



1 具身智能
1.0 为什么要研发具身智能
- 全球劳动力短缺,我国人口红利退去,导致用工成本变高;
- 持续的重复性/高体力的工作导致职业倦怠;
- 高危职业减少人类参与,符合道德原则,符合人类对职业安全的诉求。
最近有一个精炼的术语,可以概括上述的2-3点,Dull, Dirty, Dangerous,枯燥 肮脏 危险的。
From FigureAI’s Grant Hosking
We’re really having our iPhone moment here, in which we believe will be the biggest industry in our lifetime
1.0.1 为什么要人形机器人
因为目前工厂流水线 / 家庭电器设备等都是为人类设计的,为了让机器人能够更适配这些场景,所以需要人形机器人。
1.1 市场规模
已知全球劳动力人口36亿人,假设每个人年薪为8k USD,那么
36亿 * 8k USD = 288k 亿 USD = 30 万亿 USD
1.2 具身智能分级
北京人工智能研究院等研究人员在论文《Toward Embodied AGI: A Review of Embodied AI and the Road Ahead》中提出了具身智能的5个等级,如下所示:
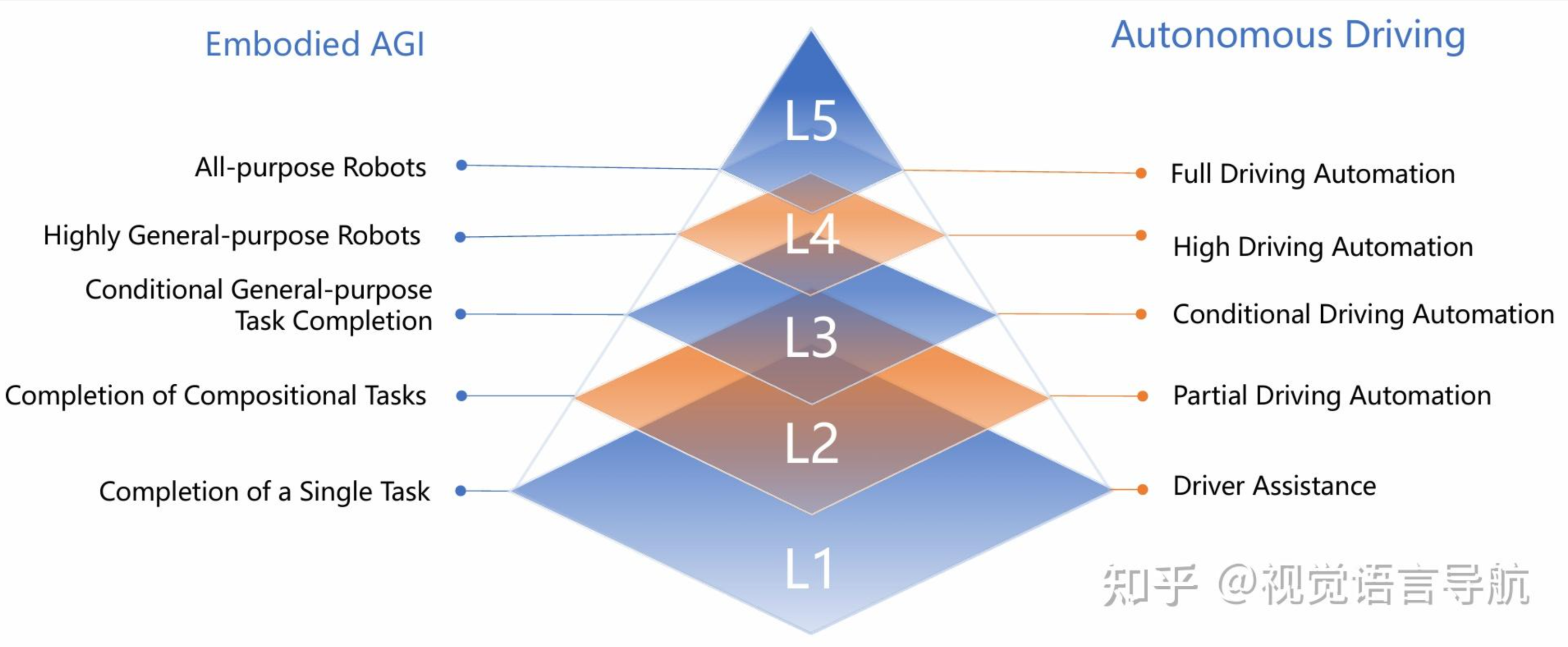
该分类是从任务完成能力的角度去划分的,类似自动驾驶。
- Level 1,完成单个(见过的)任务,不强调泛化性;
- Level 2,完成多个组合的(见过的)任务,具备任务拆解能力,不强调泛化性;
- Level 3,具备一定的泛化能力,但是开放式场景不一定cover;
- Level 4,具备高度稳健的泛化能力;
- Level 5,能够满足人类正常生活的各种需求。
1.3 短期发展趋势与长期发展趋势
1.3.1 短期发展趋势:提升泛化性
近年来,具身智能领域正在经历转变:从任务专用模型到通用基础模型。
何为通用?需要满足下述的能力:
- 感知能力。能够感知并理解当前的环境。
- 自主推理能力。知道自己要做什么。
- 行动能力。像人一样灵活行动。
当前,通用基础模型从端到端逐步走向分层式。目前主流的分层式算法类似人类的大小脑。
大脑:处理语言和视觉信息,理解环境和指令,给出高级决策。
小脑:基于大脑的高级决策,生成具体的控制指令。
举例:别人向我扔飞盘,大脑输出“接住它”的指令,小脑输出手脚的协同控制指令,用什么力度,在什么位置接住等。
1.3.2 长期发展趋势:提升多模态和认知能力
为了实现L5,需要全面提升多模态能力和认知能力。
- 多模态能力匮乏。目前具身智能基本以视觉和语言为输入,关节角度为输出。但是触觉/嗅觉等信息并为使用,且基本不具备语言沟通能力。
- 认知能力不足。目前具身智能只对任务具备认知能力,但是为了无缝衔接到人类正常生活中,需要情感分析,社交能力,社会理解能力。
1.4 当前卡点
1.4.1 卡点1:算法领域数据不足
目前大脑(VLM)进展迅速,小脑进展缓慢。因为大脑的训练数据仅仅来自于网络,是很充分的;小脑的训练数据目前相当匮乏,对于物理世界的理解仍不充分。
数据不足的核心原因:
- 数据采集成本过高:遥操作设备大约35w RMB / 台
- 缺乏统一采集标准:硬件决定的数据需求不统一,数据格式不统一,没有数据托管平台
- 跨模态融合能力不足:物理世界信息涉及视觉,指令,动作(力觉,触觉)。
能够支持机器人普遍应用的所需的数据量,暂时没有定论。
比如,特斯拉Optimus的数据量大约在百万小时级别,能够让Optimus在工厂工作。
真机数据和仿真数据的比例:1:9 - 1:10,但没有定论。
参考:https://www.thepaper.cn/newsDetail_forward_29953659
1.4.2 卡点2:硬件领域价格太高
- 成本太高,本体预期要降低至2-3w USD才可以接受
2 具身智能开发pipeline
2.1 数据采集
2.1.1 真机数据
常见方案:
- 腕部动作捕捉:VIVE Ultimate Tracker,捕捉腕部6DOF运动
- 手部动作捕捉:
a. Xsens Metagloves手套,依赖接触式测量
b. Apple Vision Pro,遥操作,非接触式,机器视觉算法
c. Leap Motion ,遥操作,非接触式,机器视觉算法 - 视觉信息:头戴式激光雷达 / 摄像头
下图为Apple Vision pro的数采方式。

2.1.2 合成数据
合成数据是指微调真机数据,产生分布不同的数据。比如调整光照,物体位置/类型/颜色等。
下图为调整物体位置的合成数据示例。

注意,因为要生成高保真的数据,因此该过程很耗时。比如GR00T要2min生成1帧,为了生成827h的数据,消耗105k【GPU小时】,用了3600块GPU,跑了1.5天。相当于一个GPU要跑10w小时。
2.1.3 仿真数据
可以在仿真环境中,采用相应的工具生成安全无碰撞的轨迹。
-
Gazebo环境 + moveit规划库。优点是支持ROS环境,并且适用于moveit;缺点是无法并行,生成速度慢,与深度学习继承低。moveit输入:目标位置
moveit输出:关节轨迹
注意:moveit是ROS生态下的产品,和Issac Gym是隔绝的。
2.1.4 网络数据
网络数据缺少标签,但是可以通过下述方法获得伪标签,从而对齐数据模态。
- IDM。通过少量真机数据训练之后,给网络数据打动作标签。
- LAPA。通过VQ-VAE压缩动作表征,可以得到潜在动作标签。
2.2 动作重定向 retargeting
输入:末端位姿
输出:各关节角度
由动作捕捉设备得到的末端位姿无法用于机器人控制,因为:
- 控制量不同。机器人控制最终要求的是关节角度,而角度不是动捕的输出,需要进行转换。
- 自由度差异。人手臂有7个自由度,但是机械臂如果只有6个自由度,那么有些动作做不了。
- 关节旋转幅度/肢体长度差异。比如人手腕能旋转180度,但是机械臂可能无法旋转那么多;人手臂长度和机械臂长度不同,均会导致有些动作做不了
因此,需要通过重定向技术将人类动作映射成机器人可达的动作。
关键技术:逆运动学Inverse Kinematics
2.3 模型搭建与验证
主要分为上肢模型和下肢模型。需要分别搭建相应的模型。
输入:真实动作(关节角度),视觉图像,语言指令
输出:预测动作
具体算法详见第3节。
2.4 真机部署
3 具身智能算法
3.1 操作 Manipulation
操作算法经历了如下3个阶段:
- 示教编程(Teaching Programming):人拖动机器人手臂,记录轨迹,然后重复执行。缺少泛化性。
- 机器视觉 + 传统规划,模块化范式。采用目标检测算法进行检测,然后调用运动规划算法生成轨迹。流程模块化,泛化性不强,类似智能驾驶的传统规控方案。
- 早期模仿学习与强化学习。针对单一任务进行训练,无法泛化到新任务。
3.1.1 模块化经典范式
传统方案是分模块进行的。
- 目标识别前处理,先识别出需要操作的物体。依赖2D检测(如YOLO),3D实例分割(如PointNet++),甚至VLM模型(如Grounding DINO 开放词汇目标检测),确定需要抓取的物体,获取其2D图像 / 3D点云的掩码。将视觉信息和掩码联合,计算出仅有目标物体的2D / 3D信息。
- 目标识别与决策。根据目标物体的信息,生成6DoF的抓取位姿,比如AnyGrasp。
- 机械臂运动规划与控制,比如Moveit!。
3.1.2 LLM混合驱动范式
LLM混合驱动范式的核心是依赖LLM对任务进行拆解,然后自主调用工具完成任务。举例如下:帮我泡一杯水。
LLM拆解与工具调用:
- 去厨房。使用AMCL + Nav2。
- 打开橱柜。运动规划 + 力控。
- 拿杯子。AnyGrasp + MoveIt
- 倒水。阻抗控制 + 视觉伺服。
3.1.3 端到端范式
| 论文 | 入选原因 | 年份 | 团队 |
|---|---|---|---|
| RT-1: Robotics Transformer for Real-World Control at Scale | 将Transformer成功移植到机器人上,之前是CNN/RNN;通用性:在RT-1前一个模型通常只学1-2种技能,RT-1证明了保证数据集的丰富性的情况下,一个机器人可学习多种技能; | 2022 | |
| RT-2: Vision-Language-Action Models Transfer Web-Scale Knowledge to Robotic Control | 在RT-1的基础上引入VLM,是VLA范式的开创者,而不是RT-1端到端的框架,实现了互联网知识在物理世界的应用 | 2023 | |
| ACT: Action Chunking with Transformers for Low-Level Imitation Learning Control | 提出高效的模仿学习算法,通过小批量(短短几十次)遥操作演示,就可以学习,证明不需要上述谷歌量级的数据,激发了学界和工业界的热情 | 2023 | Stanford |
| OpenVLA: An Open-Source Vision-Language-Action Model for Robot Control | 数据/算法/权重开源的贡献超过技术本身,将技术平民化,而不是被掌控在少数公司手里;第一个证明异构数据能够训练出具备强大泛化能力的机器人的方案 | 2024 | Stanford |
| π0: A Vision-Language-Action Flow Model for General Robot Control | 第一个使用flow matching的方案,而不是之前的diffusion,基于ODE常微分方程,训练更简单,推理更快,解决diffusion的痛点 | 2024 | Physical Intelligence |
| GR00T N1: An open foundation model for generalist humanoid robots | 如果上述的贡献是算法级,那么GR00T的贡献就是平台级。提出了数据金字塔,系统整合了多源异构数据。基座模型具备快速迁移和部署能力。 | 2025 | 英伟达 |
| GR-3 | 之前模型能对未见物品进行泛化,GR-3能够对未见任务/复杂指令具备泛化能力;精细操作+长时序任务能力 | 2025 | 字节跳动 |
3.2 行走 Locomotion
双足机器人分为传统方案和基于学习的方案。
传统方案依赖精确的动力学模型和复杂的控制理论(如MPC),在特定环境中是成功的(如自动驾驶),但是现实世界过于复杂和不确定,导致该方法鲁棒性不足。
3.2.1 重要方案
| 模型 | 入选原因 | 年份 | 团队 |
|---|---|---|---|
| Learning to Walk in the Real World with Minimum Real-World Data | 之前基于学习的行走都是在仿真中,该论文提供了sim2real的技术路径,证明强化学习能够在现实世界中控制机器人行走 | 2019 | 佐治亚理工 |
| AMP: Adversarial Motion Priors for Stylized Physics-Based Character Control | 1. 在机器人能走之后,该论文使行走动作更自然。使用了判别器判断机器人的动作和人的动作,促使机器人走的更像人。其创新性的判别器设计让模仿问题变成了更容易解决的分类问题;2.IL和RL结合。 | 2021 | UC Berkely / Goole |
| HiFAR: Pushing the Limits of High-Fidelity Autonomous Recovery for Legged Robots | 解决了从摔倒到站立的问题。在这之前,鲁棒性指的是避免摔倒,现在扩展到摔倒后如何自主恢复,极大提升了实用性 | 2023 | SJTU / Huawei |
| Dreamer系列 | 提出了新的训练范式:先学习一个世界模型,然后agent在世界模型中进行试错,学习策略,就像做梦一样 | 2020- | 多伦多大学 / Deepmind |
3.3 具身智能核心算法
3.3.1 深度学习方面
3.3.3.1 flow matching
Diffusion算法的变体,算法原理更简单,推理速度更快,常常用到VLA模型的action模块。
3.3.3.2 GAIL
不管是具身智能,还是自动驾驶,都想要模型既拟人化,又具备泛化能力。其中拟人能力依靠专家数据,泛化能力依靠在环境中的自主探索和试错。如何取得两者的平衡是一个至关重要的问题。
针对Offline RL,可以简单粗暴地同时使用RL reward + IL loss,因为策略网络和环境不具备交互能力。但是这样做约束了策略的探索能力,对于out of distribution的问题依然无法很好的解决。
因此,使用GAIL,用判别器判别策略轨迹是否拟人,是一个更优秀的选择。判别器并不会直接将策略网络的输出和专家轨迹进行比较,而是判别器学习到专家轨迹的行为模式,从而进行判别。这样不仅能够用Online RL,而且在模仿专家方面也不会如上述那么粗暴了。
3.3.2 数学方面
3.3.2.1 李群与李代数
欧拉角的问题:
- 万向锁。由于欧拉角的顺序性,沿中间轴旋转90度时,导致另2轴重合,失去了一个自由度。如下图所示,蓝圈旋转和绿圈旋转的自由度是一样的。本质原因是欧拉角是用于描述旋转的,而不是用于描述运动的。因此在自动驾驶/具身智能中,如果使用欧拉角就会带来万向节死锁问题。
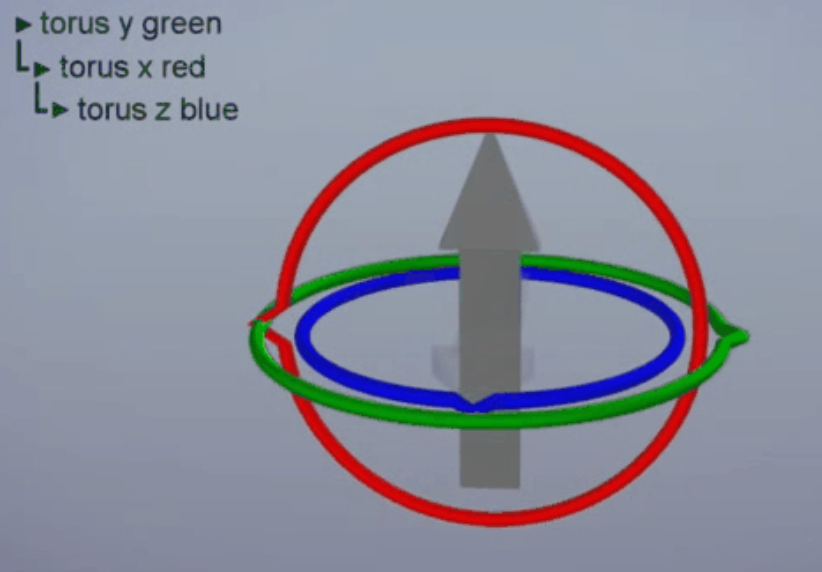
- 旋转矩阵是有约束的——正交性约束,即R^T * R = I,因此不能随便改。这对深度学习并不友好。
四元数的问题:
- 维度冗余。用四个数描述三个方向的旋转,本质上是冗余的,因此受到单位长度的约束。这样的约束对深度学习不友好。
- 双重覆盖。q和-q表示的同一种旋转。因此对插值计算并不友好。
李群与李代数是一种更自然和鲁棒的方案,能克服上述问题:李代数用增量(本质上是3个方向的角速度构成的向量)来描述角度变化,
- 没有死锁问题,
- 没有单位约束 / 正交性约束的问题
- 能够让模型直接建模增量,更符合控制需要。
其通过指数映射,将原旋转矩阵R变成新的旋转矩阵R_new。
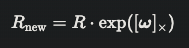
但是也要注意,并非所有关节都需要用李群与李代数进行建模。比如单自由度旋转关节因为只有一个旋转角度,可以直接建模;滑动关节在线性空间,不需要旋转;只有球状关节才需要用李群与李代数。
3.4 基于规则的算法
moveit:提供OMPL,CHOMP,STOMP可供生成轨迹。
- OMPL(Open motion Planning Library)
- CHOMP(Covariant Hamiltonian Optimization for Motion Planning)
- STOMP(Stochastic Trajectory Optimization for Motion Planning)
一般用OMPL生成粗轨迹,然后再用CHOMP进行优化。
4 机器人产业链
脑 + 身体 -> 组装
4.1 脑
硬件:英伟达芯片
软件:VLA模型
4.2 身体
总的来看,身体内部结构主要分为4种:
- 传感器,包括视觉传感器,力传感器等
- 执行器,包括线形执行器(Linear Actuator),旋转执行器(Rotary Actuator),==灵巧手(Dexterous Hand)==等
- 动力系统,包括电池,充电装置
- 结构件,包括机器骨架(碳纤维,铝合金等),面罩等
4.3 手
一般而言,一只手(不含手腕,手腕算到手臂上)有21个自由度
4根手指有16个自由度(4 x 4),而大拇指有5个自由度。其中:
-
4根手指(fingers),每根手指有3个关节,4个自由度,其中:
a. 掌指关节,能够屈伸(握拳和张开)和内收外展(并拢和张开),2DOF
b. 近端指间关节,能够屈伸,1DOF
c. 远端指间关节,能够屈伸,1DOF -
大拇指(thumb),有3个关节,5个自由度,其中:
a. 腕掌关节,屈伸和内收外展,2DOF
b. 掌指关节,屈伸和内收外展(很神奇,跟腕掌关节一样),2DOF
c. 指间关节,屈伸,1DOF
因此,一只手有21个自由度。
注意:人的手是欠驱动(under-actuated)系统,即肌肉数量<关节自由度,由此导致部分动作耦合。比如手指的远端关节屈伸时,几乎必然带动近端关节屈伸。
4.3.1 机械手
当制作机械手时,不能在技术未达到的情况下盲目增加自由度,否则不仅不灵巧,反而带来维度灾难,控制困难。
自由度从低到高为:
- 工业夹爪:1-3DOF,如二/三指夹爪
- 灵巧手:11DOF+
下图是Robotiq的2指夹爪:

下图为Shadow Robotic的Shadow Dexterous Hand,有24个自由度。

4.4 手臂
手臂有3个关节,7个自由度,其中
- 肩关节:3个旋转自由度
- 肘关节:1个旋转自由度
- 腕关节:3个自由度
4.5 腿部
一条腿有3个关节,8个自由度,其中7自由度为主动自由度:
- 髋关节:3个旋转自由度
- 膝关节:2个旋转自由度(可以屈伸,可以左右摆,想象跳皮筋)
- 踝关节:2个旋转自由度(可以屈伸,可以左右摆)
- 被动自由度:膝关节的线位移。它指的是股骨和胫骨是可以存在线性位移的,一般屈伸腿时会自然有极其微小幅度的位移,一般是忽略的。
但是机械腿的构型有3种:
- 仿人腿
- 仿鸟腿
- 合成腿
其中,人腿膝关节朝前的,鸟腿是“膝关节朝后”的。本质上是因为鸟类行走时其实是脚趾着地,人类是脚掌着地,下图的紫色为脚掌。
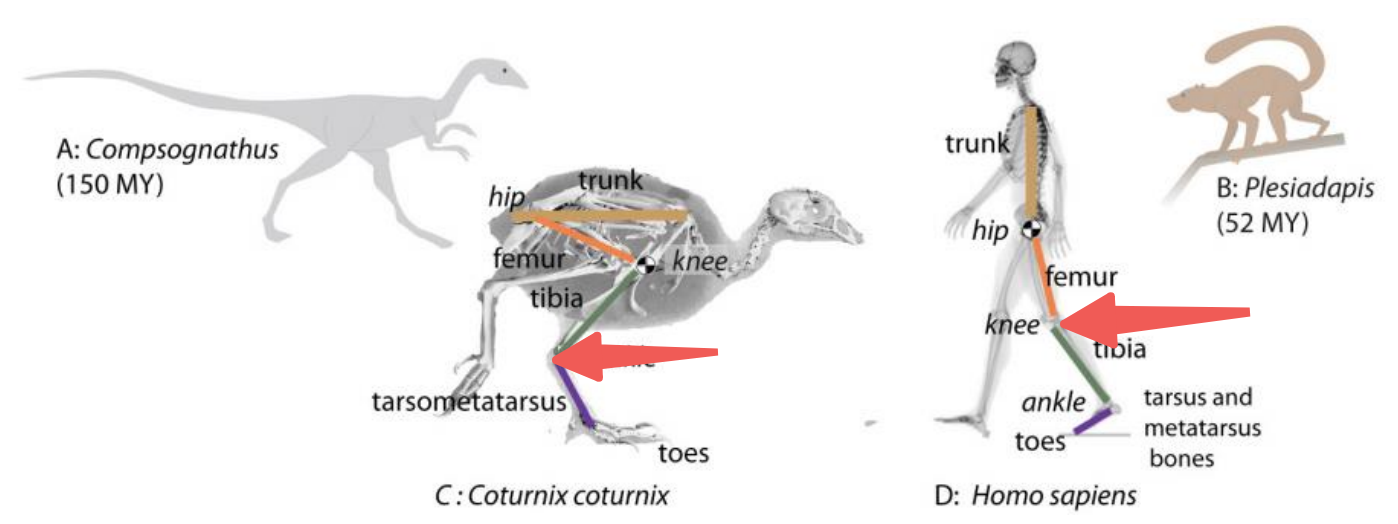
4…1仿人腿
一般仿人腿的机械腿是7自由度,去掉了膝关节的左右摆的自由度。
| 关节 | 人腿 | 仿人腿的机械腿 |
|---|---|---|
| 髋关节 | 3 | 3 |
| 膝关节 | 2 | 1 |
| 踝关节 | 2 | 2 |
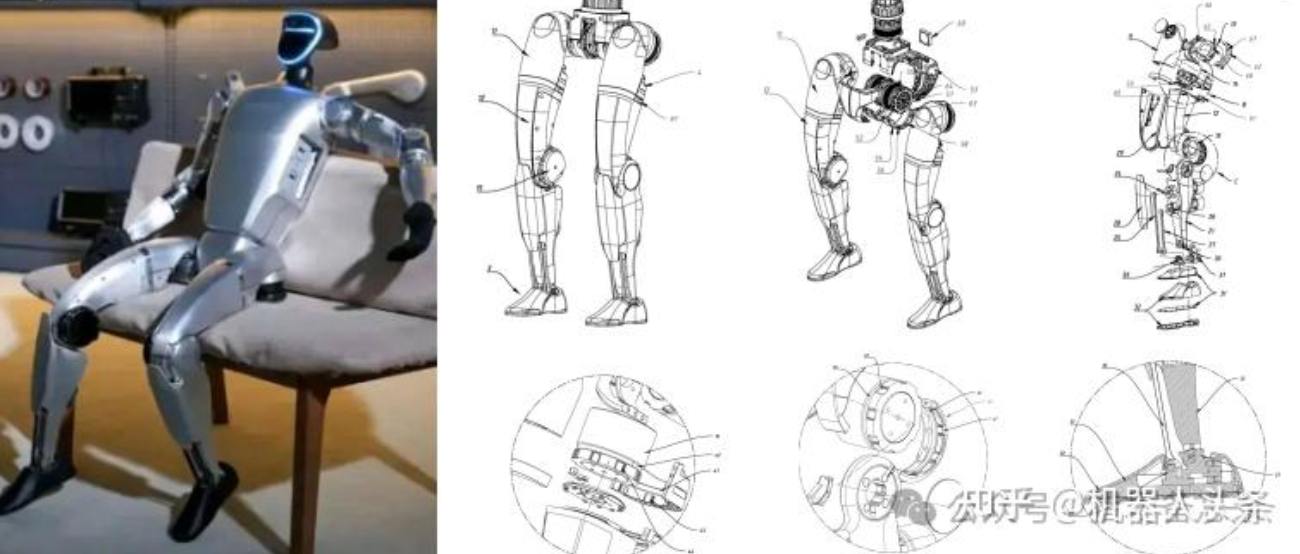
4.5.2 仿鸟腿
仿鸟腿的方案能耗更低,性能更强。想象一下人类冲刺时,是不是也是脚趾着地,而非脚掌着地?
仿鸟腿的形式一般为2自由度,髋关节一个,膝关节一个。

4.7 足式
足式机器人强调移动能力(Mobility)和适应性(Adaptivity),主攻非结构化路面(坑坑洼洼)/复杂/危险的环境。一般是通过强化学习进行步态生成。
当前属于新兴市场,各家炫技。比如Boston Dynamics,Agility Robotics。
当前重点:Sim2real。一般是通过强化学习在仿真环境中进行自主探索,但是迁移到现实中仍然存在阻碍,目前常见克服sim2real的方式是域随机化(domian randomization)等。
未来重点:全身协调控制(Whole body Control),协调控制腿,脚,躯干,手臂等,让机器人实现边走边做的复杂任务。
4.7.1 足式构型
足式构型主要分为如下3类:
- 刚性平面足:这是最简单最基础的构型,脚底是完全刚性的平坦的表面。优势是结构简单,成本低廉,劣势是地形适应力差,小石子都会导致失稳。
- 被动柔顺足:柔顺元件,指的是弹簧,橡胶垫等,能够被动吸收冲击,有点是适应能力更强,缺点是被动变形给控制造成不确定性。
- 脚趾足(Toed Foot):最接近人脚的构型。足部分为脚趾,足弓和脚跟。地形适应性最强,但是复杂性也是最高的。
4.8 轮式
由于目前足式机器人的运动稳定性仍然不足,学界/工业界多以炫技为主,如果想要实现应用,主力应仍是轮式底盘。
轮式底盘强调运行效率(Efficiency)和可靠性(Reliability),可以在结构化环境中开展大规模自动化任务。因此,轮式底盘是一个投资回报(ROI)更明确的方案。
当前属于较成熟的市场。比如Amazon Robotics。
当前重点:低成本导航。目前Lidar-SLAM技术已经成熟,并大规模部署,但是成本较高。因此纯视觉或视觉为主,且性能和Lidar方案持平甚至超越的方案是当前的重点。
未来重点:
- 社会性导航:与“传统导航”相对应,除了让机器人高效无碰撞地到达目的地,还要最大化周围人群的舒适感和信任感,符合社会礼仪。比如绕过人群时,调整朝向和速度。
- 群体协同:仓储空间中成百上千台轮式AGV/AMR的协同作业。
4.8.1 轮式构型
当前轮式构型分为如下:
- 差速轮+辅助万向轮。设计简单,转动依靠两轮速度差,自由度为2,纵向平移和原地旋转。多用于扫地机器人
- 阿克曼。前转向轮后驱动轮,自由度为2,纵向平移和圆弧旋转。用于汽车。
- 麦克纳姆轮。通过45度斜向布置滚轴,使得车轮旋转时摩擦力方向是斜向的,四个麦克纳姆轮能够做到3个自由度:纵向平移,横向平移,以及原地旋转。用于一些叉车等。
4.8.2 差速轮构型
轮式底盘的构型一般有如下4种。底盘分为圆形和矩形。其中圆形底盘占用空间更小,更加灵活,可以用于狭窄过道的场景,比如家庭。矩阵底盘一般用于仓储场景。
底盘下左右布置驱动轮(深灰色矩形),再前后辅以万向轮(深灰色小圆形)。
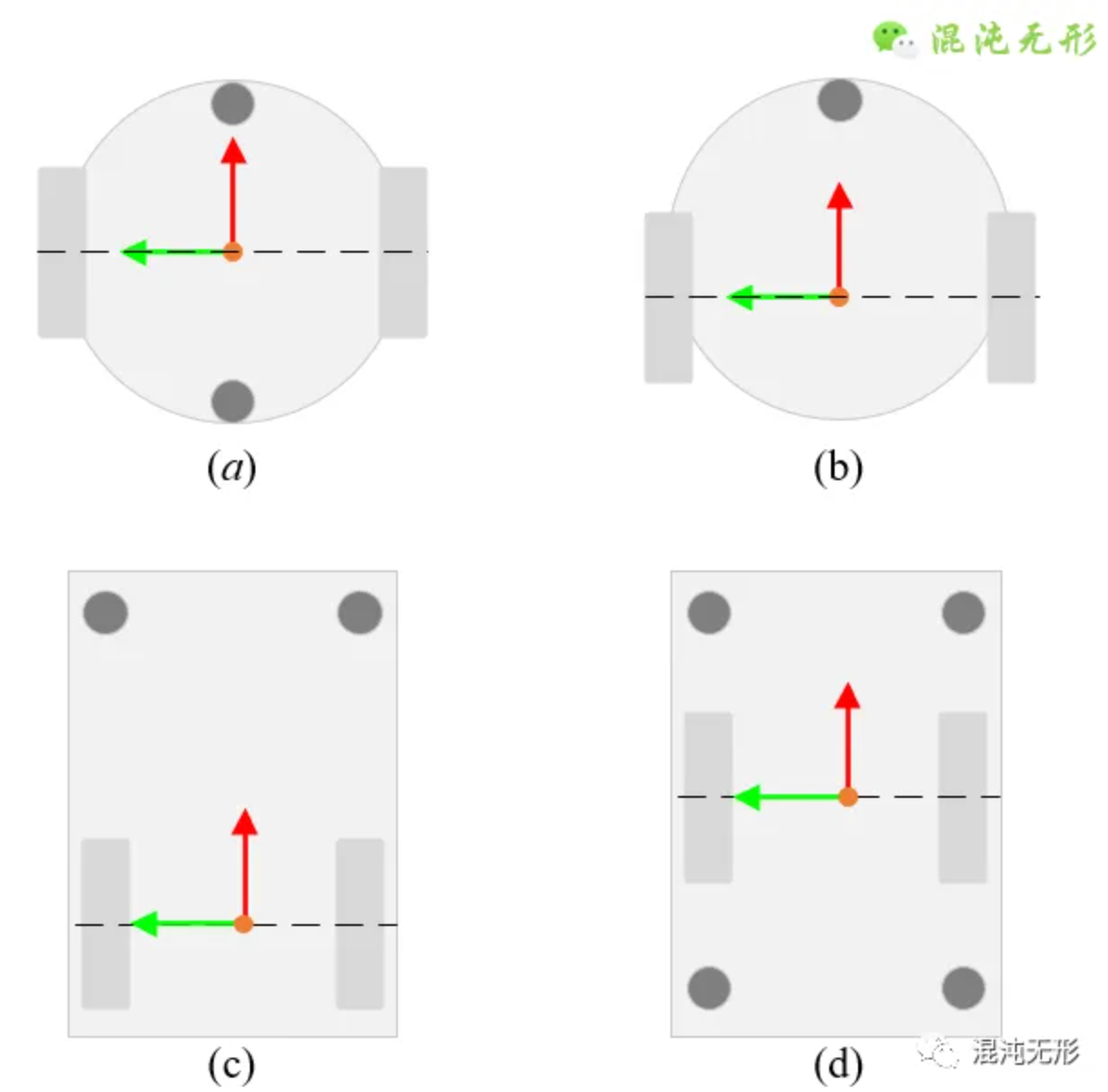
要注意的是,驱动轮并不具备转向功能,因此,轮式底盘需要转移方向的话,需要左右轮以不同的速度旋转。如下所示,即为转向时的旋转中心甲酸示意图。
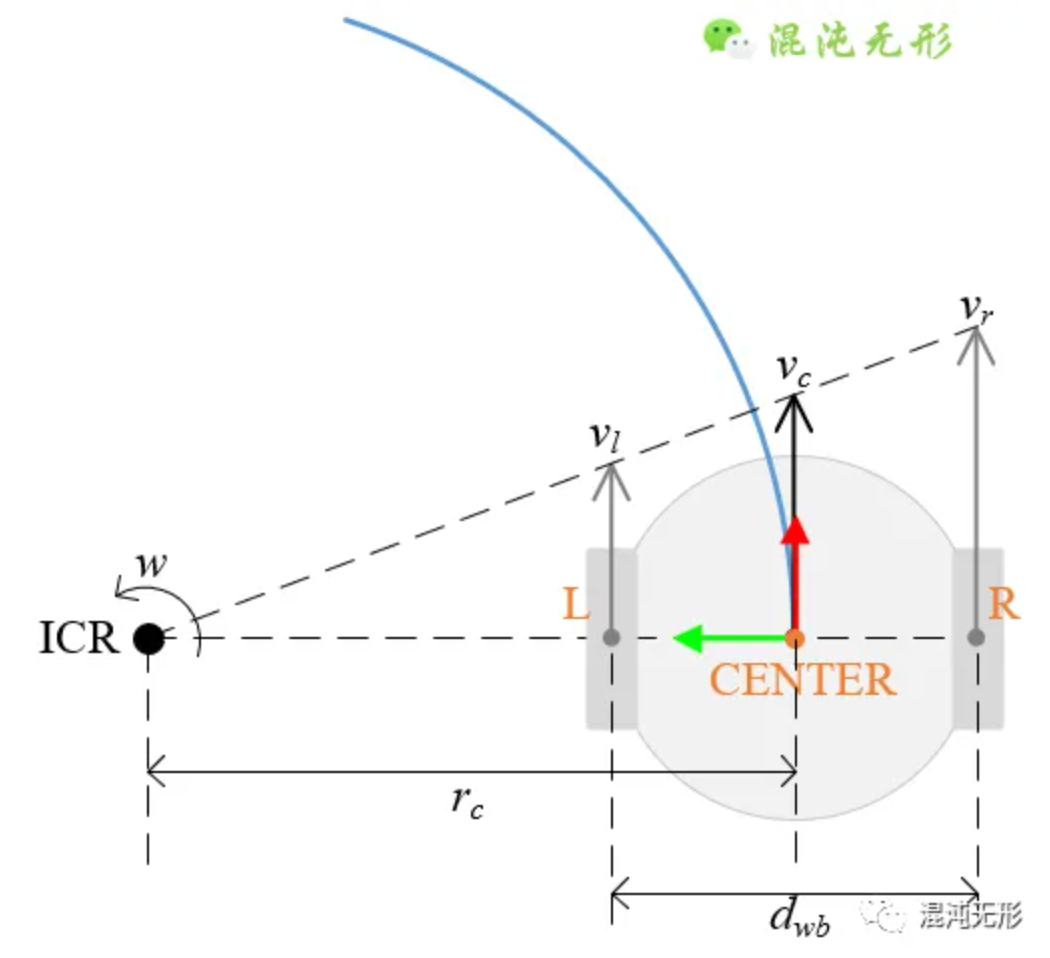
轮式底盘也有正运动学和逆运动学。
- 正运动学:给定左右轮的速度,计算机器人的线速度和角速度。它应用在里程计中对位移的计算;
- 逆运动学,给定机器人的线速度和角速度,计算左右轮的速度。它应用在上层规划和下层控制中。
5 应用
总体思想:工业制造先行,家庭场景渐进。
| 领域 | 总结 | 优势 | 劣势 | 价格 |
|---|---|---|---|---|
| 酒店配送机器人 | 未能完全商业化,劣势多于优势,可以助人,不能替人 | 配送,节省人力 | 功能单一(单向送货),其他酒店主要功能(换布草)做不到,改造多(WIFI全覆盖,电梯梯控改造,客房适配) | 2-3w |
to be continue
6 相关资料
6.1 论文类
操作类
【论文精读】Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
【论文精读】RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
【论文精读】GR00T N1: An open foundation model for generalist humanoid robots
移动类
【论文精读】BeamDojo: Learning Agile Humanoid Locomotion on Sparse Footholds
【论文阅读】AMP: Adversarial Motion Priors for Stylized Physics-Based Character Control

















 1557
1557

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









