




一、Flink CDC 介绍
从广义的概念上讲,能够捕获数据变更的技术, 我们都可以称为 CDC 技术。通常我们说的 CDC 技术是一种用于捕获数据库中数据变更的技术。CDC 技术应用场景也非常广泛,包括:
- 数据分发,将一个数据源分发给多个下游,常用于业务解耦、微服务。
- 数据集成,将分散异构的数据源集成到数据仓库中,消除数据孤岛,便于后续的分析。
- 数据迁移,常用于数据库备份、容灾等。
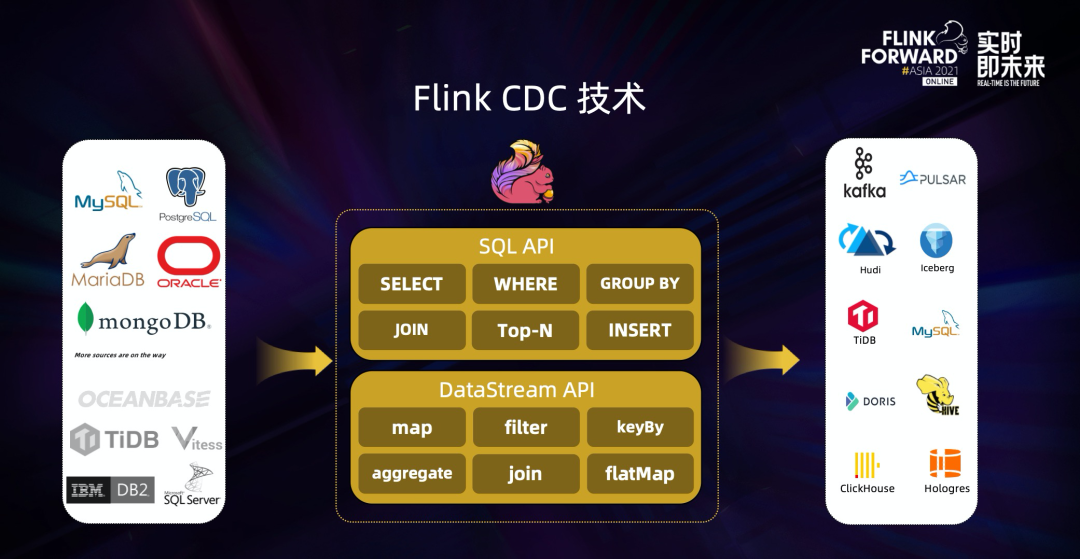
Flink CDC 基于数据库日志的 Change Data Caputre 技术,实现了全量和增量的一体化读取能力,并借助 Flink 优秀的管道能力和丰富的上下游生态,支持捕获多种数据库的变更,并将这些变更实时同步到下游存储。
目前,Flink CDC 的上游已经支持了 MySQL、MariaDB、PG、Oracle、MongoDB 等丰富的数据源,对 Oceanbase、TiDB、SQLServer 等数据库的支持也已经在社区的规划中。
Flink CDC 的下游则更加丰富,支持写入 Kafka、Pulsar 消息队列,也支持写入 Hudi、Iceberg 等数据湖,还支持写入Apache Doris等各种数据仓库。
同时,通过 Flink SQL 原生支持的 Changelog 机制,可以让 CDC 数据的加工变得非常简单。用户可以通过 SQL 便能实现数据库全量和增量数据的清洗、打宽、聚合等操作,极大地降低了用户门槛。 此外, Flink DataStream API 支持用户编写代码实现自定义逻辑,给用户提供了深度定制业务的自由度。
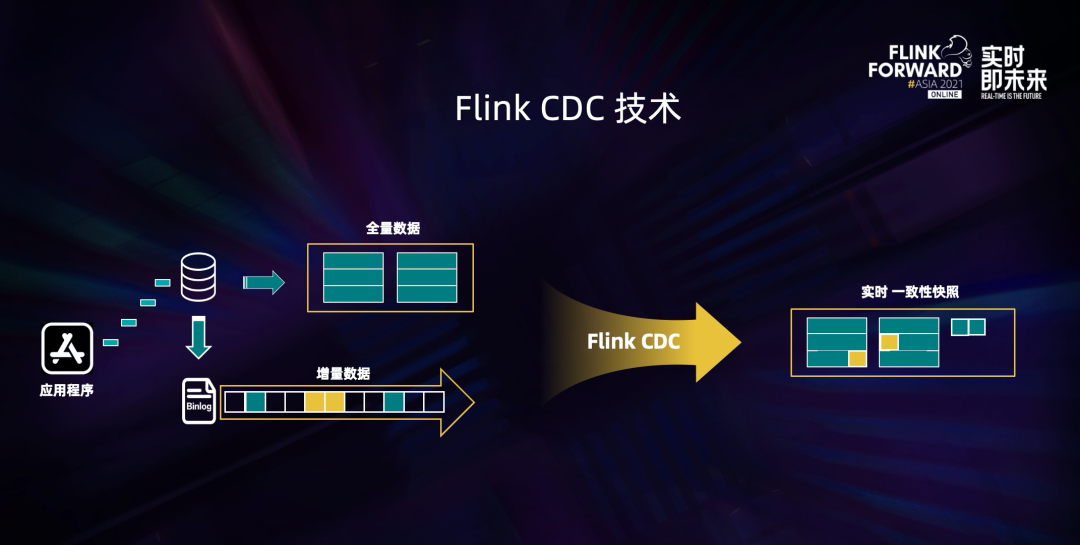
Flink CDC 技术的核心是支持将表中的全量数据和增量数据做实时一致性的同步与加工,让用户可以方便地获每张表的实时一致性快照。比如一张表中有历史的全量业务数据,也有增量的业务数据在源源不断写入,更新。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









