




 本文介绍了使用PySpark进行数据处理的几个实用技巧,包括求某列的最小最大值、普通pandas转换为pyspark DataFrame、处理VectorAssembler后的特征格式以及填充缺失值的方法。对于处理大规模数据集的开发者来说,这些技巧能够提升数据处理效率。
本文介绍了使用PySpark进行数据处理的几个实用技巧,包括求某列的最小最大值、普通pandas转换为pyspark DataFrame、处理VectorAssembler后的特征格式以及填充缺失值的方法。对于处理大规模数据集的开发者来说,这些技巧能够提升数据处理效率。
1. 求某一列的最小最大值
data.agg(F.min("dt"), F.max("dt")).show()
或者用data.describe(['dt']).show()
2. 普通pandas转成pyspark的pandas
spark_train = spark.createDataFrame(X_train)
3. VectorAssembler之后的features的格式
是struct<type:tinyint,size:int,indices:array<int>,values:array<double>>
很多时候不能直接操作,例如求和或者保存csv,此时需要进行转化,
如下可以转成一个vector用于求和。
首先将features转为一个string:f2。
然后对f2进行split,得到f3。再对f3求和,得到f4。
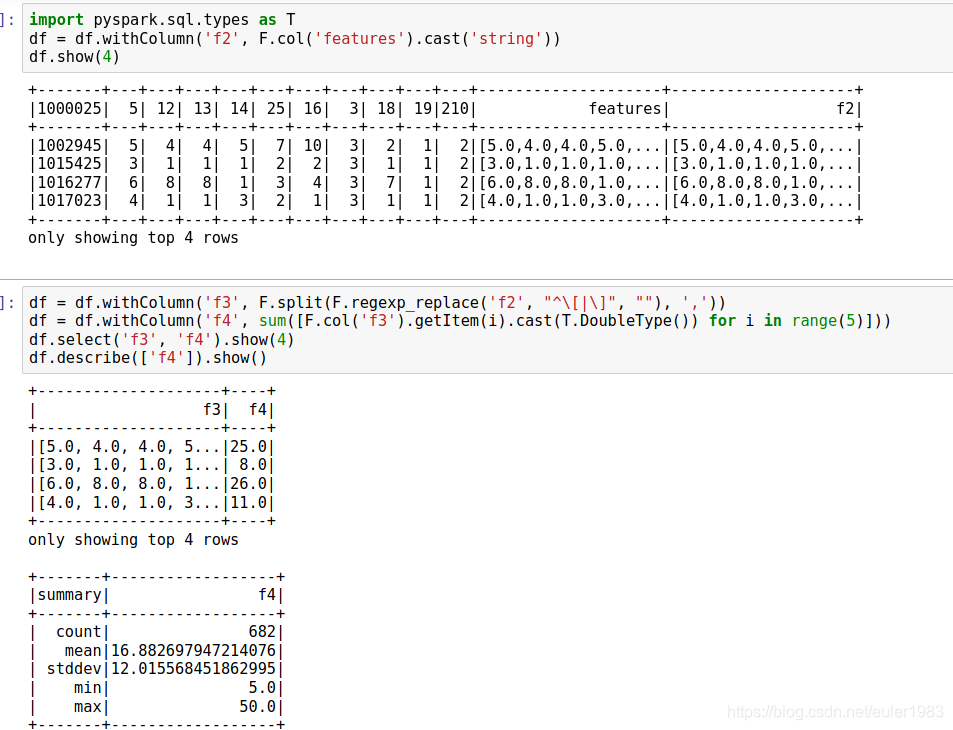
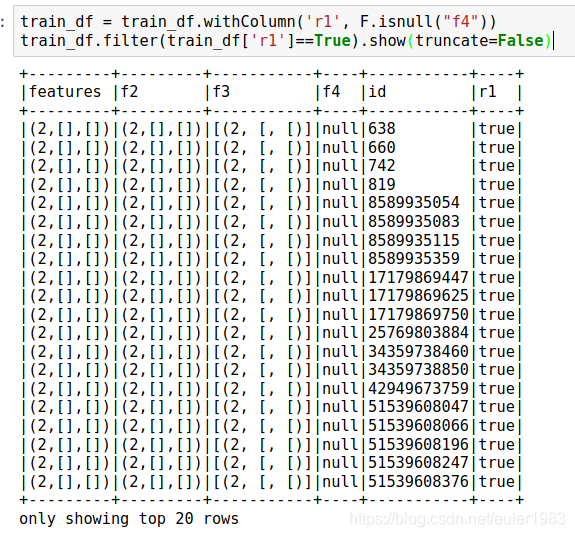
4. pyspark程序上来要填充缺失值。
今天用pyspark的iforest程序,fit的时候出错。排查了一下午,终于发现问题是由于里边有空值。
利用上面的求和,可以发现有大量的空值。

















 2612
2612

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









