




 本文深入剖析YOLO(You Only Look Once)目标检测模型,分析其网络结构、原理及训练过程,指出YOLO在小目标检测和定位准确性上的局限性,并与Fast R-CNN进行对比,展示了YOLO在实时性和精度上的平衡。
本文深入剖析YOLO(You Only Look Once)目标检测模型,分析其网络结构、原理及训练过程,指出YOLO在小目标检测和定位准确性上的局限性,并与Fast R-CNN进行对比,展示了YOLO在实时性和精度上的平衡。
前言:
{
最近想了解以下目前比较先进的目标检测(object detection)模型和方法,所以就在github上搜到了https://github.com/amusi/awesome-object-detection,这里面介绍了不少目标检测的文章。
YOLO(You Only Look Once)我之前见过,可只是知道它是目标识别的方法,并且效果不错,但没有了解其具体过程。这次就来分析一下。
论文地址:https://arxiv.org/pdf/1506.02640.pdf
}
正文:
{
在一开始的第一节,论文描述了之前方法的缺点:至少被分为两个部分——框的生成和分类,并且需要分别的训练。YOLO却只通过一个网络生成框和类别,而且没有复杂的数学原理,使用的是神经网络的回归过程。
第二节介绍了其结构和原理。
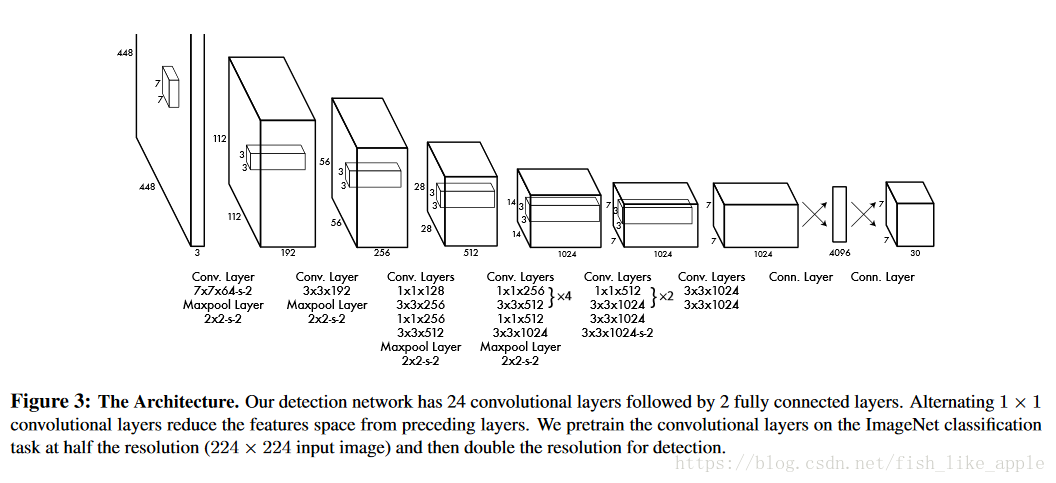
首先,输入图像被划分为S*S块网格,对每块网格都会生成B个框的预测和C个类的预测,每个框的预测包含x坐标,y坐标,宽度,高度h和置信度,网络的输出为S x S x (B*5 + C)的张量。具体结构可如图3:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 772
772

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









