




 本文深入介绍了正则表达式的使用,包括基本符号、匹配方法如贪婪与非贪婪模式,以及re模块的应用,如compile、match、findall、search、group等功能,并提供了实例演示。此外,还讲解了如何使用正则表达式在HTML中查找图片链接。
本文深入介绍了正则表达式的使用,包括基本符号、匹配方法如贪婪与非贪婪模式,以及re模块的应用,如compile、match、findall、search、group等功能,并提供了实例演示。此外,还讲解了如何使用正则表达式在HTML中查找图片链接。
正则表达式
正则表达式入门及应用
正则表达式(regex)是一些由字符和特殊符号组成的字符串
能按照某种模式匹配一系列有相似特征的字符串,例如:[a-z]表示26个小写英文字母
1、使用场景:
垃圾邮件拦截,邮件分类;Web开发验证手机号、邮箱等;爬虫开发正则匹配内容;使用正则表达式进行字符串替换
2、正则表达式中的符号
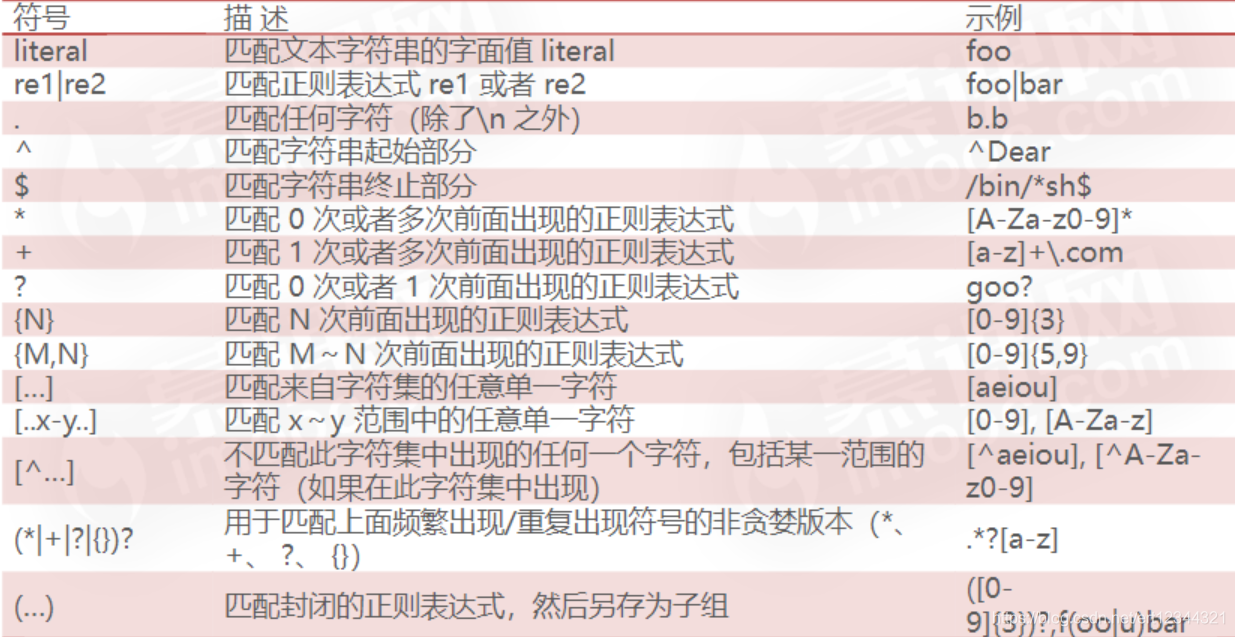


3、使用正则表达式
(1)* 匹配0次或多次(0次或多次指正则表达式前面规定的字符)
例:a*bc
aabcd => aabc
cbc => bc
(2)+匹配一次或多次
例:a+bc
aabcd => aabc
cbc => 无
(3)?匹配0次或者1次
例: a?bc
aabcd => abc
cbc => bc
(4){N}匹配指定的N次
例:a{3}
aaaabc => aaa
(5){M,N}匹配M-N次,最大化优先
例:a{2,5}
aabcd => aa
caaaacd => aaaa
caaaaaaaaacd => aaaaa
4、匹配同类型
(1)\d匹配数字(不考虑小数点)
例:\d
c123d => 1
(2)\w匹配数字和字母
例:\w{3}
he666 => he6
(3)\s匹配任何空格字符
例:a\s{2}a
cccca accc => a a
5、边界匹配
(1)用^匹配以**开头
例:^he.
hello world => hel
shello world => 无
(2)用 $ 匹配以*结尾
例:.ld$
hello world => rld
hello world! => 无
6、匹配特殊字符
需要用“\”进行转义
例:.com
imooc.com => .com
例:http://w+
ssshttp://www.baidu.com => http://www
7、指定匹配选项
(1)使用[]指定要匹配的集合
例:[abc]{2}
cba666 => cb
xba666 => ba
xbb666 => bb
例:[a-zA-Z]{2}
(2)使用[^]指定不要匹配的内容
例: [^abc]{2}
8、正则表达式分组
重复一个字符串时
使用()进行分组,使用(?\w+)指定组名
从左向右,以分组的左括号为标志,第一个出现的分组的组号为1,第二个为2,以此类推
表达式(A)(B( C))分组情况解析:
| 0 | (A)(B)(C) |
|---|---|
| 1 | (A) |
| 2 | ( B ( C )) |
| 3 | ( C ) |
(1)使用()对匹配的内容分组
例;(\d{1,3}.){3}\d{1,3}
(2)使用\1、\2反向引用
例:He (l…e)s her \1r.
He loves her lover.
He likes her liker.
9、贪婪模式vs非贪婪模式
(1)贪婪匹配:
在整个表达式匹配成功的前提下,尽可能多的匹配
例:表达式 ab.+c
测试数据:abacaxcd
匹配数据:abacaxc
(2)非贪婪匹配:
在整个表达式匹配成功的前提下,以最少的匹配字符
只需在匹配pattern中加上“?”
例:表达式 ab.*?c
测试数据:abacaxcd
匹配结果:abac
默认是贪婪模式
重点知识:理解什么是正则表达式以及它的用途;正则表达式的基本语法;正则表达式的编写和验证;正则表达式的分组及反向引用
难点知识:正则表达式的贪婪与非贪婪模式;
正则表达式的分析方法
正则表达式的进阶
1、re模块
使用步骤:
使用complie函数将正则表达式的字符串形式编译为一个Pattern对象
通过Pattern对象提供一系列方法对文本进行匹配查找,获得匹配结果(一个Match对象)
最后使用Match对象提供的属性和方法获得信息,根据需要进行其他的操作
【原始字符串】:正则表达式使用\对特殊字符进行转义;
只需加一个r前缀,正则表达式可以写成:r’python.org’(r代表使用原始字符串,所有字符串都是按照字面意思来使用的)

(1)re模块 - compile
compile(pattern, flags == 0)
使用任何可选的标记来编译正则表达式的模式,然后返回一个正则表达式对象
推荐编译,但不是必须的
(2)re模块 - match
match(pattern, string, flags=0)
match方法用于查找字符串的头部(也可以指定起始位置),它是一次匹配,只要找到了一个匹配的结果就返回,而不是查找所有匹配的结果
尝试使用带有可选的标记的正则表达式的模式来匹配字符串。如果匹配成功,就返回匹配对象;如果失败,就返回None
import re
# 将正则表达式编译
pattern = re.compile(r'hello', re.I)
# 通过match进行匹配
rest = pattern.match('Hello, world!')
print(rest)
2、findall()的使用
格式:findall(pattern, string, flags=0)
:findall(string[, pos[, endpos]])
string是待匹配的字符串,pos和endpos是可选参数,指定字符串的起始和终点位置,默认值分别是0和len(字符串长度)。findall以列表形式返回全部能匹配的子串,如果没有匹配,则返回一个空列表
查找字符串中所有(非重复)出现的正则表达式模式
import re
# 找出以下字符串中的字符
content = 'one1two12Three33four444five5six698'
# 使用编译的对象
p = re.compile(r'[a-z]+', re.I)
rest = p.findall(content)
print(rest)
# 不编译
all_rest = re.findall(r'[a-z]+', content, re.I)
print(all_rest)
3、search()的使用
search(pattern, string, flags=0)
使用可选标记搜索字符串中第一次出现的正则表达式模式。如果匹配成功,就返回匹配对象;如果失败,就返回None
import re
content = 'hello, world!'
p = re.compile(r'world')
# 使用search
rest = p.search(content)
print(rest)
# 使用match
rest_math = p.match(content)
print(rest_math)
# math vs search
# match从开头去寻找,找不到就算了;
# search从头到尾开始寻找,直到把整个字符串找完为止
# 使用函数进行调用
rest_func = re.search(r'world', content)
print(rest_func)
4、group()与groups()的使用
group(num)返回整个匹配对象或编号为num的特定子组
groups():返回一个包含所有匹配子组的元组(如果没有成功匹配,则返回一个空元组)
import re
def test_group():
content = 'hello, world!'
p = re.compile(r'world')
rest = p.search(content)
print(rest)
if rest:
# group的使用
print(rest.group())
# groups的使用
print(rest.groups())
def test_id_card():
""" 身份证号码正则匹配 """
# p = re.compile(r'(\d{6})(\d{4})((\d{2})(\d{2}))\d{2}(\d{1})([0-9]|X)')
p = re.compile(r'(\d{6})(?P<year>\d{4})((?P<month>\d{2})(?P<day>\d{2}))\d{2}(\d{1})([0-9]|X)')
# 准备两个身份证号码
id1 = '430656199610015493'
id2 = '43065619961001548X'
rest1 = p.search(id2)
# 月,日
print(rest1.group(4))
print(rest1.group(5))
# groups
print(rest1.groups())
# groupdict
# 用来打印命名名称的分组
print(rest1.groupdict())
if __name__ == '__main__':
# test_group()
test_id_card()
5、split()正则分割
格式:split(pattern, string, max=0)
:split(string[, maxsplit])
根据正则表达式的模式分隔符,split函数将字符串分割为列表,然后返回成功匹配的列表,分隔最多操作max次(默认分割所有匹配成功的位置)
import re
"""
使用split正则分割字符串
"""
s = 'one1two2three3333four4five5six6'
p = re.compile(r'\d+')
rest = p.split(s, 2)
print(rest)
6、Sub正则替换
格式:sub(pattern, repl, srting, max=0)
:sub(repl, srting[, count])
使用repl替换string中每一个匹配的子串后返回替换后的字符串,最多操作max次(默认替换所有)
import re
"""
使用正则表达式进行替换
replace
"""
s = 'one1two2three3333four4five5six6'
# one@two@three@four@five@six@
# 使用正则替换
p = re.compile(r'\d+')
rest = p.sub('@', s)
print(rest)
# 使用字符串原始的替换方式
rest_origin = s.replace('1', '@').replace('2', '@').replace('3333', '@')
print(rest_origin)
# 使用正则表达式跟换位置
s2 = 'hello today'
p2 = re.compile(r'(\w+) (\w+)')
rest_pos = p2.sub(r'\2! \1', s2)
print(rest_pos)
# 在原有的内容基础上,替换并改变内容
def f(m):
""" 使用函数进行替换规则改变 """
return m.group(2).upper() + ' ' + m.group(1)
rest_change = p2.sub(f, s2)
print(rest_change)
# 使用匿名函数进行替换 lambda
rest_lamb = p2.sub(lambda m: m.group(2).upper() + ' ' + m.group(1), s2)
print('----------')
print(rest_lamb)
7、使用正则匹配图片地址:
import re
# 1. 下载HTML
# 2、写正则的规则
# 要找到Img标签
# 找到src属性
# <img class=" " style="" src="" xx="">
def test_re_img():
"""使用正则表达式找到图片的地址"""
# 1、读取html
with open('img.html', encoding='utf-8') as f:
html = f.read()
#print(html)
# 2、准备正则
p = re.compile(r'<img.+?src=\"(.+?)\".+?>')
# 使用findall找到图片的列表
list_img = p.findall(html)
print(len(list_img))
for ls in list_img:
print(ls.replace('&','&'))
# 使用urllib ,requests将图片保存
if __name__ == '__main__':
test_re_img()

















 1194
1194

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









