







 本文介绍如何使用Scrapy框架在Linux环境下安装相关依赖,并通过实战案例解析Scrapy的基本用法。从创建项目到爬取指定网站的数据,再到保存爬取结果,文章详细展示了整个爬虫流程。
本文介绍如何使用Scrapy框架在Linux环境下安装相关依赖,并通过实战案例解析Scrapy的基本用法。从创建项目到爬取指定网站的数据,再到保存爬取结果,文章详细展示了整个爬虫流程。
Linux下安装Scrapy相关依赖包
sudo apt-get install build-essential python3-dev libssl-dev libffi-dev libxml2 libxml2-dev libxslt1-dev zlib1g-dev
Scrapy基本用法
目标站点分析
http://quotes.toscrape.com/page/1/ 这是scrapy爬虫的最简单的网站,没有任何的反爬机制,可以直接通过get请求得到网页源码。
流程框架
- 抓取第一页:请求第一页的URL并得到源码,进行下一步分析
- 获取内容:分析源代码,提取首页内容,获取下一页链接等待进一步爬取
- 翻页爬取:请求下一页信息,分析内容并请求再下一页 链接
- 保存爬取结果:将爬取结果保存为特定格式如文本、数据库
爬取实战
1、创建scrapy项目
scrapy startproject quotetutorial
2、进入到scrapy项目中
cd quotetutorial/
3、创建spider
scrapy genspider quotes quotes.toscrape.com
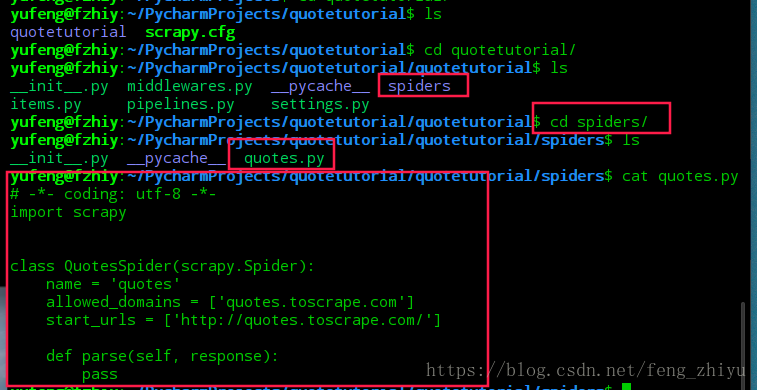
Scrapy框架的结构
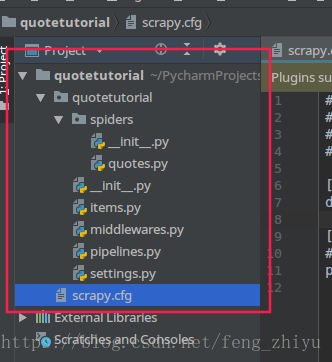
爬取信息运行的注意是spiders文件写的。
scrapy crawl quotes 运行scrapy。
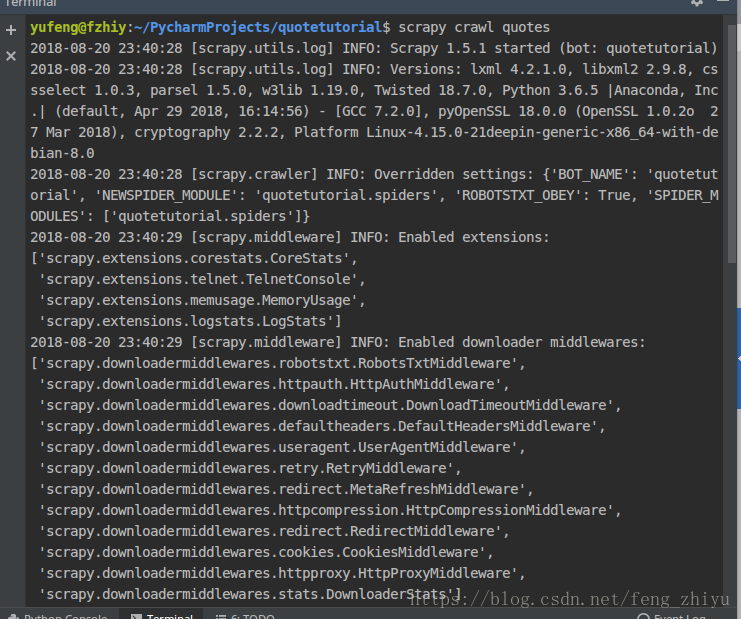
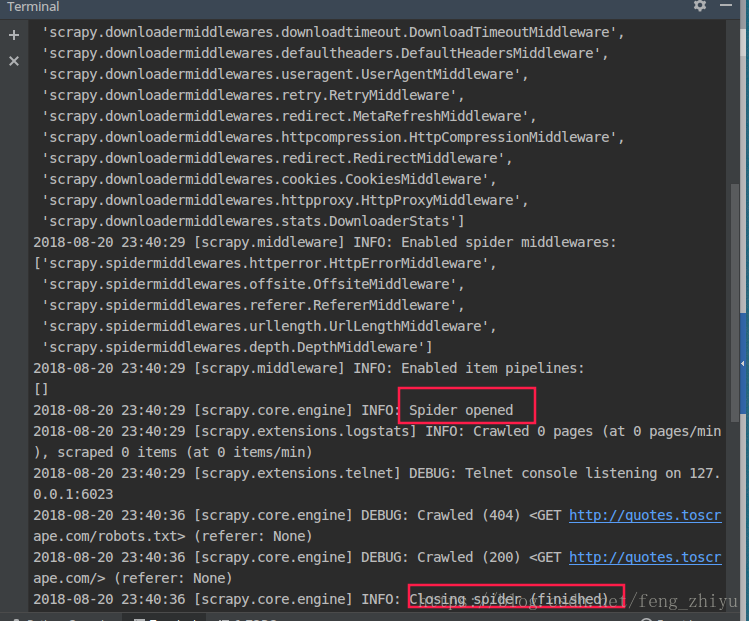
分析网页的html。
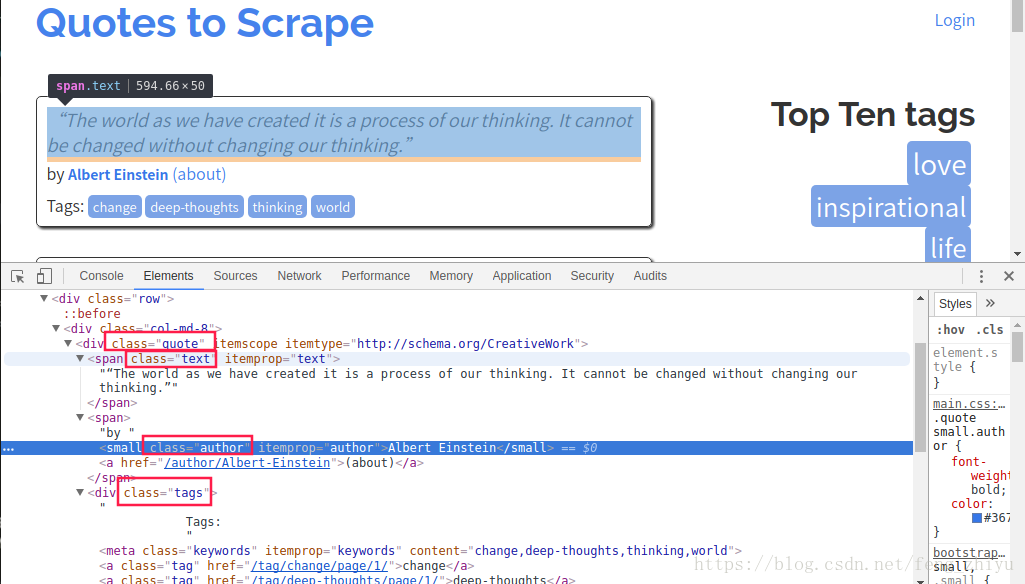
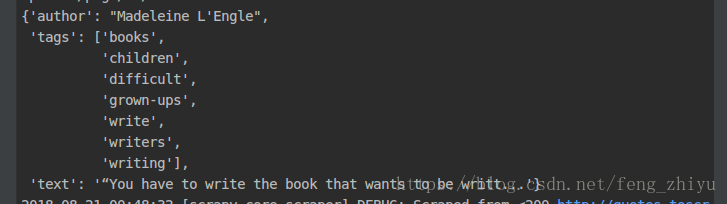
一句名言中的text、author、tags。
在Pycharm终端中输入scrapy shell quotes.toscrape.com进入交互模式。
格式:scrapy shell [网址]
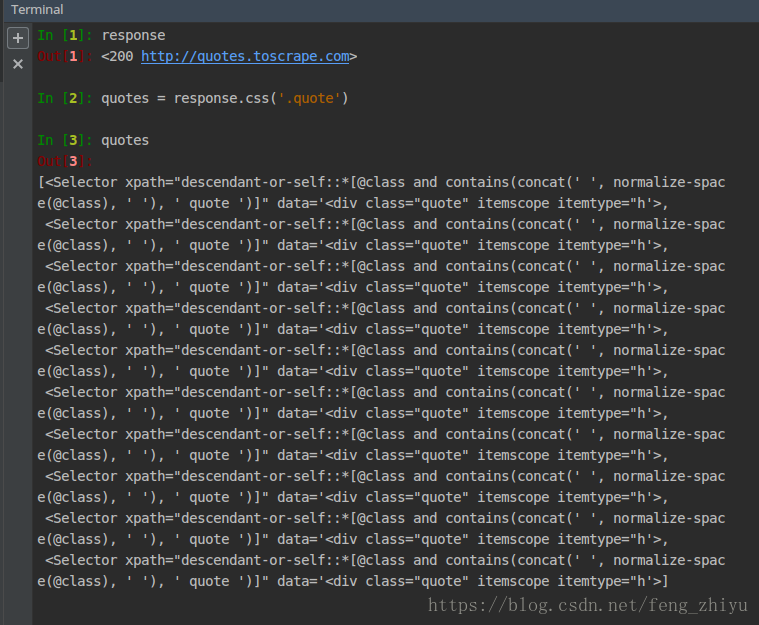
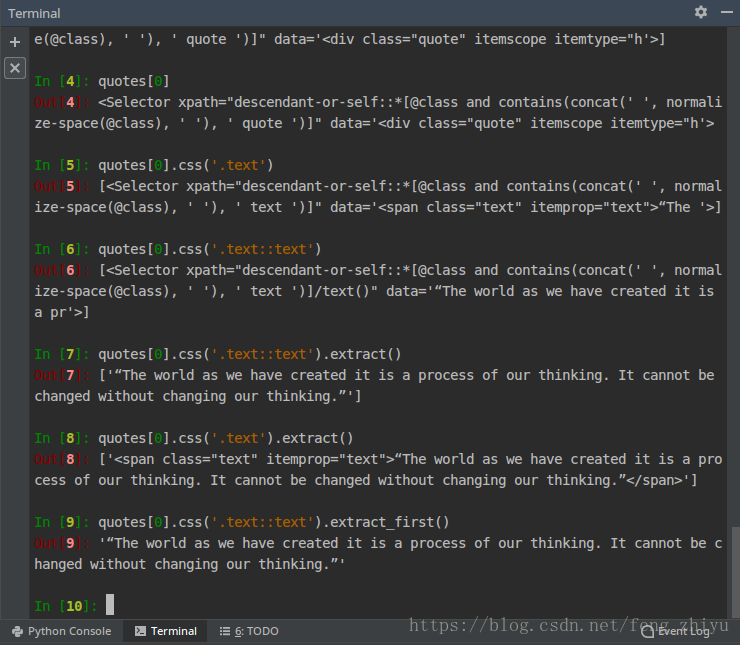
编写好代码后,再次运行。
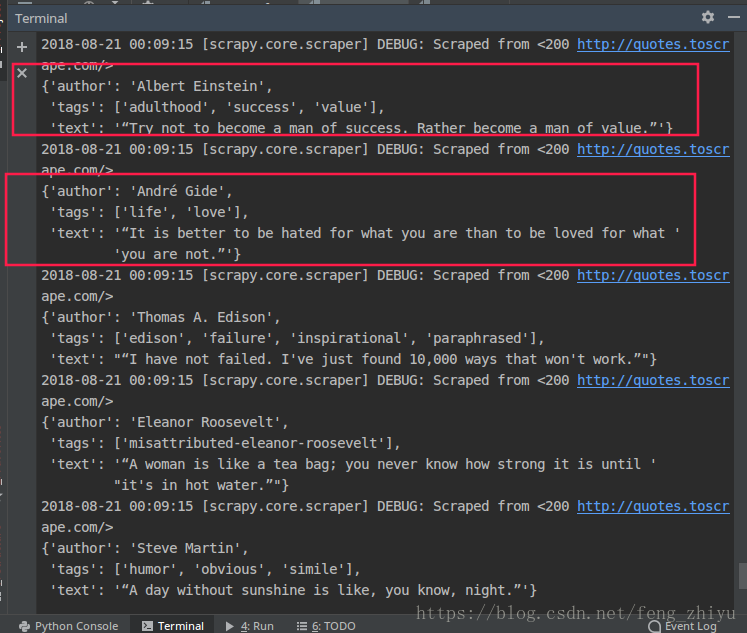
单页的名言信息爬取成功。
scrapy crawl quotes -o quotes.json执行此命令抓取并保存为json文件
scrapy crawl quotes -o quotes.jl 保存为.jl文件
scrapy crawl quotes -o quotes.csv
scrapy crawl quotes -o quotes.xml
scrapy crawl quotes -o quotes.marshal
源码放在github了。

















 64万+
64万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









