




AsendC:A1->A2,B1->B2搬运优化
目前matmul A1->A2,B1->B2的搬运,均使用loadData的load2d接口来进行搬运。如下图的搬运流程。需要将A1中zN格式数据,搬运到A2中变成zZ格式的数据。
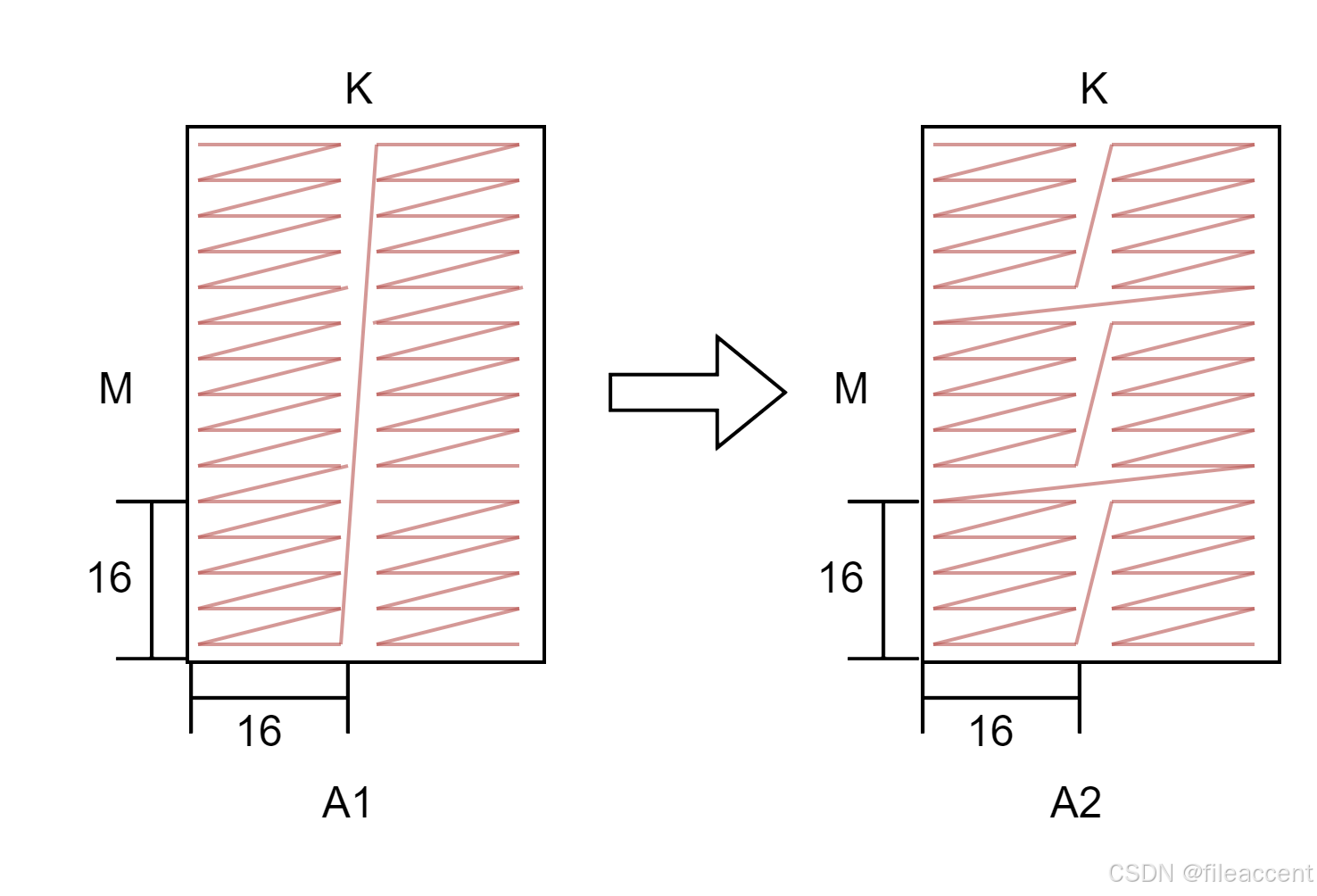
使用load2d指令搬运需要再M方向循环搬运。这样搬运会让内核scalar占比过高。后述介绍如何使用load3d接口来进行数据搬运。
for (uint32_t i = 0; i < M / 16; i++)
{
AscendC::LoadData(
dstTensor[i * K * 16],
srcTensor[i * 16 * 16],
AscendC::LoadData2dParams(
0,
static_cast<uint16_t>(K / 16),
M / 16,
0,
0,
false,
0));
}
load3d接口介绍
load3的接口的介绍可查看loadData接口介绍load3d可将卷积的输入数据,映射为矩阵乘法的形式。当然可完成矩阵乘法的数据搬运。
load3d指令需要设置寄存器,可通过SetFMatrix API设置。SetFMatrix介绍
SetFMatrix函数原型。
__aicore__ inline void SetFmatrix(uint16_t l1H, uint16_t l1W, const uint8_t padList[4], const FmatrixMode& fmatrixMode);
注意:
- 矩阵乘法计算时,需要将l1H设置为1。
- FmatrixMode 有FMATRIX_LEFT和FMATRIX_RIGHT两种。和load3d中的fMatrixCtrl对应。FMATRIX_LEFT对应fMatrixCtrl=0,FMATRIX_RIGHT对应fMatrixCtrl=1。原因:AsendC将load3d多余的参数放置在寄存器中,并给予了两套寄存器。分别给A1->A2,B1->B2使用。设置寄存器通常比较耗时,并且都为重复操作。在最开始设置,可减少寄存器开销。
下面介绍在矩阵乘法搬运中的四种情况。
情况一
将A1上zN的数据,转换为A2 zZ的数据。不需要转置矩阵。
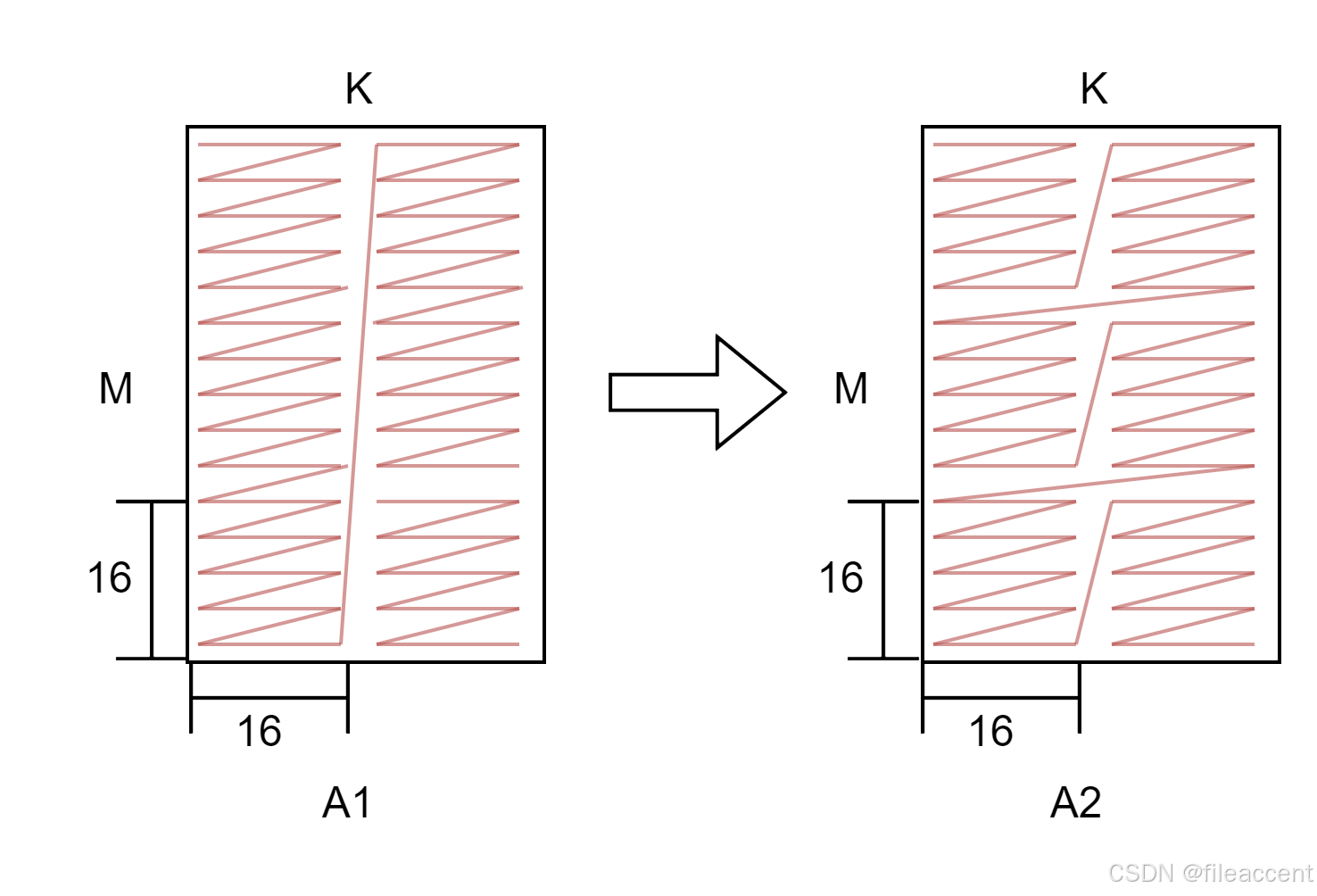
uint8_t padList[4] = {
0, 0< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2580
2580

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









