




目录
数据检索(我们省略了重排序步骤,感兴趣的小伙伴可以自行了解以下 rerank 模型)
概述
传统商品检索需要依赖人工解析和构建商品的描述字段,将商品信息存入 ElasticSearch 或数据库,然后通过分词查询结合多重条件(类别或其他属性)检索到匹配的商品。
但是在传统检索中,因为分词本身的特点,经常会遇到误匹配的问题,例如:我们检索 "苹果耳机"的时候,往往会出现苹果和耳机的相关商品,导致客户体验效果不佳。
为了让检索更人性化,我们可以借助 RAG 技术,在传统分词搜索的基础上融入向量检索的能力,从而获得更贴近人类需求的检索效果。
名词解释
在开始之前,我们先把本文中需要用到的一些技术/接口/产品的专有名词做个说明,方便大家更好地理解文档:
-
RAG: 检索增强生成(Retrieval-augmented Generation),简称 RAG
-
ES: Elasticsearch 是一个开源的分布式搜索和分析引擎,常用于实时搜索、日志分析、数据可视化等应用
-
BES:百度 Elasticsearch(BES)是百度托管的 Elasticsearch 服务,完全兼容开源 Elasticsearch 的功能
-
Embedding:向量是一种数学技术,用于将对象或概念映射到高维空间,通过向量表示捕捉语义关系和数据结构
-
Prompt:用户或程序向模型提供的输入文本或指令,以引导模型生成特定类型或内容的响应
-
ERINIE 4.0:百度自行研发的文心产业级知识增强大语言模型 4.0 版本
思路分析
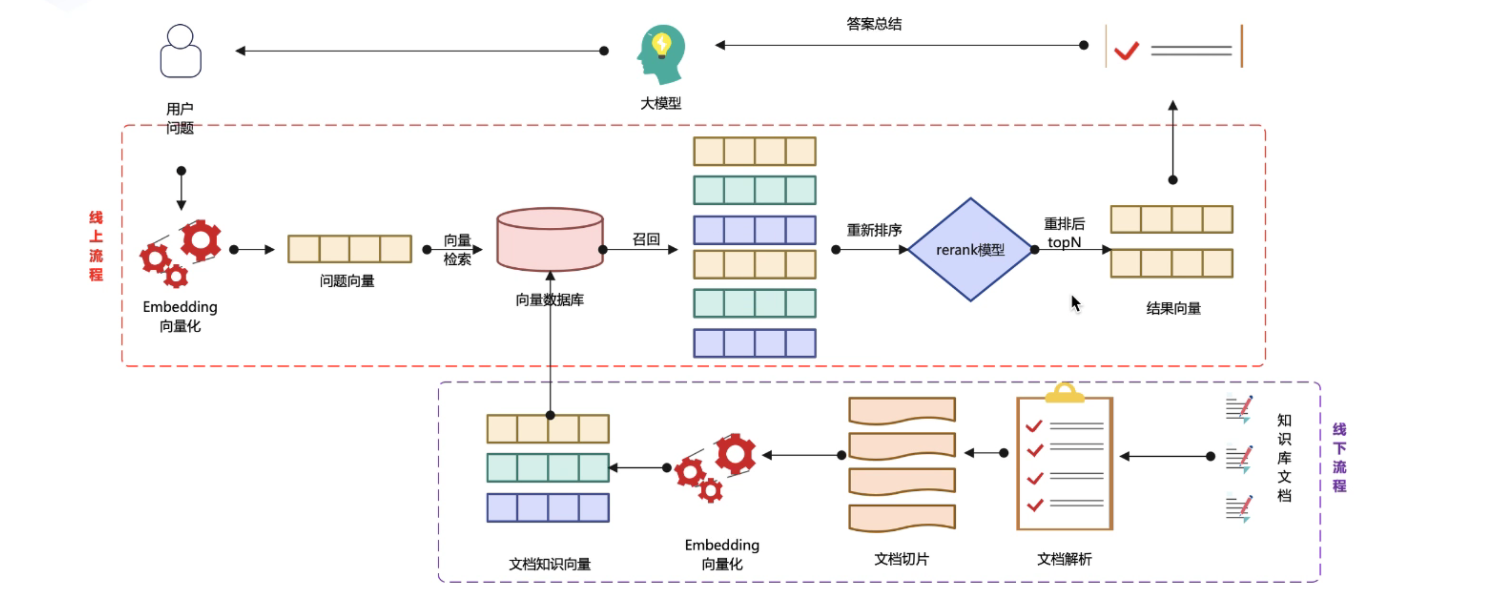
好了,我们看一下整体的实现思路:
-
数据准备:解析文档中的商品信息
-
数据切片:商品信息按照一定规则进行切片
-
向量化:对切片信息进行向量化处理
-
数据存储:将商品信息及其向量信息存储到向量数据库
-
数据检索:将检索的内容进行向量化存储,利用向量数据库的向量检索能力召回最近似的商品切片信息
-
重排序:对于召回的数据利用重排序算法,按照相似度由高到低重新排序
-
返回数据处理:利用大模型解读排序后的商品切片信息,输出给用户
本文使用python编码。
整体的实现流程如下图所示:
数据准备 & 数据切片
我们准备了一个示例文档,大家可以这个文档来解析商品信息,也可以自己准备对应的数据。
示例数据:https://bcets.bj.bcebos.com/smzdm_product.pdf
准备好数据后,我们使用百度千帆 Appbuilder 的文档解析组件来提取文档内容(详细介绍和使用方法参考 DocParser )
DocParser支持 PDF、JPG、DOC、TXT、XLS、PPT 等 17 种文档内容的解析,可解析得到文档内容、版式信息、位置坐标、表格结构等信息。
我们使用下面的代码解析示例的 PDF 文件:
<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1966
1966

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









