







 本文介绍如何使用Python和scikit-learn解决多类文本分类问题,以金融消费者投诉数据为例,通过数据探索、文本表示、特征工程和多种机器学习模型的比较,最终选用线性支持向量机作为最佳模型,平均准确率约82%。
本文介绍如何使用Python和scikit-learn解决多类文本分类问题,以金融消费者投诉数据为例,通过数据探索、文本表示、特征工程和多种机器学习模型的比较,最终选用线性支持向量机作为最佳模型,平均准确率约82%。
来源 | TowardsDataScience
译者 | Revolver
在我们的商业世界中,存在着许多需要对文本进行分类的情况。例如,新闻报道通常按主题进行组织; 内容或产品通常需要按类别打上标签; 根据用户在线上谈论产品或品牌时的文字内容将用户分到不同的群组......
但是,互联网上的绝大多数文本分类文章和教程都是二文本分类,如垃圾邮件过滤(垃圾邮件与正常邮件),情感分析(正面与负面)。在大多数情况下,我们的现实世界问题要复杂得多。因此,这就是我们今天要做的事情:将消费者在金融方面的投诉分为12个事先定义好的类别。数据可以从data.gov
(https://catalog.data.gov/dataset/consumer-complaint-database)下载。
我们使用Python和Jupyter Notebook来开发我们的系统,并用到了Scikit-Learn中的机器学习组件。如果您想看到在PySpark
(https://medium.com/@actsusanli/multi-class-text-classification-with-pyspark-7d78d022ed35)上的实现,请阅读下一篇文章。
一、问题描述
我们的问题是是文本分类的有监督问题,我们的目标是调查哪种监督机器学习方法最适合解决它。
如果来了一条新的投诉,我们希望将其分配到12个类别中的一个。分类器假设每条新投诉都分配给一个且仅一个类别。这是文本多分类问题。是不是很迫不及待想看到我们可以做到什么程度呢!
二、数据探索
在深入研究机器学习模型之前,我们首先应该观察一下部分数据,看看每个类别下的投诉都是什么样儿?
import pandas as pd
df = pd.read_csv('Consumer_Complaints.csv')
df.head()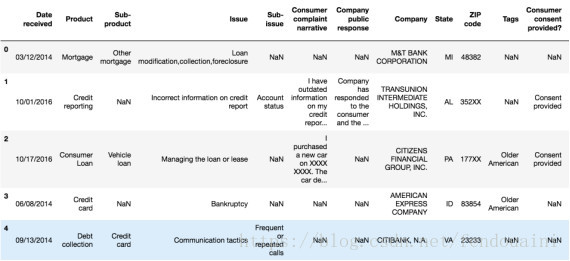
对于这个项目,我们其实只需要关注两列数据 - “Product”和“ Consumer complaint narrative ”(消费者投诉叙述)。
输入:Consumer_complaint_narrative
示例:“ I have outdated information on my credit report that I have previously disputed that has yet to be removed this information is more then seven years old and does not meet credit reporting requirements”
(“我的信用报告中存在过时信息,我之前已经提到过但还是没被删除, 此信息存在达七年之久,这并不符合信用报告要求”)
输出:Product
示例:Credit reporting (信用报告)
我们将移除“Consumer_complaint_narrative”这列中含缺失值的记录,并添加一列将Product编码为整数的列,因为分类标签通常更适合用整数表示而非字符串。
我们还创建了几个字典对象保存类标签和Product的映射关系,供将来使用。
清洗完毕后,以下是我们将要处理的前五行数据:
from io import StringIO
col = ['Product', 'Consumer complaint narrative']
df = df[col]
df = df[pd.notnull(df['Consumer complaint narrative'])]
df.columns = ['Product', 'Consumer_complaint_narrative']
df['category_id'] = df['Product'].factorize()[0]
category_id_df = df[['Product', 'category_id']].drop_duplicates().sort_values('category_id')
category_to_id = dict(category_id_df.values)
id_to_category = dict(category_id_df[['category_id', 'Product']].values)
df.head()
三、不平衡的类
我们发现每种产品收到的投诉记录的数量是不平衡的。消费者的投诉更倾向于Debt collection(债款收回),Credit reporting (信用报告),
Mortgage(抵押贷款。)
Import matplotlib.pyplot as plt
fig = plt.figure(figsize=(8,6))
df.groupby('Product').Consumer_complaint_narrative.count().plot.bar(ylim=0)
plt.show()
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1379
1379

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









