




 本文介绍了图的基本存储方式——邻接矩阵与邻接表,以及两种常用的图遍历算法:深度优先搜索(DFS)与广度优先搜索(BFS)。详细展示了不同存储方式下遍历的具体实现。
本文介绍了图的基本存储方式——邻接矩阵与邻接表,以及两种常用的图遍历算法:深度优先搜索(DFS)与广度优先搜索(BFS)。详细展示了不同存储方式下遍历的具体实现。
图
图的存储方式有两种:邻接矩阵和邻接表。
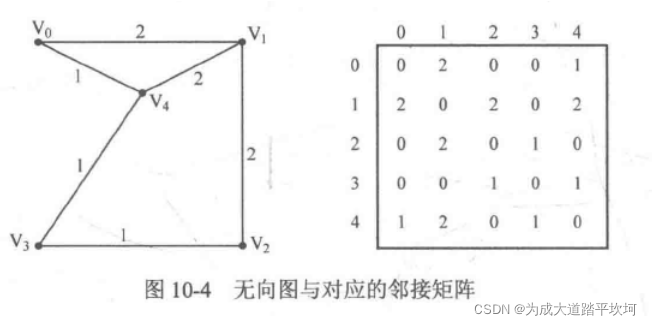
邻接矩阵
用二维数组来表示顶点之间是否存在边,边的权重为多少。对于无向图来说,邻接矩阵是一个对称矩阵。缺点是邻接矩阵虽然比较好写但是需要开辟一个二维数组,如果顶点数量太多,容易超过题目的内存限制。
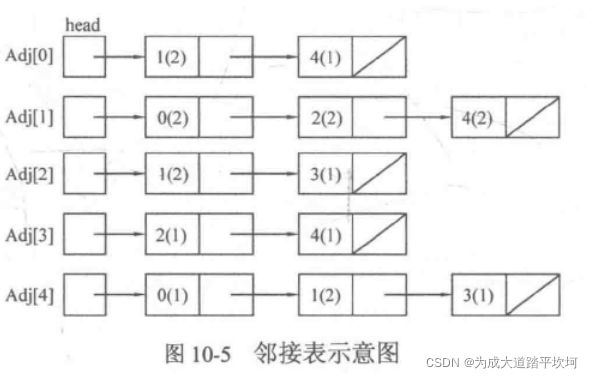
邻接表
把同一个顶点的所有出边都放在一个列表中,那么N个顶点就会有N个列表,这N个列表就是图G的邻接表,记为Adj[N]每个结点会存放一条边的信息(括号外的数字是边的终点编号,括号内的数字是边权。
对于初学者来说,使用变长数组vector来表示邻接表更为简便。
如果邻接表只存放每条边的终点序号而不存放权重,则vector中的元素类型可以直接定义为int类型vector<int>Adj[N];如果想添加一条3号结点到1号结点的有向边,那么就需要Adj[3].push_back(1);
如果邻接表中还需要存放边权,则vector的元素类型使用结点Node结构体,代码如下:
struct Node{
int w;//边权
int v;//边的终点序号
};
此时要添加一条3号结点到1号结点的权重为2的有向边,代码如下:
Node temp;
temp.w=2;
temp.v=1;
Adj[3].push_back(temp);
最快速的写法是给结构体提供构造函数,在添加过程中直接加入临时结点,代码如下:
struct Node{
int w,v;
Node(int _w,int _v):w(_w),v(_v){}
};
Adj[3].push_back(Node(2,1));
图的遍历
遍历方法一般有两种:深度优先搜索DFS和广度优先搜索BFS。
DFS
思想:沿着一条路径直到无法继续前进,才退回路径上离当前顶点最近的还存在未被访问的结点的岔路口,并继续访问那些分支顶点,直到完成遍历整个图。
实现:将经过的顶点设置为已访问,在下次递归遇到这个顶点的时候就不再处理,直到整个图的顶点都被标记为已访问。伪代码如下:
DFS(u){
vis[u]=true;//设置u已被访问
for(从u出发能到达的所有顶点v)
if vis[v]==false //如果v未被访问
DFS(v);//递归访问v
}
DFSTrave(G){ //遍历图G
for(G的所有顶点u){ //对图G的所有顶点
if vis[u]=false //如果u未被访问
DFS(u); //访问u所在的连通块
}
}
邻接矩阵DFS
const int MAXV=1000;
const int INF=1000000000;
int n,G[MAXV][MAXV];//n为顶点数,MAXV为最大顶点数
bool vis[MAXV]={false};//将所有结点的访问状态初始化为未访问
void DFS(int n,int depth){//u为当前访问的结点符号,depth为深度
vis[u]=true;
//遍历从u出发可以到达的所有结点
for(int v=0;v<n;v++){
if(vis[v]==false&&G[u][v]!=INF){//如果v未被访问,且u可以到达v
DFS(v,depth+1);
}
}
}
void DFSTrave(){
for(int u=0;u<n;u++){//对每个顶点u
if(vis[u]==false){//如果当前顶点u未被访问
DFS(u,1);//访问每个顶点u所在的连通块,表示第一层
}
}
}
邻接表版本DFS
const int MAXV=1000;
const int INF=1000000000;
vector<int>Adj[MAXV];
int n;
bool vis[MAXV]={false};
void DFS(int u,int depth){
vis[u]=true;
for(int i=0;i<Adj[u].size();i++){//遍历当前结点u后连接的所有出度点
int v=Adj[u][i];
if(vis[v]==false){
DFS(v,depth+1);
}
}
}
void DFSTrave(){
for(int u=0;u<n;u++){
if(vis[u]==false){
DFS(u,1);
}
}
}
两个结构的DFS区别主要是由于图的表示方法不同,所以在找某个结点下一层的其他结点时,使用邻接矩阵需要遍历所有的位置,查找未被访问的且与该点连接的点。而邻接表只需要查找当前结点后面连接的表即可,不必遍历所有结点。
BFS
思想:每次以扩散的方式访问顶点。从搜索的起点开始,不断地优先访问当前结点的邻居,也就是说,首先访问起点,然后依次访问起点尚未访问的邻居结点,然后根据访问起点邻居结点的先后顺序依次访问他们的邻居,直到找到解或者搜遍整个空间。
步骤:需要建立一个队列,将初始顶点加入队列,通过反复取出队首顶点,将该顶点可到达的未曾加入过队列的顶点全部入队,直到队列为空时遍历结束。伪代码如下:
BFS(u){
queue q;
inq[u]=true;
while(q非空){
for(从u出发可达到的所有顶点v){
if(inq[v]==false){
将v入队
inq[v]=true;
}
}
}
}
BFSTrave(G){
for(G的所有顶点u){
if(inq[u]==false){
BFS(u);
}
}
}
邻接矩阵BFS
int n,G[MAXN][MAXN];
bool inq[MAXN]={false};
void BFS(int u){//遍历u所在的连通块
queue<int> q;//定义队列
q.push(u);//将初始点u入队
inq[u]=true;//设置u已加入过队列
while(!q.empty()){//只要队列非空
int u=q.front();//取出队首元素
q.pop();//将队首元素出队
for(int v=0;v<n;v++){
//如果u的邻接点v未曾加入过队列
if(inq[v]==false&&G[u][v]!=INF){
q.push(v);//将v入队
inq[v]=true;//标记v为已加入过队列
}
}
}
}
void BFSTrave(){
for(int u=0;u<n;u++){
if(inq[u]==false){
BFS(u);
}
}
}
邻接表版本
vector<int> Adj[MAXV];
int n;
bool inq[MAXV]={false};
void BFS(int u){//遍历单个连通块
queue<int> q;//定义队列
q.push(u);//将初始结点入队
inq[u]=true;//设置u已经加入过队列
while(!q.empty()){//只要队列非空
int u=q.front();//获取队首元素
q.pop();//弹出队列
for(int i=0;i<Adj[u].size();i++){//枚举从u出发可以到达的顶点
int v=Adj[u][i];
if(inq[v]==false){//如果v未曾入队
q.push(v);//将v入队
inq[v]=true;//设置为已加入过队列
}
}
}
}
void BFSTrave(){//遍历图G
for(int u=0;u<n;u++){//枚举所有顶点
if(inq[u]==false){//如果顶点u未曾加入过队列
BFS(q);//遍历u所在的连通块
}
}
}
图模板
Graph类使用map存放结点信息,使用set存放边的信息
class Graph{
public:
unorder_map<int,Node*>nodes;
unorder_set<Edge*>edges;
Graph(){};
};
Node类由五部分组成,分别是节点的值value、入度in、出度out、当前结点的下一个节点nexts、以及从当前结点出发的边edges
class Node{
public:
int value;
int out;
int in;
vector<Node*>nexts;
vector<Edge*>edges;
Node(int val,int inn=0,int outt=0):value(val),in(inn),out(outt){}
};
Edge类由三部分组成,分别是权重weight、当前边的from和to结点
class Edge{
public:
int weight;
Node* from;
Node* to;
Edge(int w,Node* f,Node* t):weight(w),from(f),to(t){}
};
将产生图函数封装成类,采用的是邻接矩阵的方式。图的构建过程如下所示:
- 实例化一个Graph对象,对数组按行遍历,取出每行数据对应的权重、from和to结点
- 判断当前图中的from和to结点是否存在,不存在则需要创建节点
- 用form和to结点创建边
- 丰富form结点的指向结点to、边、出度,丰富to结点的入度。
- 把建好的边添加到图里的边
class GraphGenerator{
public:
Graph graph;
for(int i=0;i<matrix.size();i++){
//循环读取二维数组中的信息
int weight=matrix[i][0];
int from=matrix[i][1];
int to=matrix[i][2];
//如果这两个点没在图中出现过,就初始化这个点
if(graph.nodes.find(from)==graph.nodes.end()){
graph.nodes[from]=new Node(from);
}
if(graph.nodes.find(to)==graph.nodes.end()){
graph.nodes[to]=new Node(to);
}
//从图中取出这两个点,丰富点的信息
Node* fromNode=graph.nodes[from];
Node* toNode=graph.nodes[to];
//将读取到边权重和两端信息初始化一个边对象
Edge* newEdge=new Edge(weight,fromNode,toNode);
//丰富fromnode的信息,包括指向的结点、边、出度增加
fromNode->nexts.push_back(toNode);
fromNode->edges.push_back(newEdge);
fromNode->out++;
//丰富toNode的信息,入度增加
toNode->in++;
//将生成的这条边添加到图对象的边集合成员对象中
graph.edges.insert(newEdge);
}
return graph;
};
图搜索
void BFS(Node* head) {
if (head == NULL)return;
queue<Node*>q;
unordered_set<Node*>s;//使用set来判断节点是否加入过队列
q.push(head);//将首结点加入队列
s.insert(head);
while (!q.empty()) {//只要队列不为空,就一直循环
Node* cur = q.front();//取当前队首元素,并弹出
cout << cur->value << " ";
q.pop();
for (Node* n : cur->nexts) {//遍历该节点的所有相邻(下一层)节点
if (s.find(n) == s.end()) {//如果这个结点没有加入过队列
s.insert(n);//就将节点标记为已访问过,并入队
q.push(n);
}
}
}
}
void DFS(Node* head) {
if (head == NULL)return;
stack<Node*>st;
unordered_set<Node*>se;
//将头结点入栈并记录
st.push(head);
se.insert(head);
cout << head->value << " ";
//只要栈不为空,就一直循环
while (!st.empty()) {
//弹出栈顶元素作为当前结点
Node* cur = st.top();
st.pop();
//遍历当前结点的所有下一层结点,若没有下一层结点或者下一层结点都被访问了,那么就不断执行上两句程序
//栈中结点不断弹出,直到找到当前结点的下一层结点或者栈弹空。
for (Node* n : cur->nexts) {
if (se.find(n) == se.end()) {//如果这个下一层结点未被访问过
st.push(cur);//则继续深入,就需要将当前结点和下一层结点都压入栈中
st.push(n);
se.insert(n);//标记访问了这个下一层结点
cout << n->value << " ";
break;//找到了一个下一层结点,那么就退出当前循环,继续深入查找
}
}
}
}

















 1057
1057

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









