




 本文详细探讨了Redis分区的四种方法:Hash、一致性Hash、Codis的Hash槽和RedisCluster,分析了各自的优缺点及适用场景。重点讨论了数据分区在实现高可用性和扩展性方面的挑战,如数据迁移、负载均衡和系统复杂性,帮助读者选择适合的分区方案。
本文详细探讨了Redis分区的四种方法:Hash、一致性Hash、Codis的Hash槽和RedisCluster,分析了各自的优缺点及适用场景。重点讨论了数据分区在实现高可用性和扩展性方面的挑战,如数据迁移、负载均衡和系统复杂性,帮助读者选择适合的分区方案。
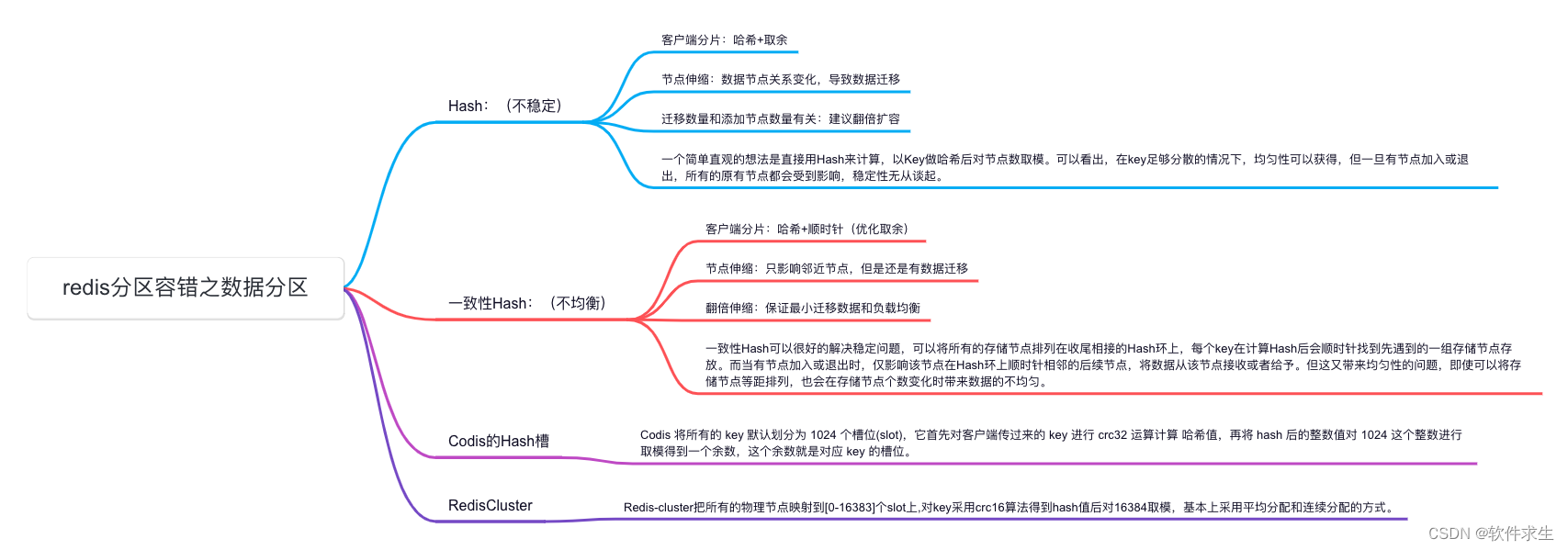
大家好!我是你们的技术小伙伴小米~今天我们要聊一聊Redis分区容错问题中的数据分区这个话题。在大数据量的应用中,合理的数据分区是至关重要的。我们会从Hash、一致性Hash、Codis的Hash槽以及RedisCluster四个方面来探讨。快来一起学习吧!
Hash:基础但不稳定
在Redis的分布式环境中,数据分区是为了将数据存储在多个节点上,以实现更好的负载均衡和可扩展性。Hash是Redis中常见的一种数据分区方式,但它存在一些局限性,需要我们深入探讨。
Hash函数的基本原理
Hash函数是一种将输入(通常是key)转换为固定长度输出(通常是整数)的算法。在Redis中,Hash函数可以将key映射到一个整数值,然后通过取模运算(通常基于节点数量)确定数据应存储在哪个分区。这种分区方式通常称为“哈希分区”或“key分区”。
Hash分区的优点
- 简单易用:Hash函数的使用简单直接,只需对key进行一次哈希计算,就能得到数据所属的分区。这种方法便于理解和实现。
- 快速查询:因为每个key对应一个固定的分区,所以查询数据时只需访问对应的分区,速度较快。
Hash分区的缺点
尽管Hash分区有许多优点,但它也存在一些明显的缺陷:
- 数据迁移问题:一旦节点数量发生变化(增加或减少节点),所有数据的哈希值都会改变。这意味着大量数据需要重新分配到新的分区,这会导致系统的负载增加,并可能引起服务中断。
- 分区不均衡:Hash分区可能导致数据在各分区之
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











