



目录
在众多聚类算法中,DBSCAN 聚类以其独特的特性占据着重要地位。它最为突出的特点是基于密度进行聚类,这使得它能够摆脱传统聚类算法对簇形状的限制,精准识别出任意形状的簇,无论是常见的圆形簇,还是不规则的条形、环形簇等,都能较好地进行划分,在数据挖掘等领域有着广泛的应用。
一、模型原理
DBSCAN(Density - Based Spatial Clustering of Applications with Noise)聚类算法的核心原理围绕 “密度” 展开,主要涉及以下关键概念和步骤:
核心对象:在设定的半径 ε 范围内,若某个数据点包含的其他数据点数量不少于最小样本数 MinPts,则该数据点被称为核心对象。
直接密度可达:若数据点 p 是核心对象,且数据点 q 在 p 的 ε 邻域内,那么称 q 从 p 直接密度可达。
密度可达:若存在一个数据点序列 p₁,p₂,…,pₙ,其中 p₁=p,pₙ=q,且对于每个 i(1≤i <n),pᵢ₊₁从 pᵢ直接密度可达,则称 q 从 p 密度可达。
密度相连:若存在一个数据点 o,使得数据点 p 和 q 都从 o 密度可达,则称 p 和 q 密度相连。
聚类过程:首先从数据集中随机选取一个未被标记的点,若该点是核心对象,就以它为起点,将所有从它密度可达的点构成一个簇;若该点不是核心对象,就将其标记为噪声点。重复此过程,直到所有数据点都被标记(要么属于某个簇,要么是噪声点)。

二、模型代码
以下是使用 Python 的 scikit - learn 库实现 DBSCAN 聚类的代码示例。为让数据更逼真,增大了噪声参数。
# 导入必要的库
import numpy as np
from sklearn.cluster import DBSCAN
from sklearn.datasets import make_moons
import matplotlib.pyplot as plt
#设置中文字体
plt.rcParams['font.sans-serif']=['SimHei']
# 生成测试数据(调整noise参数至0.12,更贴近实际场景中带自然噪声的数据分布)
X, y_true = make_moons(n_samples=300, noise=0.12, random_state=42)
# 构建DBSCAN模型并进行训练
# eps为半径参数,min_samples为最小样本数参数
dbscan = DBSCAN(eps=0.3, min_samples=5)
y_pred = dbscan.fit_predict(X)
# 输出聚类结果
print("聚类标签(-1表示噪声点):", y_pred)
# 绘制聚类结果图
plt.figure(figsize=(8, 6))
# 统一用不同颜色区分簇,噪声点随所属密度区域颜色呈现
plt.scatter(X[:, 0], X[:, 1], c=y_pred, cmap='viridis', s=50, label='聚类点')
plt.title('DBSCAN聚类结果可视化')
plt.xlabel('特征1')
plt.ylabel('特征2')
plt.legend()
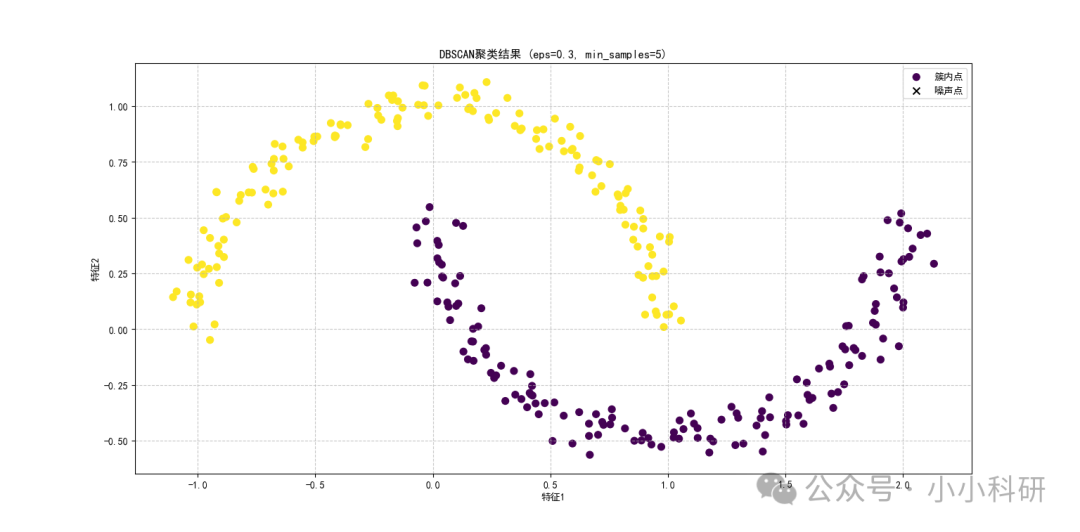
plt.show()三、可视化图表
如下图,不同颜色代表不同簇,可以看到,数据噪声接近真实场景时,DBSCAN 依然能准确将月牙形数据划分为两个簇。
这充分体现其基于密度聚类的优势。模型能精准识别出任意形状的簇,无论是常见的圆形簇,还是不规则的条形、环形簇。
关注【小小科研】公众号,了解更多模型哦,感谢支持!


















 2169
2169

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











