






 文章提出了去混杂训练方法来解决显著性检测中的对比度分布和空间分布偏差问题。通过图像级加权策略以及对深度学习模型的改进,提高了显著性预测的准确性,减少了模型对图像中心区域的过度关注。实验表明,这种方法在无监督设置下也能获得与监督和半监督训练相媲美的结果。
文章提出了去混杂训练方法来解决显著性检测中的对比度分布和空间分布偏差问题。通过图像级加权策略以及对深度学习模型的改进,提高了显著性预测的准确性,减少了模型对图像中心区域的过度关注。实验表明,这种方法在无监督设置下也能获得与监督和半监督训练相媲美的结果。
背景知识
显著性检测
简单就是使用图像处理技术和计算机视觉算法来定位图片中最“显著”的区域。显著区域就是指图片中引人注目的区域或比较重要的区域,例如人眼在观看一幅图片时会首先关注的区域。
chatGPT4的回答
计算机视觉中的显著性检测(Visual Salience Detection)是一种技术,用于识别和突显图像或视频中最显著、最引人注意的区域。这些显著区域通常是由于其与周围环境在颜色、亮度、纹理、运动等方面的显著差异而引起的。显著性检测在许多计算机视觉应用中发挥着重要作用,如物体检测、目标跟踪、图像分割、图像检索、注意力建模等。
显著性检测的方法可以大致分为以下几类:
-
基于对比度的方法:这类方法利用目标与其周围环境的对比度来衡量显著性。通过计算图像中每个像素与其他像素之间的颜色、亮度或纹理差异,可以生成显著性图。典型的方法包括颜色对比度、局部二值模式等。
-
基于图模型的方法:这类方法将图像分割成若干个区域或超像素,并将它们表示为图中的节点。通过计算节点之间的相似性或连接权重,可以构建一个图模型。然后,应用图论中的算法(如最大流、最小割、PageRank等)来检测显著性区域。
-
基于频域的方法:这类方法利用图像的频率特性来检测显著性区域。例如,通过对图像进行傅里叶变换或小波变换,可以找到在频域上表现出显著性的部分。
-
基于生物学的方法:这类方法试图模仿人类或其他生物视觉系统的原理来检测显著性。典型的方法包括Itti等人提出的显著性模型,该模型通过计算图像中的颜色、亮度和方向特征来生成显著性图。
- 基于深度学习的方法:这类方法利用深度神经网络(如卷积神经网络、递归神经网络等)对图像进行显著性检测。这些方法通常需要大量带有显著性标注的图像数据进行训练,以便网络学习显著性特征。
以上仅为显著性检测方法的简要概述,实际上还存在许多其他方法和技术。显著性检测是一个不断发展的研究领域,研究人员正努力开发更有效、更快速、更鲁棒的算法来应对各种应用场景。
存在的问题
- 视觉对比度信息是视觉显著性的最重要因素,但不能保证其在数据集中的分布是均匀的,这会误导经过训练的模型对数据丰富的视觉对比度集群做出偏向的预测。
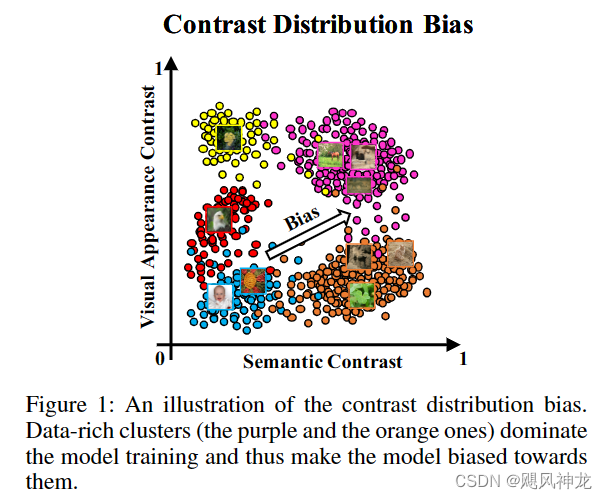
-
来自视觉对比度信息分布和显著物体空间分布的偏差会误导模型训练,转而将图像平面的中心区域预测为显著区域。
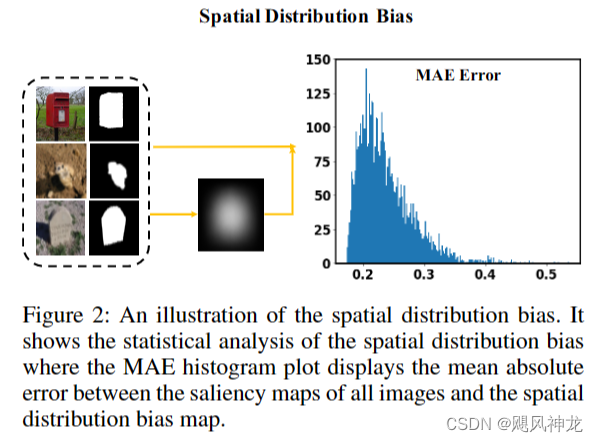
本文核心思路
- 提出了一种去混杂训练方法来消除对比度分布偏差引起的混杂效应,使视觉对比度对最终的显着性预测有公平的贡献。
- 引入了一种图像级加权策略,可以对每个图像的重要性进行软加权,以最小化 空间分布偏差的误导影响。
具体方法
BaseLine
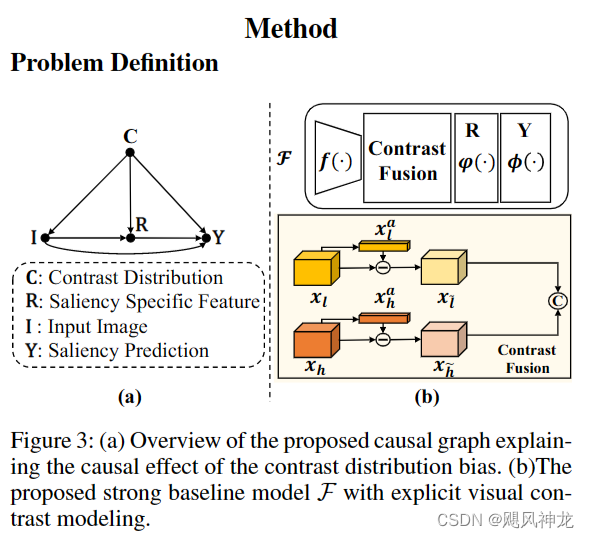
其中 F 为一个深度学习模型,需要进行训练,文中采用的是讲DSR、MC 和 RBD的结果作为伪标签开始训练。
并且在训练的过程中使用CRF进行更新迭精细化标签,使得伪标签噪声能够减少,在后续迭代过程进一步优化模型, 其中l为第t个epoch的标签:
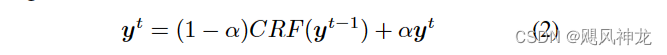

Loss函数分为三块,
1 . F-measure 来评测显著性区域预测的准确性,但为了增加F-measure 对噪声的鲁棒性,便让β^2取为0.3:
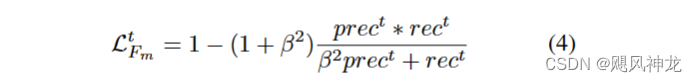
2. 交并比(IOU):
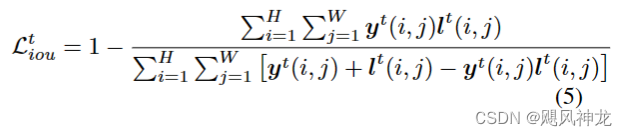
3. 边缘损失:

最终,loss为:
![]()
解决对比度分布偏差
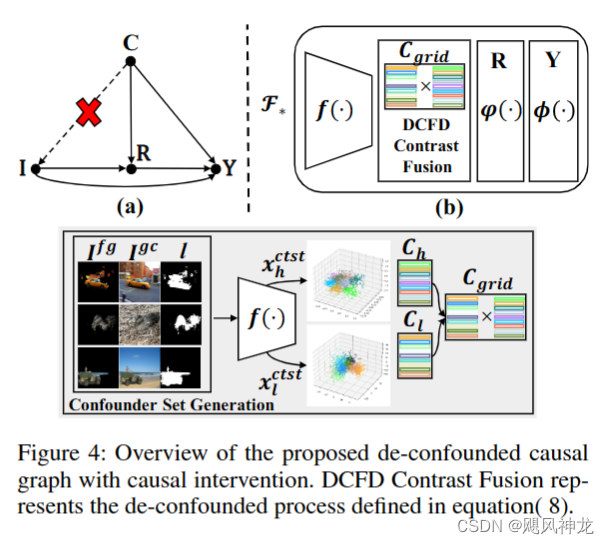
因果链分析:
- C->I:对比度分布影响着图像的内容
- C->Y:对比度分布影响着靠传统方法生成的伪标签
- I->R->Y:图像内容影响了通过模型后的显著性特征,也影响了最终的预测
- C->R->Y:由于在2中影响了伪标签,因此也影响了分类层,也影响了最终的预测
- I->Y:图像直接影响最终的结果,这个是我们最终想要的因果关系
讨论了混杂的概念,混杂因素是输入图像及其相应显著性预测的常见原因。在这种情况下,混杂因素是对比度分布 (C)。富含数据的视觉对比度聚类的积极影响遵循从输入图像(I)到显著性特异表现(R)的因果关系,然后是显著性预测(Y),这有助于学习对比度感知的判别性USOD模型。但是,这些集群的负面影响迫使输入图像中一些非显著的背景像素在预测中突出,遵循后门因果关系(I ← C → R → Y 和 I ← C → Y)。
改进方案
切断 C→I 将 P(Y| I) 改为 P(Y|do(I)) = ΣP(Y|I,R,c)P(c), 这个过程叫做后门调整。
简而言之就是将C通过k-means++与PCA等聚类算法根据其对比度信息将其拆为几个部分。

解决空间分布偏差
产生原因:
1.大部分显著性目标都出现在画面的中央
2.传统显著性目标检测的使用了中心先验的方法来生成伪标签,再训练模型也会加剧空间偏差
改进方案:提出了一种图像级加权策略
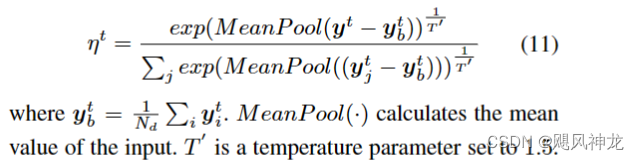
作者指出,放大 T‘ 会导致所有图像权重的平均值更高。图像加权策略与焦点损失的不同之处在于,焦点损失可以平衡每个训练样本的置信度,而所提出的方法则根据每个样本相对于空间分布偏差图的分布来平衡样本。作者明确缓解了训练中空间分布偏差的影响。
最终loss变为:
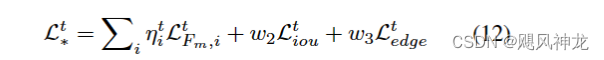
实验结果
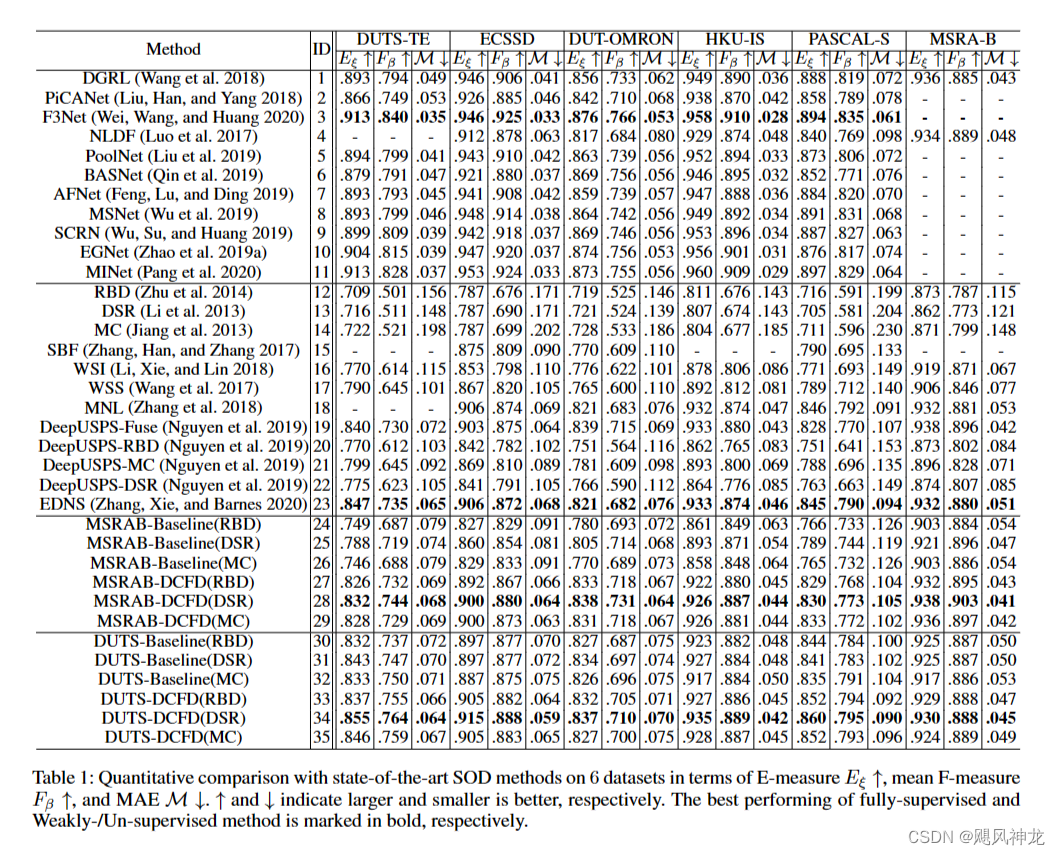
使用无监督的方法在一个测试集上训练,在其他几个测试集上去测试也能有较好的指标且堪比监督训练和半监督训练。
总结
本文主要针对显著性检测中的对比度分布偏差和空间分布偏差两种偏差,提出了一种去混淆训练方法来消除由对比分布偏差引起的混杂效应,以便视觉对比公平地贡献最终的显著性预测,并引入了图像级加权策略柔和地权衡每个图像的重要性,以最大程度地减少空间分布偏差的误导性影响。

















 1344
1344

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









