







 超级会员免费看
超级会员免费看
词袋模型
从输入的语料库中生成词袋。
输入
- 语料库:一组文档的集合。
输出
- 语料库:附加了词袋特征的语料库。
词袋模型创建一个包含每个数据实例(文档)词频的语料库。词频可以是绝对计数、二进制(是否出现)或次线性(词频的对数)。词袋模型通常与词富集结合使用,也可用于预测建模。
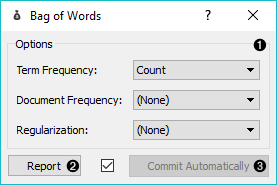
- 词袋模型参数:
- 词频计算方式:
- 计数:单词在文档中出现的次数。
- 二进制:单词是否在文档中出现。
- 次线性:词频(计数)的对数。
- 文档频率计算方式:
- (无)
- IDF:
- 词频计算方式:
从输入的语料库中生成词袋。
输入
输出
词袋模型创建一个包含每个数据实例(文档)词频的语料库。词频可以是绝对计数、二进制(是否出现)或次线性(词频的对数)。词袋模型通常与词富集结合使用,也可用于预测建模。
 1475
665
1095
1475
665
1095

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文


























