






Kafka 生产者
1、生产者消息发送流程
1.1、发送原理
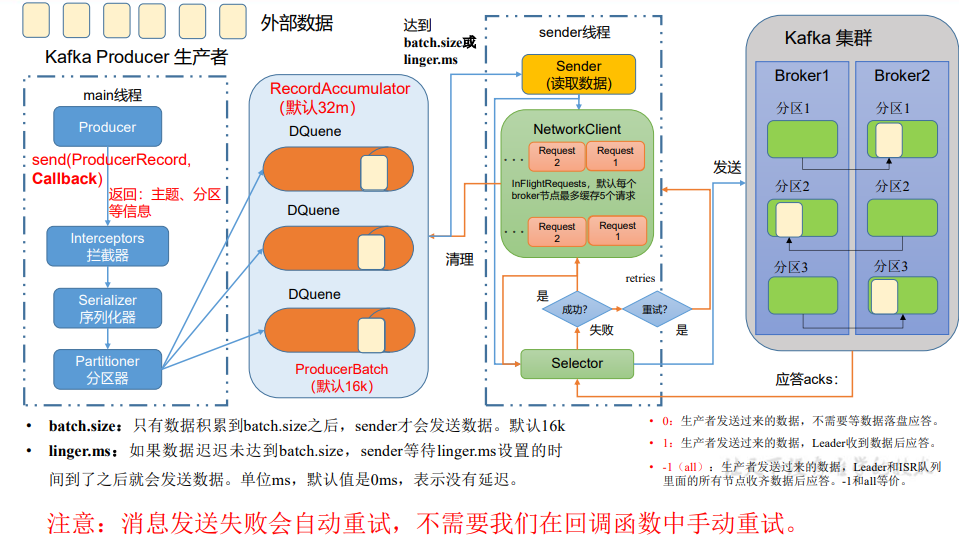
在消息发送的过程中,涉及到了两个线程——main 线程和 Sender 线程。在 main 线程 中创建了一个双端队列 RecordAccumulator。main 线程将消息发送给 RecordAccumulator, Sender 线程不断从 RecordAccumulator 中拉取消息发送到 Kafka Broker。
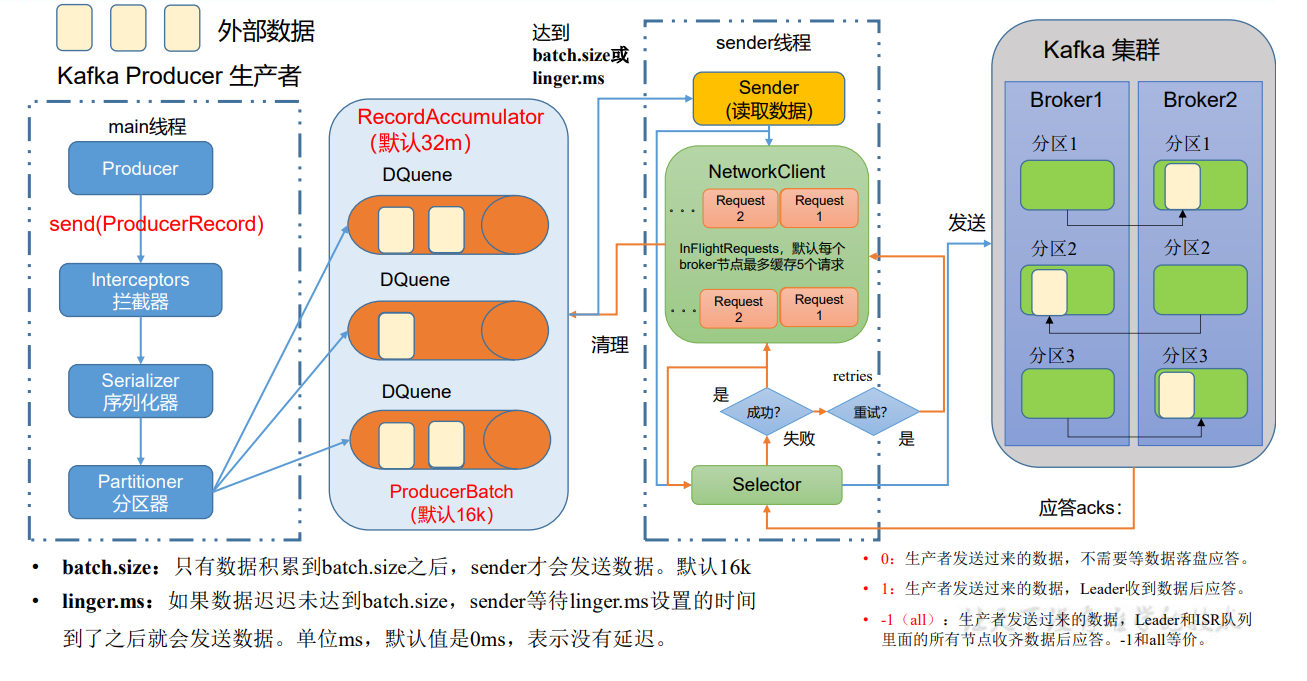
发送流程
1.2、生产者重要参数列表
| 参数名称 | 描述 |
| bootstrap.servers | 生产者连接集群所需的 broker 地 址 清 单 。 例 如 hadoop102:9092,hadoop103:9092,hadoop104:9092,可以 设置 1 个或者多个,中间用逗号隔开。注意这里并非需要所有的 broker 地址,因为生产者从给定的 broker 里查找到其他 broker 信息。 |
| key.serializer 和 value.serializer | 指定发送消息的 key 和 value 的序列化类型。一定要写 全类名。 |
| buffer.memory | RecordAccumulator 缓冲区总大小,默认 32m。 |
| batch.size | 缓冲区一批数据最大值,默认 16k。适当增加该值,可 以提高吞吐量,但是如果该值设置太大,会导致数据 传输延迟增加。 |
| linger.ms | 如果数据迟迟未达到 batch.size,sender 等待 linger.time 之后就会发送数据。单位 ms,默认值是 0ms,表示没 有延迟。生产环境建议该值大小为 5-100ms 之间。 |
| acks | 0:生产者发送过来的数据,不需要等数据落盘应答。 1:生产者发送过来的数据,Leader 收到数据后应答。 -1(all):生产者发送过来的数据,Leader+和 isr 队列 里面的所有节点收齐数据后应答。 默认值是-1,-1 和 all 是等价的。 |
| max.in.flight.requests.per.connection | 允许最多没有返回 ack 的次数,默认为 5,开启幂等性 要保证该值是 1-5 的数字。 |
| retries | 当消息发送出现错误的时候,系统会重发消息。retries 表示重试次数。默认是 int 最大值,2147483647。 如果设置了重试,还想保证消息的有序性,需要设置 MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION=1 否则在重试此失败消息的时候,其他的消息可能发送 成功了。 |
| retry.backoff.ms | 两次重试之间的时间间隔,默认是 100ms。 |
| enable.idempotence | 是否开启幂等性,默认 true,开启幂等性。 |
| compression.type | 生产者发送的所有数据的压缩方式。默认是 none,也 就是不压缩。 支持压缩类型:none、gzip、snappy、lz4 和 zstd。 |
1.3、异步发送 API
1)需求:创建 Kafka 生产者,采用异步的方式发送到 Kafka Broker
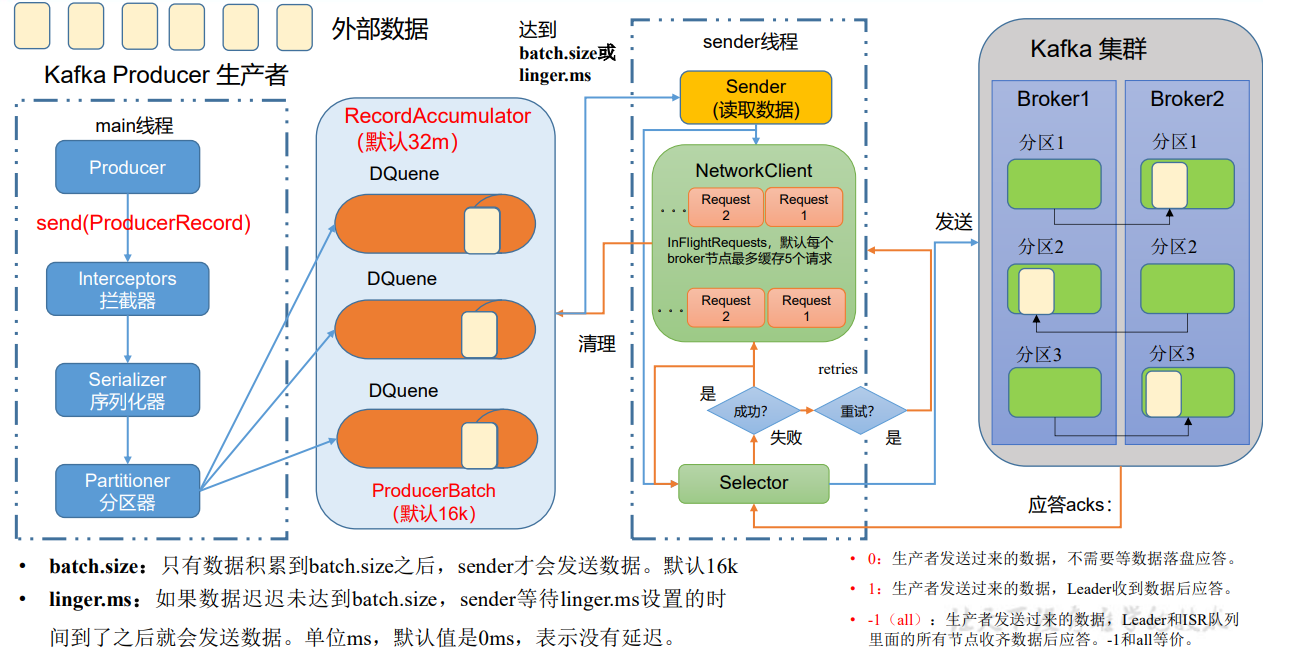
异步发送流程
2)代码编写
(1)创建工程 kafka
(2)导入依赖

kafka依赖
(3)创建包名
(4)编写不带回调函数的 API 代码
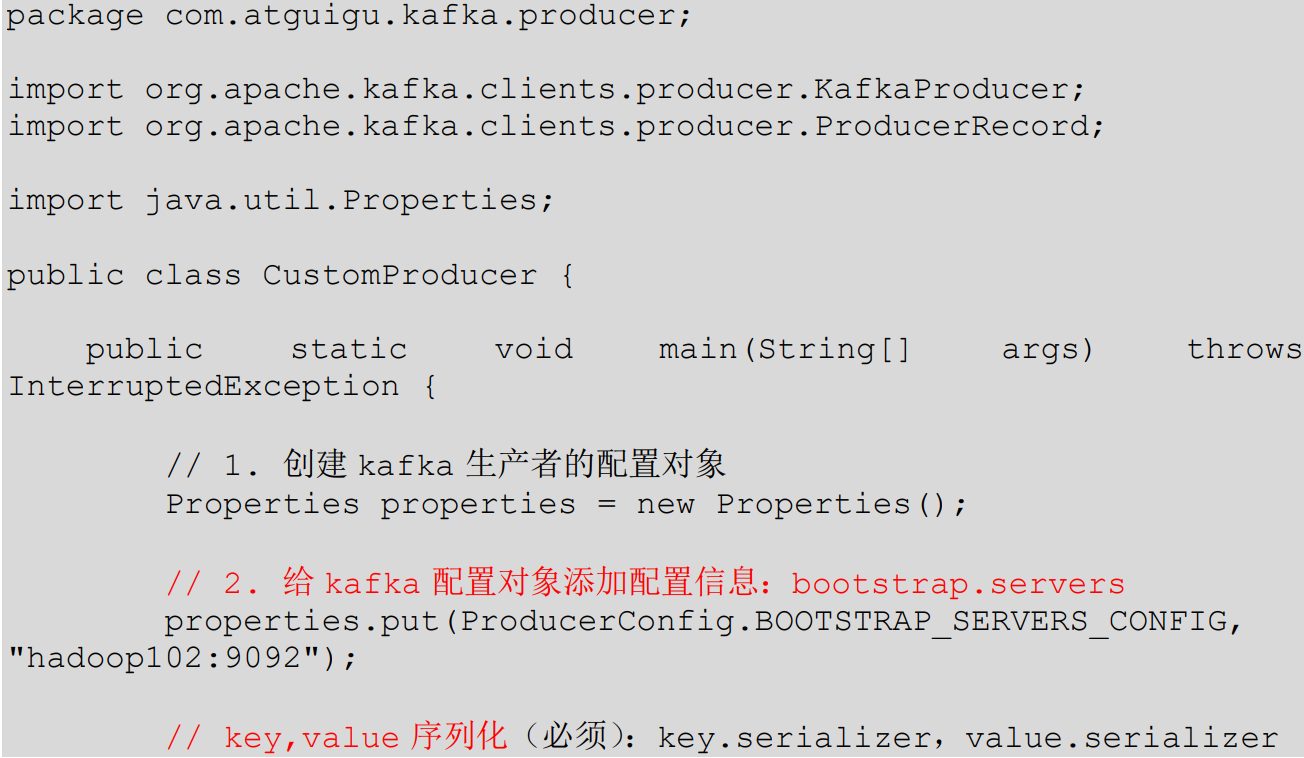
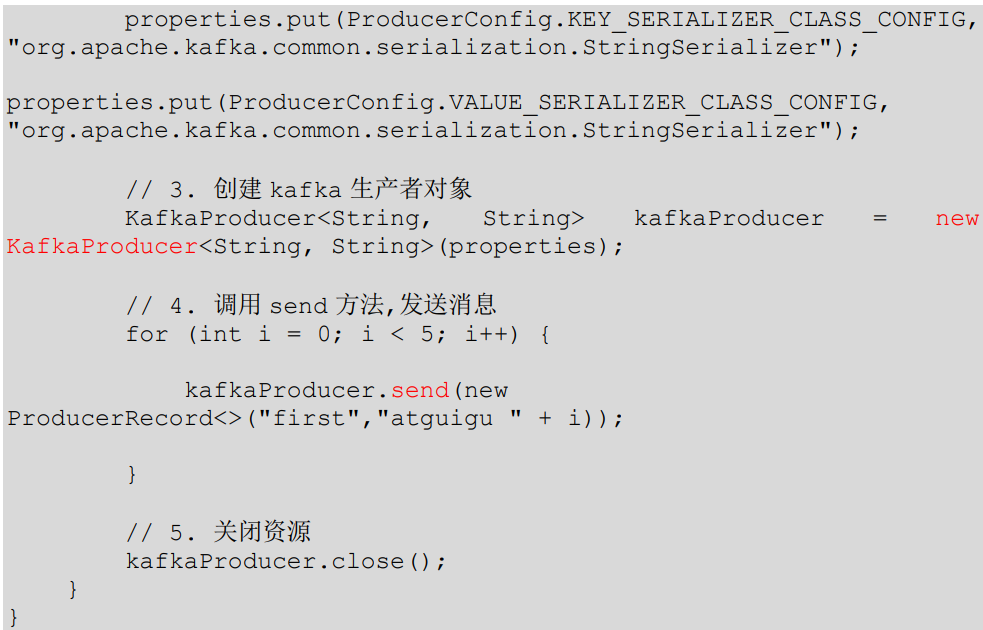
测试:
①在 hadoop102 上开启 Kafka 消费者。

②在 IDEA 中执行代码,观察 hadoop102 控制台中是否接收到消息。
带回调函数的异步发送
回调函数会在 producer 收到 ack 时调用,为异步调用,该方法有两个参数,分别是元 数据信息(RecordMetadata)和异常信息(Exception),如果 Exception 为 null,说明消息发 送成功,如果 Exception 不为 null,说明消息发送失败。


测试:
①在 hadoop102 上开启 Kafka 消费者。

②在 IDEA 中执行代码,观察 hadoop102 控制台中是否接收到消息。
③在 IDEA 控制台观察回调信息

1.4、同步发送 API
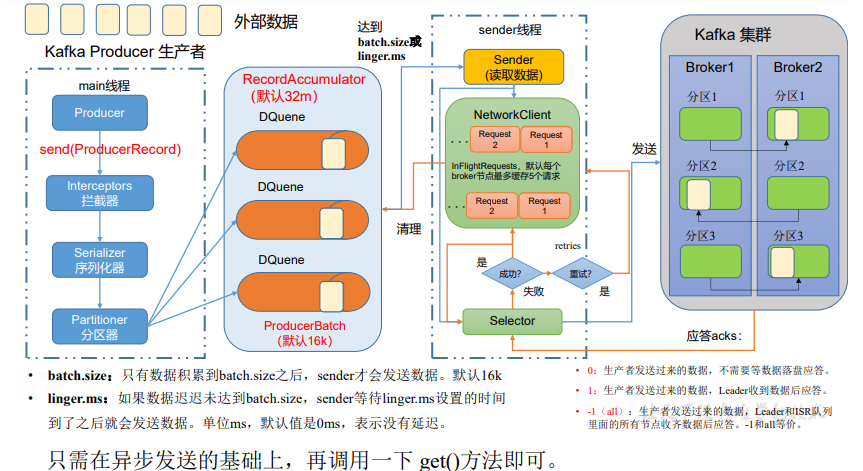
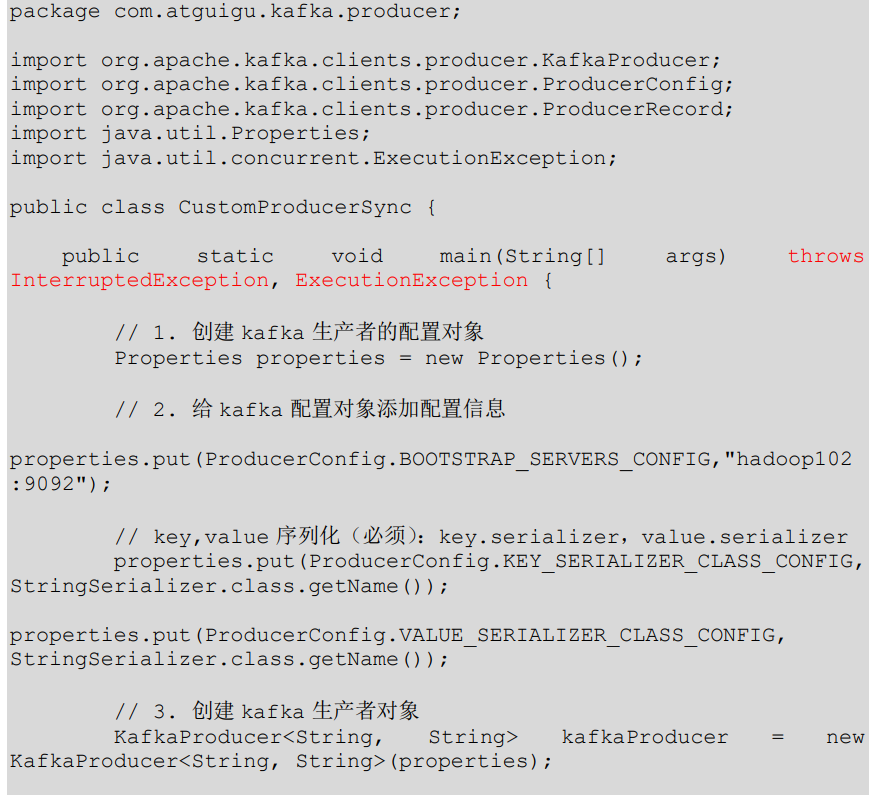

测试:
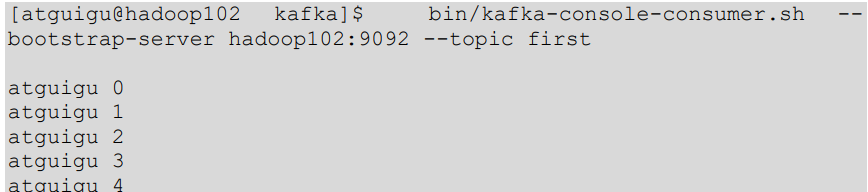
①在 hadoop102 上开启 Kafka 消费者。

②在 IDEA 中执行代码,观察 hadoop102 控制台中是否接收到消息。
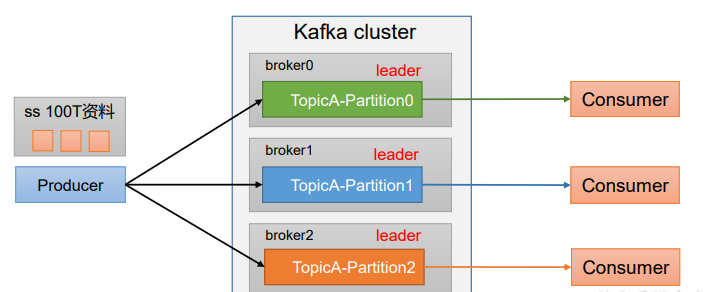
1.5、生产者分区
分区好处 :
(1)便于合理使用存储资源,每个Partition在一个Broker上存储,可以把海量的数据按照分区切割成一 块一块数据存储在多台Broker上。合理控制分区的任务,可以实现负载均衡的效果。
(2)提高并行度,生产者可以以分区为单位发送数据;消费者可以以分区为单位进行消费数据。
生产者发送消息的分区策略
1)默认的分区器 DefaultPartitioner
在 IDEA 中 ctrl +n,全局查找 DefaultPartitioner。


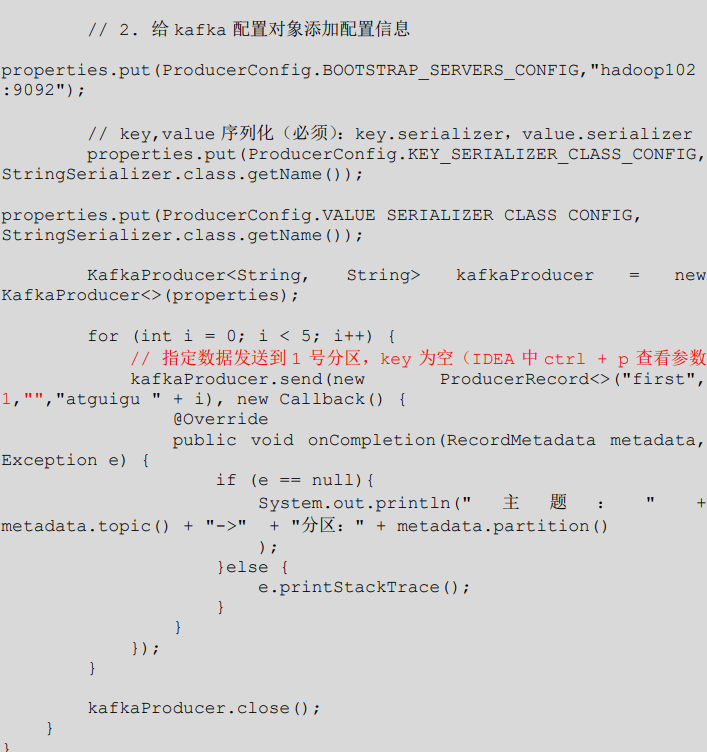
2)案例一
将数据发往指定 partition 的情况下,例如,将所有数据发往分区 1 中。

测试:
①在 hadoop102 上开启 Kafka 消费者。

②在 IDEA 中执行代码,观察 hadoop102 控制台中是否接收到消息。
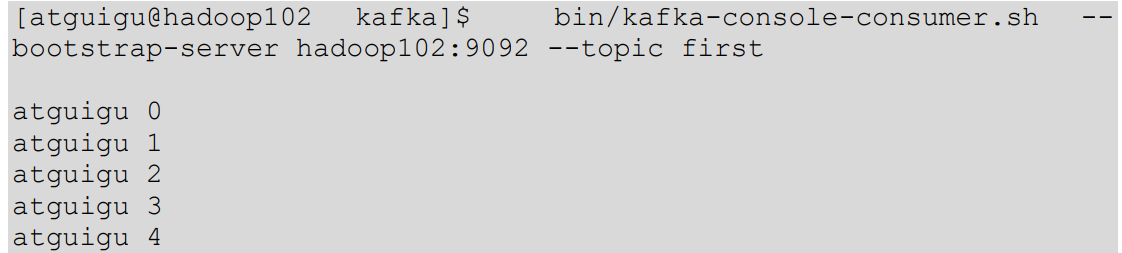
③在 IDEA 控制台观察回调信息。

3)案例二
没有指明 partition 值但有 key 的情况下,将 key 的 hash 值与 topic 的 partition 数进行取 余得到 partition 值。

测试:
①key="a"时,在控制台查看结果。

②key="b"时,在控制台查看结果。

③key="f"时,在控制台查看结果。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









