







 本文介绍了Spark Streaming的背景、运行原理及程序设计,阐述了其将流处理转化为微批处理的特点,实现了秒级延迟。讨论了如何从Twitter获取Hashtag并展示了NetworkWordCount实例。此外,还讲解了窗口操作、状态维护和自定义转换。最后,探讨了Spark Streaming与Kafka、Redis的集成在实时数据处理系统中的应用。
本文介绍了Spark Streaming的背景、运行原理及程序设计,阐述了其将流处理转化为微批处理的特点,实现了秒级延迟。讨论了如何从Twitter获取Hashtag并展示了NetworkWordCount实例。此外,还讲解了窗口操作、状态维护和自定义转换。最后,探讨了Spark Streaming与Kafka、Redis的集成在实时数据处理系统中的应用。
背景
很多重要的应用要处理大量在线流式数据,并返回近似实时的结果,比如社交网络趋势追踪,网站指标统计,广告系统。所以需要具备分布式流式处理框架的基本特征,包括良好的扩展性(百级别节点)和低延迟(秒级别)。
批处理
MapReduce和Spark Core都是批处理:需要收集数据,然后分批处理,这样一般会有一定的延时。
 流式处理
流式处理
数据收集后,直接处理。

流式计算框架
Spark Streaming 是微批(微小批处理)处理,可以达到秒级延时。
 Spark Streaming将Spark扩展为大规模流处理系统,可以扩展到100节点规模,达到秒级延迟,高效且具有良好的容错性,提供了类似批处理的API,可以很容易实现复杂算法。Spark Streaming可以和其他系统做很好的集成。
Spark Streaming将Spark扩展为大规模流处理系统,可以扩展到100节点规模,达到秒级延迟,高效且具有良好的容错性,提供了类似批处理的API,可以很容易实现复杂算法。Spark Streaming可以和其他系统做很好的集成。

Spark Streaming运行原理
Spark Streaming将流式计算转化为一批很小的、确定的批处理作业(micro-batch)。它以X秒为单位将数据流切分成离散的作业,将每批数据看做RDD,使用RDD操作符处理,最终结果以RDD为单位返回(写入HDFS或者其他系统)。Spark Streaming仍然是运行在Driver Executor的环境里。
 Hashtag是微博内容中的标签,可用于检索、建索引等,Twitter提供了流式获取Hashtag的API,Spark Streaming封装了Twitter的Hashtag API。
Hashtag是微博内容中的标签,可用于检索、建索引等,Twitter提供了流式获取Hashtag的API,Spark Streaming封装了Twitter的Hashtag API。
 从Twitter中获取Hashtag
从Twitter中获取Hashtag
输入Twitter的用户名和密码,就会实时的查看关注的大V发的微博,大V发的微博会像流一样实时的推送过来,流式数据切分成一个个的Batch,以秒为单位定义成DStream,相当于一个RDD流。
// 构造一个StreamingContext对象,并将每秒产生的数据作为一批处理
val ssc = new StreamingContext(sparkConf, Seconds(1))
// 通过StreamingContext 中的twitterStream接口,创建DStream,DStream是一块代表流式数据的RDD序列
val tweets = ssc.twitterStream()

// Transformation: 从一个Dstream得到另一个Dstream
val hashTags = tweets.flatMap (status => getTags(status))

// Output Operation: 将数据写入外部存储设备
hashTags.saveAsHadoopFiles("hdfs://...")
 Spark Stream:
Spark Stream:
DStream->Transformation->DStream
Spark SQL:
Dataframe/Dataset ->Transformation->Dataframe/Dataset
Spark:
RDD->Transformation->RDD
Spark Stream类似一个服务,永远不会运行结束,它跟着数据的流入运算,会产生很多小文件。如果没有数据流入就一直监听,看是否有新的数据进来。批处理会结束,它扫描完数据源后就开始运算,再写入数据源目录的数据文件不会被包含进来。
Spark Streaming程序设计
实例:NetworkWordCount
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext}
val sparkConf = new SparkConf().setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(1))
val lines = ssc.socketTextStream(”localhost”, 9999, StorageLevel.MEMORY_AND_DISK_SER)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _) wordCounts.print()
ssc.start() ssc.awaitTermination()
- 输入流:
主要的作用是从数据源生成初始的RDD,数据源可以是文件、队列和Kafka,大多都使用Kafka,不同的实现产生不同的RDD:
– Non-Receiver
• DirectKafkaInputDStream
• FileInputDStream
• QueueInputDStream
– Receiver Based
• 从不同的数据源接收数据,并生成统一的BlockRDD[T]
| Type | Operators | InputDStream | generateRDD |
| Non-Receiver InputDStream | queueStream | QueueInputDStream | RDD(provided by user)/UnionRDD |
| fileStream, textFileStream binaryRecordsStream | FileInputDStream | NewHadoopRDD/Uni onRDD | |
| KafkaUtils. createDirectStream | DirectKafkaInputDStream | KafkaRDD | |
| Receiver- Based InputDStream | actorStream, receiverStream | PluggableInputDStream | BlockRDD |
| socketTextStream | SocketInputDStream | BlockRDD | |
| rawSocketStream | RawInputDStream | BlockRDD | |
| FlumeUtils.createStream | FlumeInputDStream | BlockRDD | |
| TwitterUtils.createStream | TwitterInputDStream | BlockRDD | |
| KafkaUtils.createStream | KafkaInputDStream | BlockRDD | |
Createstream可以从Kafka的Topic里直接消费数据
textFileStream
将HDFS的目录作为流式数据源,每隔固定周期扫描该目录,将新出现的文件当做本次Batch需要处理的数据,输出是一个文本流,流中每一条记录代表了原始文件中的一个文本行。新文件最好通过Move的方式移动到目录中,检查新文件,不检测文件的变化,主要应用在日志处理。
- 流式转换
• 类RDD转换
– map, flatMap, filter, reduce
– groupByKey, reduceByKey, sortByKey, join, etc
– count
• Streaming独有转换
– window
– mapWithState
– transform
| Operators | Dstream | Output | Description |
|---|---|---|---|
| map | MappedDStream | MapPartitions RDD | Return a new DStream by passing each element of the source DStream through a function func |
| mapPartitions | MapPartitioned DStream | MapPartitions RDD | |
| flatMap | FlatMapped DStream | MapPartitions RDD | |
| filter | FilteredDStream | MapPartitions RDD | |
| union | UnionDStream | UnionRDD | Return a new DStream that contains the union of the elements in the source DStream and otherDStream |
| *ByKey,count, reduce | ShuffledDStream | ShuffledRDD | When called on a DStream of (K, V) pairs, return a new DStream of (K, V) pairs where the values for each key are aggregated using the given reduce function. |
| join, cogroup, repartition, transform, transformWith | Transformed DStream | RDD | Return a new DStream by applying a RDD-to-RDD function to every RDD of the source DStream. This can be used to do arbitrary RDD operations on the DStream. |
| mapWithState | MapWithState DStream | MapPartitions RDD* | Return a new “state” DStream where the state for each key is updated by applying the given function on the previous state of the key and the new values for the key |
| window, *ByWindow | Windowed DStream | UnionRDD | Return a new DStream which is computed based on windowed batches of the source DStream |
window
Windows:比如把一秒一秒的聚集成一分钟的窗口。
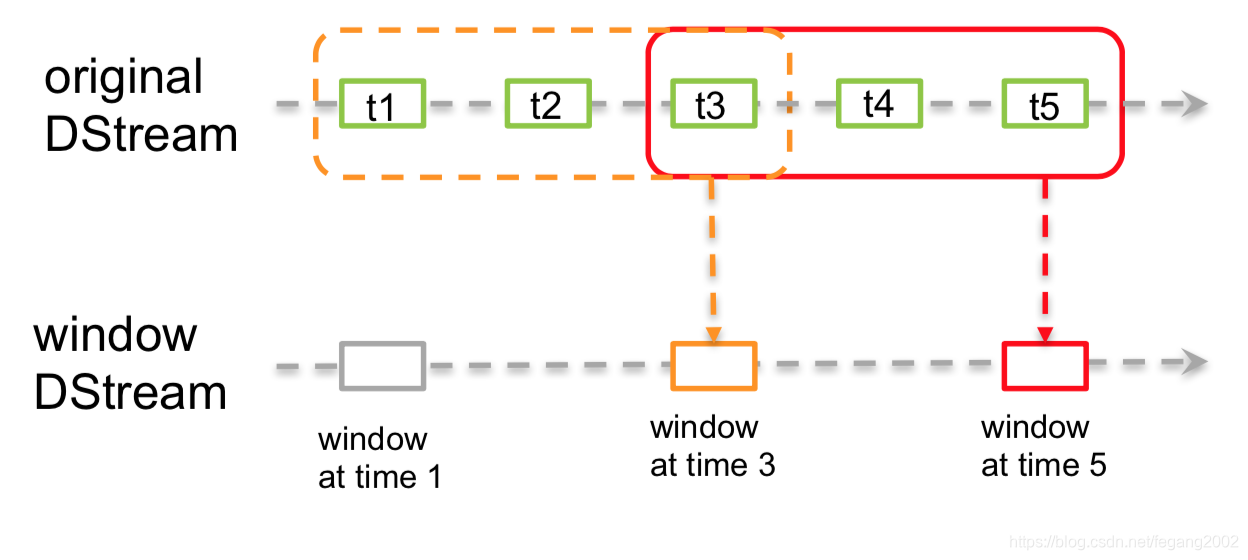
val windowDStream = originDStream.window(Seconds(3), Seconds(2))
这个例子里的窗口持续时间为3秒,间隔2秒。
可以基于窗口做归约:
• window
• countByWindow
• reduceByWindow
• reduceByKeyandWindow
• countByValueAndWindow
val tweets = ssc.twitterStream()
val hashTags = tweets.flatMap (status => getTags(status))
val tagCounts = hashTags.window(Seconds(10), Seconds(5)).countByValue()
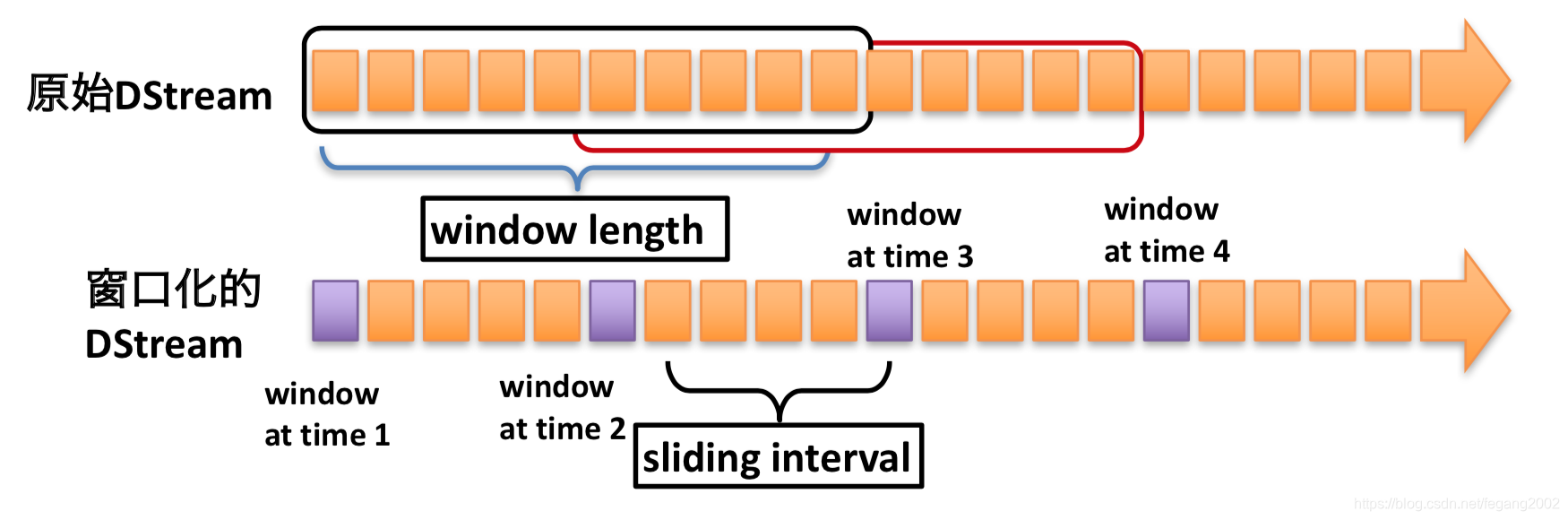 Dsream就是一个个的RDD组成,这里设置每个窗口是10秒,窗口之间间隔5秒。
Dsream就是一个个的RDD组成,这里设置每个窗口是10秒,窗口之间间隔5秒。
mapWithState
由Spark Streaming自己维护历史状态信息,而不是借助外部存储系统,比如redis 。Session是一个用户有效的活动区间,Spark利用各个Executore来存储状态信息,这个可以通过mapWithState实现。
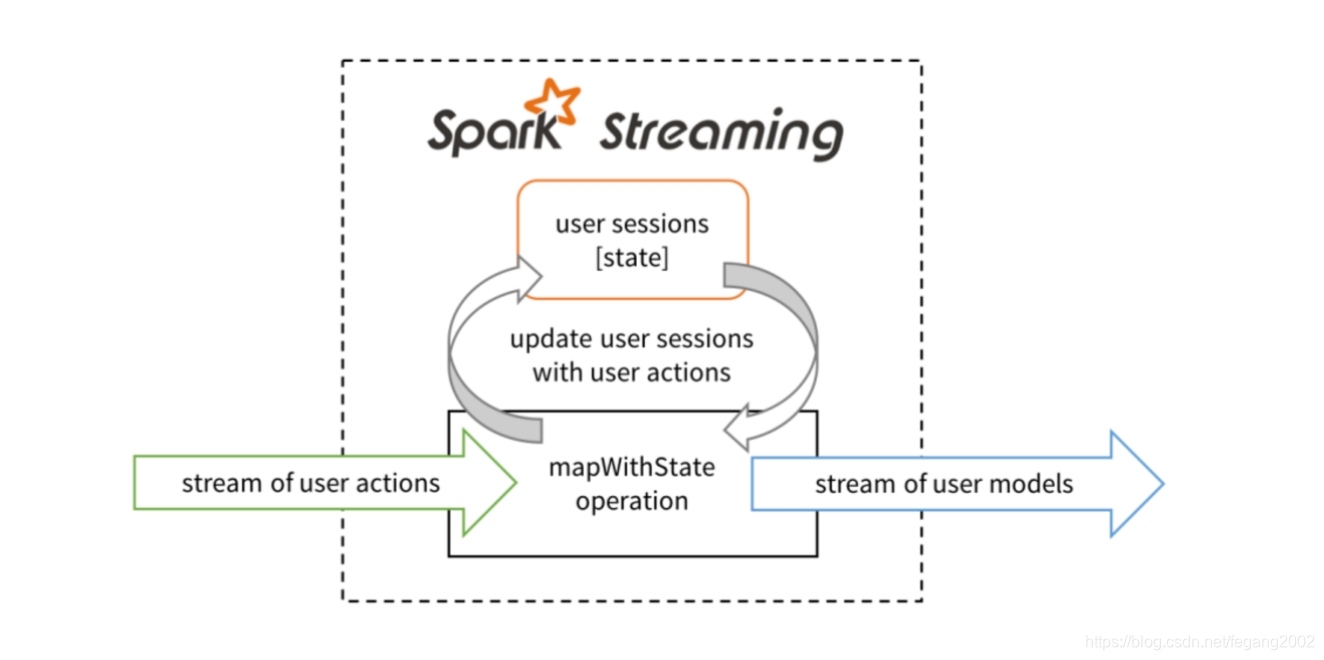
tweets.mapWithStates(tweet => updateMood(tweet))
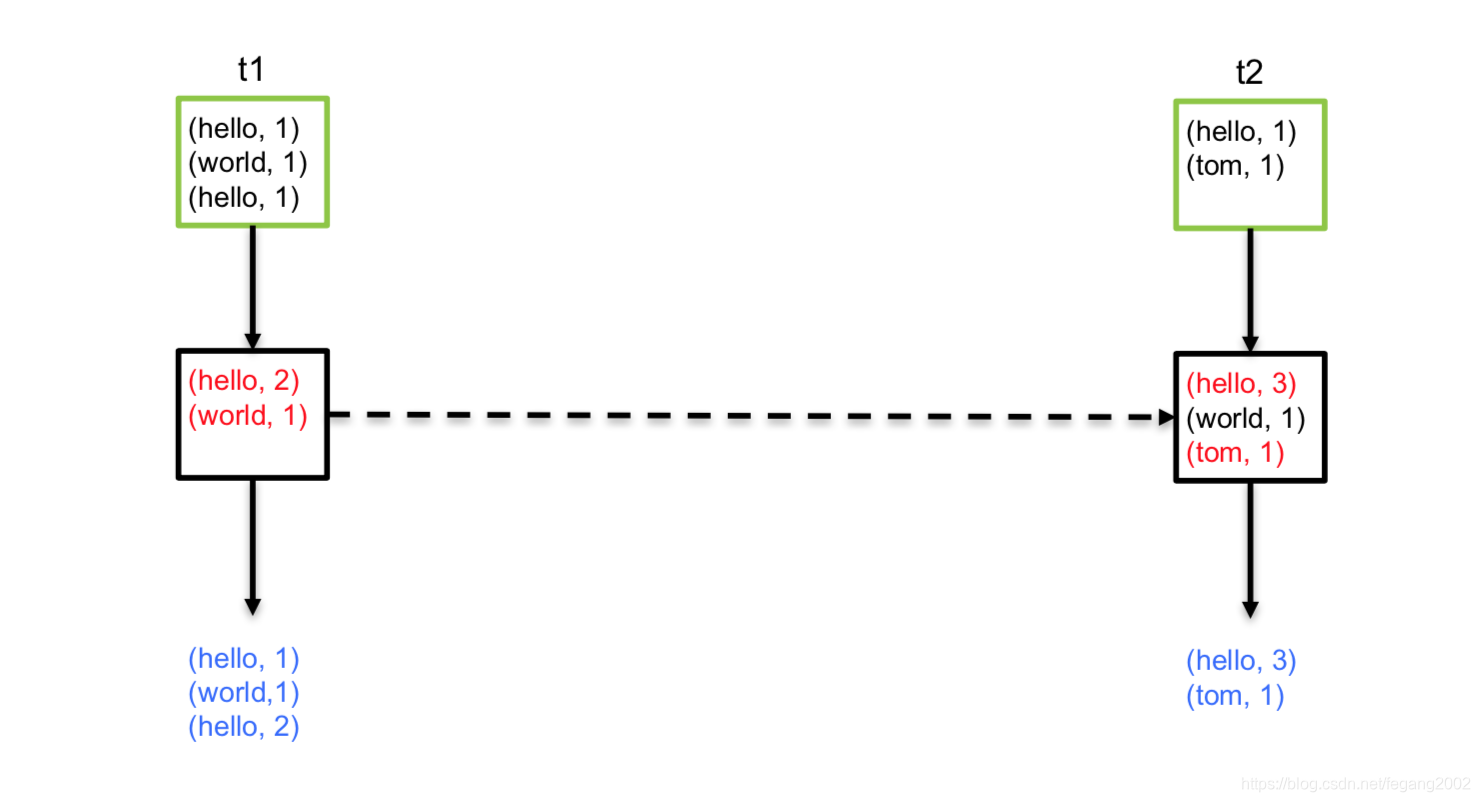
val wordDstream = words.map(x => (x, 1))
// word是Input Key; one是Input Value; state是History State
val mappingFunc = (word: String, one: Option[Int], state: State[Int]) => {
val sum = one.getOrElse(0) + state.getOption.getOrElse(0)
val output = (word, sum)
// State Update
state.update(sum)
// Output
output
}
val stateDstream = wordDstream.mapWithState(StateSpec.function(mappingFunc)) stateDStream.print()
如果KEY一段时间没有更新,会从内存移掉
 Transform
Transform
• 将DStream的每个RDD转变为另外一个RDD
– transformFunc: RDD[T] => RDD[U]
• 定制化计算
• 应用场景:
– 实现其他的算子,例如repartition,join
– 实现DStream和外部数据交互, 例如和外部数据 join
- 输出流
• 将处理过的数据输出到外部系统
• 内置输出
– print
– saveAsTextFiles/saveAsObjectFiles/saveAsHadoop Files
• 自定义输出
– foreachRDD
| Operators | DStream | Output | Description |
|---|---|---|---|
| ForEachDStream | Job | Prints the first ten elements of every batch of data in a DStream on the driver node | |
| saveAsTextFiles | ForEachDStre am | ForEachDStre am | Save this DStream‘s contents as text files, The file name at each batch interval is generated based on prefix and suffix: “prefix- TIME_IN_MS[.suffix]”. |
| saveAsObjectFiles | ForEachDStre am | Job | Save this DStream’s contents as SequenceFiles of serialized Java objects |
| saveAsHadoopFiles | ForEachDStre am | Job | Save this DStream’s contents as Hadoop files |
| foreachRDD | ForEachDStre am | Job | The most generic output operator that applies a function, func, to each RDD generated from the stream. This function should push the data in each RDD to an external system, such as saving the RDD to files, or writing it over the network to a database. Note that the function func is executed in the driver process running the streaming application, and will usually have RDD actions in it that will force the computation of the streaming RDDs. |
foreachRDD
• 输出参数:foreachFunc: RDD[T] => Unit
• 每个Batch间隔都执行一次该函数
• 函数中可以执行各种操作
• 应用场景:
– 实现其他算子,如print
– 更新外部存储如redis, hbase等
– 更新内部缓存
Spark程序:使用RDD分析Twitter日志
val tweets = sc.hadoopFile("hdfs://...")
val hashTags = tweets.flatMap (status => getTags(status))
hashTags.saveAsHadoopFile("hdfs://...")
Spark Streaming程序:使用DStream分析Twitter数据流
val tweets = ssc.twitterStream()
val hashTags = tweets.flatMap (status => getTags(status))
hashTags.saveAsHadoopFiles("hdfs://...")
Spark—全能型处理系统
批处理:Spark Core
交互式计算:Spark SQL
流式计算:Spark Streaming
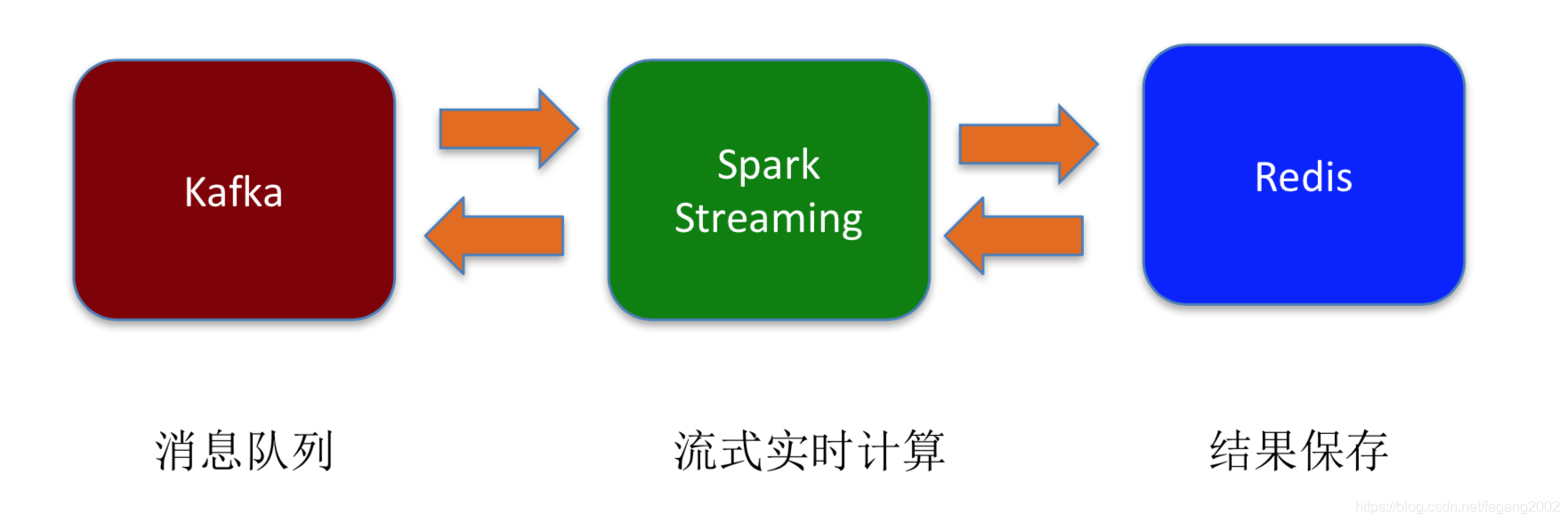
Spark Streaming + Kafka + Redis
常见的流式数据处理系统架构
数据先放到消息队列(具有缓存功能),然后给流式计算引擎,最后保存到MySQL或是Redis,也可以从MySQL和HBase中读数据,然后再写回到MySQL和HBase中。Spark Streaming是Kafka的Consumer。
 Spark Streaming提供了两种访问Kafka的API:
Spark Streaming提供了两种访问Kafka的API:
- Receiver-based Approach:
最原始的API,启动若干特殊的 Task(Receiver),从Kafka上拉取数据,保存成RDD供处理; - Direct Approach
新API,无需启动Receiver,每一轮Spark Job直接从Kafka上读取数据。
import org.apache.spark.streaming.kafka._
val directKafkaStream = KafkaUtils.createDirectStream[
[key class], [value class], [key decoder class], [value decoder class] ]( streamingContext, [map of Kafka parameters], [set of topics to consume])
directKafkaStream
.repartition(M)
.map { ....}
.foreachRDD {...}
用户手机App行为分析系统
- 处理流程:
1)手机客户端会收集用户的行为事件(我们以点击事件为 例),将数据发送到Kafka消息队列;
2)后端的基于Spark Streaming的实时分析程序会从Kafka消费 数据,将数据读出来并进行实时分析;
3)经过Spark Streaming实时计算程序分析,将结果写入Redis,可以实时获取用户的行为数据,并可以导出进行离线综合统计分析。
- 实现方案
写了一个Kafka Producer模拟程序,用来模拟向Kafka实时写入用户行为的事件数据,数据是JSON格式,示例如下:
{“uid”:“068b746ed4620d25e26055a9f804385f”,“event_time”:“1430204612405”,“os _type”:“Android”,“click_count”:6}
一个事件包含4个字段:
1)uid:用户编号
2)event_time:事件发生时间戳
3)os_type:手机App操作系统类型
4)click_count:点击次数 - 代码实现
val producer = new Producer[String, String](kafkaConfig)
while(true) {
// prepare event data
val event = new JSONObject()
event.put("uid", getUserID)
event.put("event_time", System.currentTimeMillis.toString)
event.put("os_type", "Android")
event.put("click_count", click)
// produce event message
producer.send(new KeyedMessage[String, String](topic, event.toString))
println("Message sent: " + event)
Thread.sleep(200)
}
val kafkaStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics)
val events = kafkaStream.flatMap(line => {
val data = JSON.parseObject(line._2)
Some(data)
})
// Compute user click times
val userClicks = events.map(x => (x.getString("uid"), x.getLong("click_count"))).reduceByKey(_ + _)
userClicks.foreachRDD(rdd => {
rdd.foreachPartition(partitionOfRecords => {partitionOfRecords.foreach(
pair => {
val uid = pair._1
val clickCount = pair._2
val jedis = RedisClient.pool.getResource
jedis.hincrBy(clickHashKey, uid, clickCount)
RedisClient.pool.returnResource(jedis)
})
})
})

















 2283
2283

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









