缩短至5天)。
历史运输记录表(含路线、货量、成本、时间):
| 路线 | 单次货量(吨) | 距离(公里) | 运输方式 | 单次成本(¥) | 耗时(小时) |
| A | 50 | 800 | 公路 | 35,000 | 18 |
| B | 30 | 600 | 公路 | 18,000 | 12 |
| C | 40 | 1200 | 铁路 | 24,000 | 24 |
DeepSeek-R1 vs 通用大模型对比表
| 维度 | DeepSeek-R1 | 通用大模型 |
| 决策依据 | 数据聚类 + 动态成本模型,定位绕行导致的燃油损耗 | 基于历史语料库的泛化建议 |
| 方案细节 | 明确拆分铁路 / 公路段距离、成本、时效 | 仅提出 “多式联运” 概念 |
| 可执行性 | 提供中转操作指南及风险控制阈值 | 无落地细节 |
| 企业收益 | 节省¥220万 / 年 + 时效提升29% | 无法验证实际效果 |
核心结论:
DeepSeek-R1 通过结构化数据分解(如聚类分析)和动态成本建模,将抽象问题转化为可执行的优化动作(如缩短公路段 200 公里);通用模型缺乏对业务参数(燃油权重、中转耗时)的量化能力,导致建议难以落地。
2.3 结构化推理能力
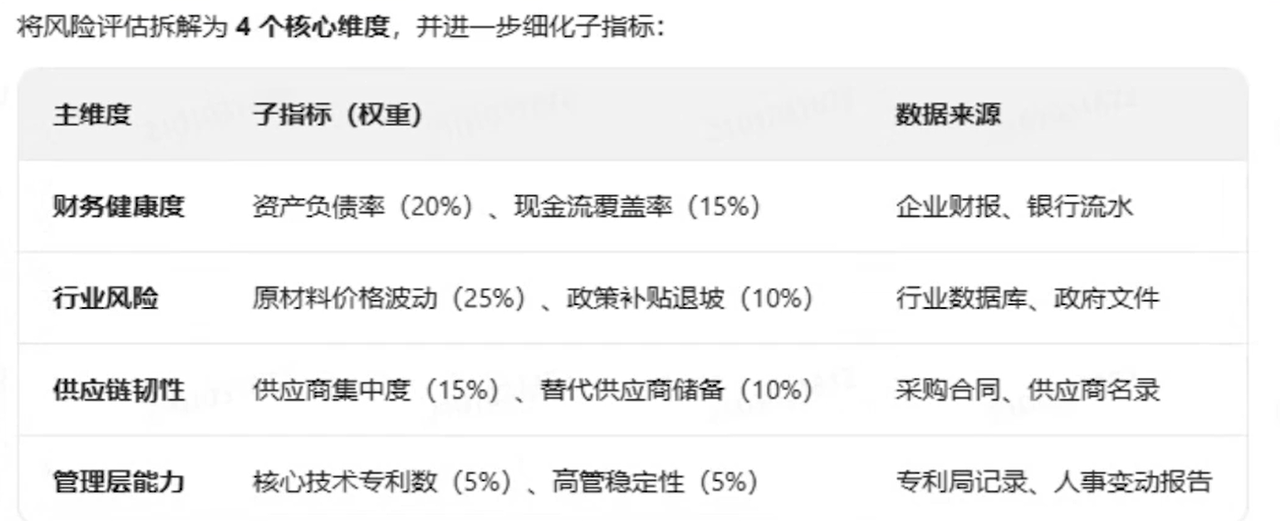
场景背景
某银行需评估一家新能源电池制造企业(年营收¥8亿)的贷款申请(¥1.2亿),需综合判断其偿债能力、行业风险及供应链稳定
核心挑战:
- 企业财务数据复杂(多子公司、海外业务占比30%);
- 行业政策波动大(如2023年锂价下跌40%);
- 供应链依赖关键原材料(钴)进口,地缘政治风险高
2.4 动态推理控制
2.5 模型的蒸馏
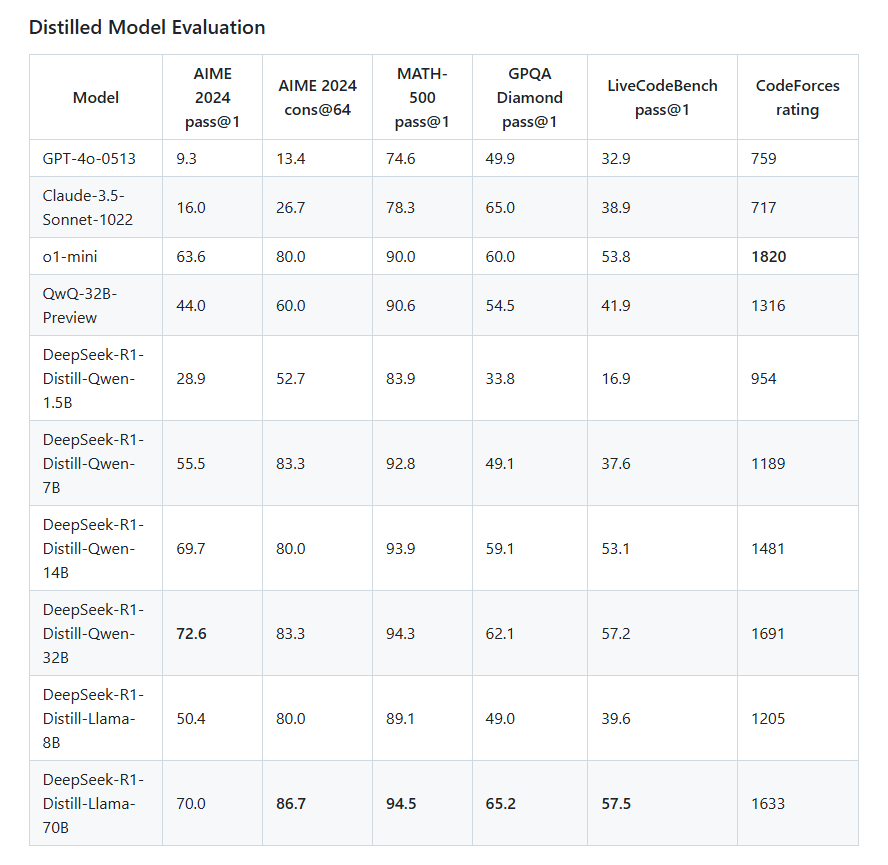
**满血版:**杭州深度求索人工智能基础技术研究有限公司开源 DeepSeek-R1-Zero 和 DeepSeek-R1 两个 660B 模型的同时,通过 DeepSeek-R1 的输出,蒸馏了 6 个小模型开源给社区,其中 32B 和 70B 模型在多项能力上实现了对标 OpenAI o1-mini 的效果。
蒸馏: 大模型蒸馏(Knowledge Distillation)是一种将大型复杂模型(教师模型)的“知识”迁移到小型轻量模型(学生模型)的技术。其核心目标是让学生在保持较高性能的同时,显著降低计算和存储成本。
a. 类比: 如同经验丰富的厨师(教师模型)通过传授火候掌控、调味技巧等隐性知识,让学徒(学生模型)无需完全复制操作细节,也能做出接近师傅水平的菜肴。
b. 蒸馏过程:
i. 教师模型训练:先训练一个高性能的大模型(如 DeepSeek-R1)
ii. 知识传递:教师模型对输入数据生成“软标签”(概率分布),而非简单的答案(硬标签),使学生模型学习到决策逻辑
iii. 学生模型优化:学生模型(如 Qwen)通过模仿教师模型的输出和中间特征,调整自身参数,最终实现轻量化部署
c. 注意:蒸馏后的模型仍属于 Qwen 底层架构(如网络结构、参数规模),但融合了 DeepSeek 的知识。DeepSeek-R1 的数学推理能力通过软标签和特征对齐迁移到 Qwen 中,使其在相同架构下表现更优。本质上蒸馏是“知识迁移”而非“架构替换”。类似于“学生继承了老师的解题思路,但大脑结构未变”
小结:
- 推理模型擅长可解释性和分步骤执行
- 资源受限时,可以采用蒸馏的方法降低计算和存储成本
基础使用篇
1.推理模型的提示词设计原则与优化策略
1.1 官方建议的提示词
GitHub - deepseek-ai/DeepSeek-R1
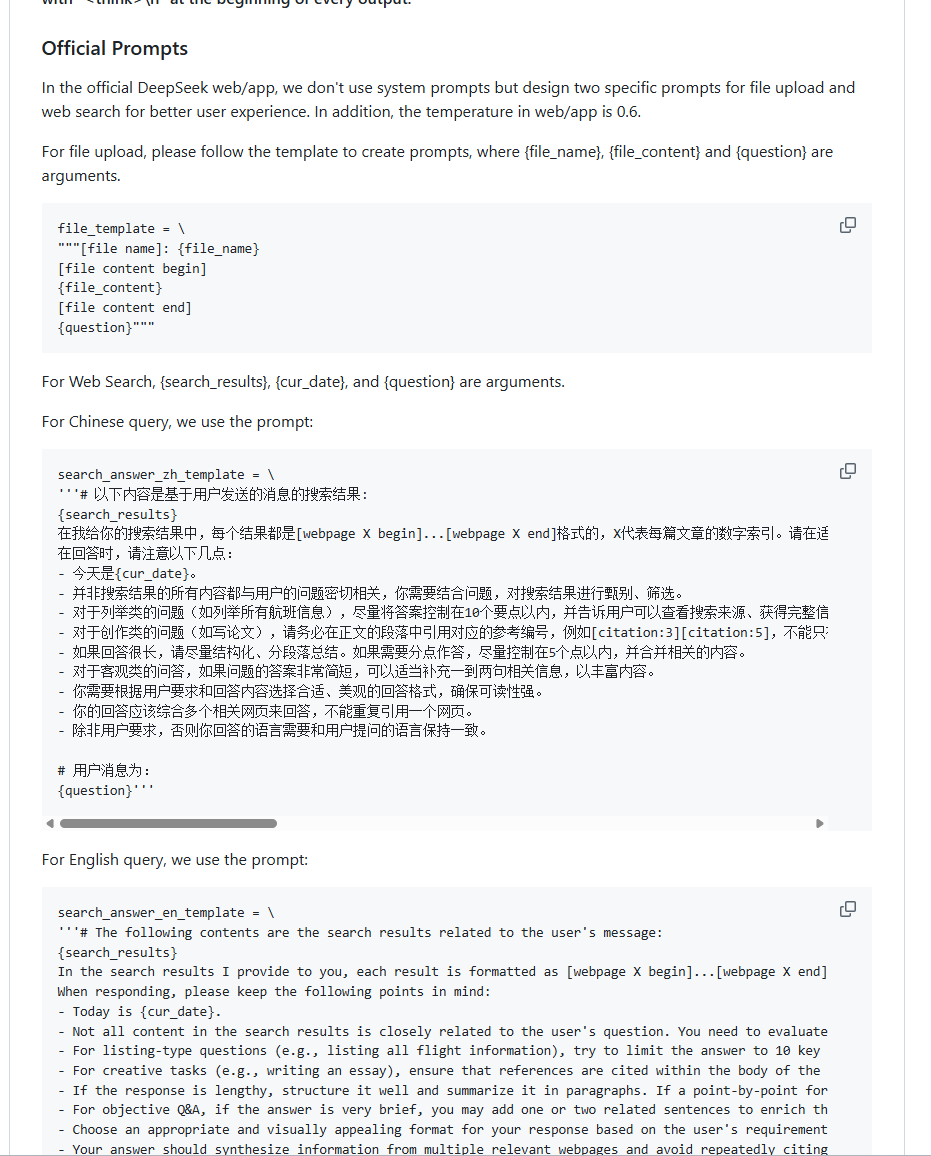
1.2 官方提示库
Prompt Library | DeepSeek API Docs
1.3.提示词公式
| 原则 | 优化表达 | 设计建议 |
| 使用口语表达 | 不必刻意设计思维链 | 直接说出你想要的效果,避免专业术语 |
| 目标导向沟通 | 先说“要解决什么问题” | 交代场景 |
| 动态难度调节 | 用“简单版/进阶版”区分 | 通过对话来设置开关 |
1.4 提示词对比
| 场景 | 通用大模型 | 推理大模型 |
| 小红书推广文案 | 你现在是小红书美妆赛道爆款写作专家,具备3年美妆行业内容运营经验,擅长将专业成分转化为通俗易懂的种草文案。品牌方计划在618大促期间推广一款玻尿酸面膜,目标人群是25 - 35岁职场女性,产品核心卖点是72小时长效保湿 + 便携次抛包装。请生成3个带emoji的爆款标题,并撰写500字正文。正文需包含使用场景(如出差急救)、成分解析(需用“玻尿酸小分子”等通俗表达)、价格锚点(原价199元/盒,活动价买二送一)。采用闺蜜聊天口吻,每段不超过3行,适当穿插“咱就是说”“救命这个真的绝了”等平台热词,重点语句用💧✨🔥等表情符号强化记忆点。首轮生成后,针对敏感肌群体增加“医美后修复”使用场景描述,调整标题中的数字具象化(如“28天逆袭水光肌”→“7天告别沙漠皮”)。 | 目标:为某国产抗老面霜创作带货文案核心需求:突出“平替雅诗兰黛”概念(价格仅1/3)植入实验室检测数据(28天胶原蛋白提升17.3%)设计3个互动话题:#你的第一瓶抗老霜# #国货真香现场#创作要求:开篇用“25+女生集合!”等唤醒句式中段穿插before/after对比图描述结尾设计“戳左下角get同款”转化钩子避坑指南:避免“顶级成分”等夸大宣传词,改用“实验室实测有效”等合规表述 |
小结:
- 推理模型的提示词范式不同于通用大模型
- 不必再遵循提示词公式,交代清楚核心需求和背景比公式更重要
2. 思维链、One-Shot等技巧对提示词效果的影响
2.1 思维链对模型生成效果的影响
| 通用大模型 | 推理大模型 |
| 不使用 CoT 的提示词效果使用 CoT 的提示词效果 | Reasoning 模型自带 Long CoT |
一些测试题
| 类型 | 题目 |
| 经济利润比例计算 | A商品利润增加20%后与B商品利润减少10%后的值相等。求原A商品利润是B的百分之多少? |
| 工程合作问题 | 甲、乙、丙三人共同完成一项工程。甲单独完成需18小时,乙需24小时,丙需30小时。若三人按“甲→乙→丙→甲→乙→丙…”的顺序轮流工作,每人每次工作1小时,问完成工程时乙总共工作了多少分钟? |
| 动态资源分配问题 | 水池中有泉水持续涌出,10台抽水机8小时可抽干,8台抽水机12小时可抽干。若用6台抽水机,需多少小时抽干? |
| 时间与效率综合题 | 钟表每小时慢3分钟,早晨4:30对准标准时间后,当钟表显示上午10:50时,实际标准时间是多少? |
| 概率及极值问题 | 口袋中有10个黑球、6个白球、4个红球,至少取出多少球才能保证有3个同色球? |
2.2 One-Shot 和Few-Shot机制
One-Shot 是为了让大模型更容易理解语境,提供的参考。通用大模型为了输出更稳定会采用比 One-Shot 更复杂的 Few-Shot
问题:上下文长度有限,无法确定要多少重复的格式会让大模型“意识”到正确的格式
- One-Shot提示:只提供一个例子。
- Few-Shot提示:提供几个例子。在提示中的作用是通过少量样本引导模型对特定任务进行学习和执行,例如通过提供少量风格或主题示例,引导模型产出具有相似风格或主题的创作。
2.3 推理大模型的提示词公式
| Goal | 明确的目标 |
| Return Format | 返回的格式(可选) |
| Warnings | 注意事项(可选) |
| Context Dump | 背景信息(可选) |
常见问题:如果 One - Shot 没激活特定的回答方式或格式怎么办?
追加法:用更容易理解的方式为我表达
预设法:假设你的表达对象是高中生,如何举例说明xxx
细化法:请继续为我补充xxx的细节
R1是军师,V3是猛将
R1是产品,V3是开发
R1是架构,V3是函数
R1别加戏,V3别偷懒
小结:
写好DeepSeek-R1模型的提示词要点:
1.简洁明了的提出你的要求
2.避免不必要的One-Shot或Few-Shot 实例
3.不必刻意让DeepSeek-R1展示或校验思考过程
4.避免冗余的"一步步思考"
3.怎样借助DeepSeek-R1编写与调试代码
3.1 代码的效率痛点
代码开发的效率痛点与AI工具的价值
**GitHub调查:**开发者平均30%的时间用于调试(2024)
**DeepSeek-R1定位:**集成代码生成/实时调试/智能补全的AI编程助手
两种代码生成方式
1.使用WEB方式生成代码
2.使用IDE集成 DeepSeekR1
3.2 实战流程:编写python代码的四个关键阶段
1.智能代码生成
2.运行和调试
3.实时错误检测与修正
4.交互式调试


















 1596
1596

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









