



摘要
caption任务是根据当前车辆的拍摄的道路场景前视图,说明路况,给出驾驶建议。此次实验,采用了多教师知识蒸馏+LoRA微调+GRPO训练。微调的basemodel是Qwen2.5-VL-3B-Instruct。选用的三个教师模型分别是MiniCPM-V-2_6、gemma-3-27b-it和InternVL2-8B。在测试集上的评测结果显示在bleu、rouge和语义相似度上明显超越了未训练的Qwen2.5-VL-3B和Qwen2.5-VL-7B。
环境依赖
选择阿里提供的swift微调框架,其对于LoRA微调和GRPO训练封装的很好。使用文档地址:SWIFT安装 — swift 3.10.0.dev0 文档。
大模型部署框架选择vLLM。
数据集构建
数据集的构建策略:三个教师模型根据提供的车辆前视图和我们自定义的prompt生成caption。所以每张图片都将会有三个候选caption,利用我们定义的筛选策略从三个caption中筛选出最合理的caption作为数据集的label。
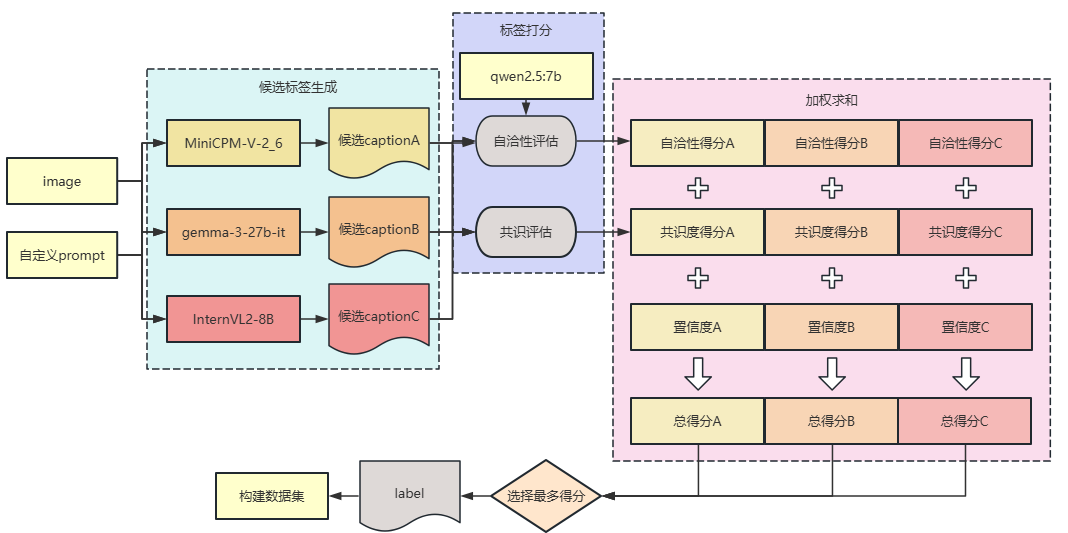
部署教师模型
MiniCPM-V-2_6和gemma-3-27b-it部署使用的vllm版本为0.10.1,InternVL2-8B选择版本为0.7.3。部署指令如下:
python -m vllm.entrypoints.openai.api_server \
--host 0.0.0.0 \
--port 8045 \
--model /gemini/platform/public/HuggingFace/MiniCPM-V-2_6 \
--tensor-parallel-size 2 \
--trust-remote-code自定义prompt
| """你是一款先进的视觉处理 AI,负责分析车辆前方图像以评估驾驶场景。请仔细检查输入图像,并执行以下任务: #### 环境背景: - 时间(黎明/白天/黄昏/夜晚) - 天气状况(晴朗/雨天/有雾/下雪) - 场景类型(城市/乡村/高速公路/停车场) #### 道路与交通分析: - 路面状况和布局 - 交通密度和车辆分布 - 特殊基础设施(路口/环形交叉/人行横道) #### 关键元素识别: - 可见物体的独特特征(车辆、行人、标志) - 空间关系(例如:“左前方有3辆车接近”,“右侧有行人穿越”) - 交通信号灯/标志的状态及其位置参考 #### 驾驶建议: - 当前驾驶建议 - 注意事项 - 后续驾驶建议 """ |
筛选机制
筛选的依据有自洽性评估、教师间共识评估、置信度。将每个部分进行加权求和,得到每个候选caption的评分,选择评分最高的caption作为数据集的label。
自洽性评估
自洽性评估用来评估caption中是否存在语义矛盾。我们选择用大语言模型Qwen2.5-7B作为“评估官”。每次只输入一个候选caption。定义的prompt如下:
| prompt = """ 请严格从以下维度判断以下驾驶场景描述是否存在**“语义矛盾”**(即逻辑冲突、事实冲突、物理不可能),而不是评价其表达是否清晰或合理。 ### 评价维度(仅判断是否存在矛盾) 1. **时间与天气条件是否矛盾** 2. **交通信号灯状态与驾驶建议是否一致** 3. **限速标志与道路类型是否冲突** 4. **车辆位置与道路标识是否相符** 5. **行人/障碍物描述是否与环境一致** 6. **驾驶建议是否与观察到的信息冲突** ### △ 核心原则 - 仅判断“是否存在语义矛盾”,不要评价语言风格、表达清晰度或信息完整性。 ### 📊 评分标准(基于矛盾严重性) - **10分**:完全无矛盾,所有信息可共存且符合物理规律。 ### 📥 输出格式(仅 JSON,无其他文字) { # 【描述】: |
最后从模型输出中提取出评估得分。
教师间共识评估
评估依据是衡量不同教师生成的标签是否“观点一致”,多个教师达成一致的标签,更可能是正确的。
实现很简单,使用sentence_transformer提供的paraphrase-multilingual-MiniLM-L12-v2对caption编码,计算两两caption间的余弦相似度,对于每一条候选caption,计算它与其他所有样本的平均相似度。从而得到每个候选caption的相似度评分。
置信度
置信度也可以作为一个评估依据,研究表明Confidence Is All You Need: Few-Shot RL Fine-Tuning of Language Models,在相同条件下,高置信度生成结果更可能语法正确、语义连贯。
置信度是在教师模型生成caption就计算得到的,方法是计算每个token的平均对数概率,再将其指数运算,就得到了置信度。
合并评估得分
将所有评分加权求和:
alpha = 0.5 # 自治性权重
beta = 0.3 # 教师共识权重
gamma = 0.2 # 教师置信度权重(可选)
final_score_ge = alpha * ge_SCE["score"]/10.0 + beta * consensus_list[0] + gamma * ge_label["confidence"]
final_score_mi = alpha * mi_SCE["score"]/10.0 + beta * consensus_list[1] + gamma * mi_label["confidence"]
final_score_int = alpha * int_SCE["score"]/10.0 + beta * consensus_list[2] + gamma * int_label["confidence"]从而根据最终的得分选择最好的候选caption作为数据集label。
LoRA微调
使用阿里的swift框架进行LoRA微调,冻结vit部分,target_module选择'all-linear'。训练集数据量8986。具体微调指令如下:
nnodes=1
nproc_per_node=2
CUDA_VISIBLE_DEVICES=0,1 \
NNODES=$nnodes \
NODE_RANK=0 \
OMP_NUM_THREADS=12 \
NPROC_PER_NODE=$nproc_per_node \
swift sft \
--model /gemini/platform/public/HuggingFace/Qwen2.5-VL-3B-Instruct \
--dataset /gemini/user/private/ms_swift/ms-swift-main/data_train/train.jsonl \
--split_dataset_ratio 0.005 \
--train_type lora \
--freeze_vit true \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 16 \
--lora_alpha 32 \
--gradient_accumulation_steps 4 \
--eval_steps 200 \
--save_steps 100 \
--save_total_limit 2 \
--logging_steps 5 \
--max_length 12084 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4 \
--dataset_num_proc 4 \
--deepspeed zero2GRPO训练
GRPO训练在于奖励函数的设计,这里我实验了三种奖励函数,分别是以语义相似度为奖励值的奖励函数,以bleu指标为奖励值的奖励函数,以语义相似度、bleu和rouge的和为奖励值的奖励函数。以学习率为1e-4LoRA微调的模型进行进一步的GRPO训练,结果三种方式的评测结果均不如训练前。看了一些经验帖,可能是因为GRPO对数据集的分布和质量要求高,而我的数据集是教师模型生成的,质量并不高。
下面是训练的loss变化和reward的变化:如果有大佬知道是什么原因请评论解答一下,非常感谢!
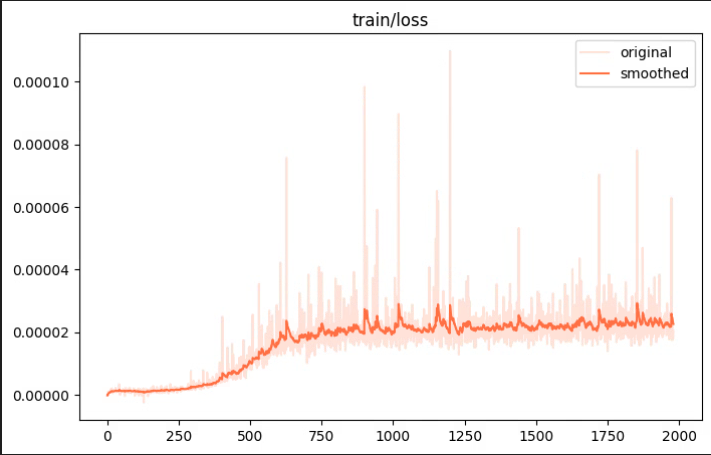
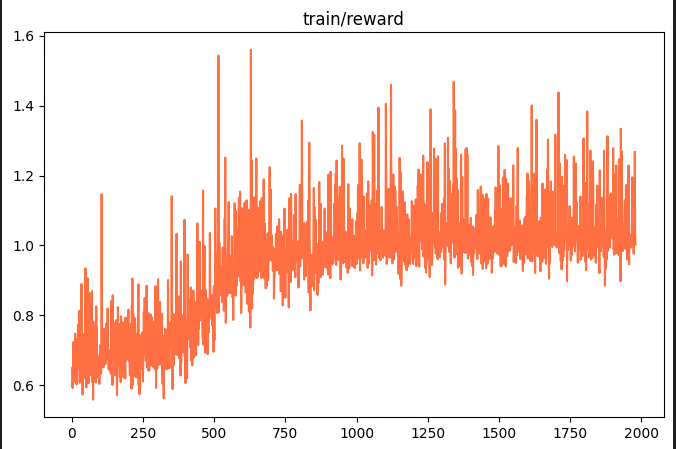
评测结果
LORA微调过程中,我尝试了不同学习率,包括1e-3、1e-4、1e-5、5e-5。
格式化输出能力
按照prompt的要求,应当能够从推理结果中提取出所需的信息。以统一的正则表达式提取每个部分的信息情况下,可以看到微调后的模型更能按照prompt的要求输出信息。下面是不同学习率、未经微调的qwen2.5-vl-3b和qwen2.5-vl-7b模型的对比表:
| 模型 | 1e-3 | 1e-4 | 1e-5 | qwen2.5-vl-3b | qwen2.5-vl-7b | |
| 完整性 | 时间 | 100% | 100% | 10.9% | 12.1% | 100% |
| 天气状况 | 100% | 100% | 10.9% | 12.1% | 100% | |
| 场景类型 | 100% | 100% | 11% | 12.1% | 100% | |
| 路面状况和布局 | 100% | 100% | 10.9% | 12.1% | 99.8% | |
| 交通密度和车辆分布 | 100% | 100% | 10.8% | 12.1% | 99.8% | |
| 特殊基础设施 | 100% | 100% | 10.9% | 12.1% | 100% | |
| 可见物体的独特特征 | 93.3% | 98.2% | 10.9% | 12% | 99.8% | |
| 空间关系 | 100% | 100% | 10.8% | 11.8% | 100% | |
| 交通信号灯灯/标志... | 96.4% | 99% | 1.1% | 0.3% | 0.5% | |
| 当前驾驶建议 | 100% | 100% | 10.9% | 12.1% | 100% | |
| 注意事项 | 100% | 100% | 10.9% | 12.1% | 100% | |
| 后续驾驶建议 | 100% | 100% | 10.9% | 12.1% | 100% | |
| 总体 | 99.14% | 99.77% | 10.08% | 11.08% | 91.66% |
caption指标对比
我选择BLEU、ROUGE和基于sentence_transfomers的余弦语义相似度作为与label评测的指标。测试集共1000条数据。
| 模型 | 1e-3 | 1e-4 | 1e-5 | qwen2.5-vl-3b | qwen2.5-vl-7b | |
| bleu | 时间 | 0.23 | 0.22 | - | - | 0.1 |
| 天气状况 | 0.22 | 0.20 | - | - | 0.02 | |
| 场景类型 | 0.17 | 0.17 | - | - | 0.03 | |
| 路面状况和布局 | 0.26 | 0.24 | - | - | 0.05 | |
| 交通密度和车辆分布 | 0.32 | 0.32 | - | - | 0.04 | |
| 特殊基础设施 | 0.14 | 0.13 | - | - | 0.04 | |
| 可见物体的独特特征 | 0.23 | 0.22 | - | - | 0.02 | |
| 空间关系 | 0.20 | 0.19 | - | - | 0.05 | |
| 交通信号灯灯/标志... | 0.19 | 0.19 | - | - | 0 | |
| 当前驾驶建议 | 0.42 | 0.39 | - | - | 0.08 | |
| 注意事项 | 0.21 | 0.20 | - | - | 0.03 | |
| 后续驾驶建议 | 0.09 | 0.09 | - | - | 0 | |
| 整句 | 0.45 | 0.44 | 0.02 | 0.02 | 0.18 |
| 模型 | avg_rouge1 | avg_rouge2 | avg_rougeL |
| 1e-3 | 0.1299 | 0.0332 | 0.1267 |
| 1e-4 | 0.1161 | 0.0281 | 0.1155 |
| 1e-5 | 0.0431 | 0.0037 | 0.0424 |
| qwen2.5-vl-3b | 0.045 | 0.0067 | 0.0446 |
| qwen2.5-vl-7b | 0.1162 | 0.0282 | 0.1154 |
| 模型 | 1e-3 | 1e-4 | 1e-5 | qwen2.5-vl-3b | qwen2.5-vl-7b | |
| similarity | 时间 | 0.8955 | 0.8887 | - | - | 0.8172 |
| 天气状况 | 0.7002 | 0.6990 | - | - | 0.6123 | |
| 场景类型 | 0.8273 | 0.8256 | - | - | 0.6871 | |
| 路面状况和布局 | 0.8590 | 0.8514 | - | - | 0.7690 | |
| 交通密度和车辆分布 | 0.8763 | 0.8719 | - | - | 0.7504 | |
| 特殊基础设施 | 0.8122 | 0.8076 | - | - | 0.6341 | |
| 可见物体的独特特征 | 0.7279 | 0.7412 | - | - | 0.6103 | |
| 空间关系 | 0.7799 | 0.7719 | - | - | 0.6915 | |
| 交通信号灯灯/标志... | 0.7452 | 0.7587 | - | - | 0.1543 | |
| 当前驾驶建议 | 0.8814 | 0.8755 | - | - | 0.7482 | |
| 注意事项 | 0.8186 | 0.8119 | - | - | 0.6938 | |
| 后续驾驶建议 | 0.7959 | 0.7921 | - | - | 0.6979 | |
| 整句 | 0.9465 | 0.9447 | 0.7150 | 0.7167 | 0.9082 |
可视化结果


改进建议
1.教师模型可以改用更新更强的模型。
2.每个教师模型只输出了一个caption,使得评估时的候选caption数量太少,可以一个教师生成多个候选caption。
3.自洽评估是一次只输入一个候选caption,没有对比,可以改为一次输入所有候选caption得到相对评分。

















 1073
1073

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









