




一、SQL 命令体系与执行原理
1.1 SQL 命令分类架构

1.2 SQL 执行流程详解
MySQL 执行 SQL 的内部流程可分为解析→优化→执行三个阶段,具体步骤如下:

1.3 SQL 执行顺序(重点)
SELECT 语句的子句执行顺序与书写顺序不同,这是理解复杂查询的关键:

示例说明:
-- 书写顺序
SELECT department, AVG(salary) AS avg_salary
FROM employees
WHERE hire_year >= 2020
GROUP BY department
HAVING avg_salary > 50000
ORDER BY avg_salary DESC
LIMIT 10;
-- 执行顺序:
1. FROM employees -- 先确定数据源
2. WHERE hire_year >= 2020 -- 过滤2020年后入职的员工
3. GROUP BY department -- 按部门分组
4. HAVING avg_salary > 50000 -- 保留平均工资超5万的部门
5. SELECT department, AVG(...) -- 计算并选择最终列
6. ORDER BY avg_salary DESC -- 按平均工资降序
7. LIMIT 10 -- 取前10条结果
二、数据定义语言(DDL)图解
2.1 表结构管理核心命令
DDL 用于创建和修改数据库对象,核心是表结构的设计与调整。
2.1.1 CREATE TABLE(创建表)
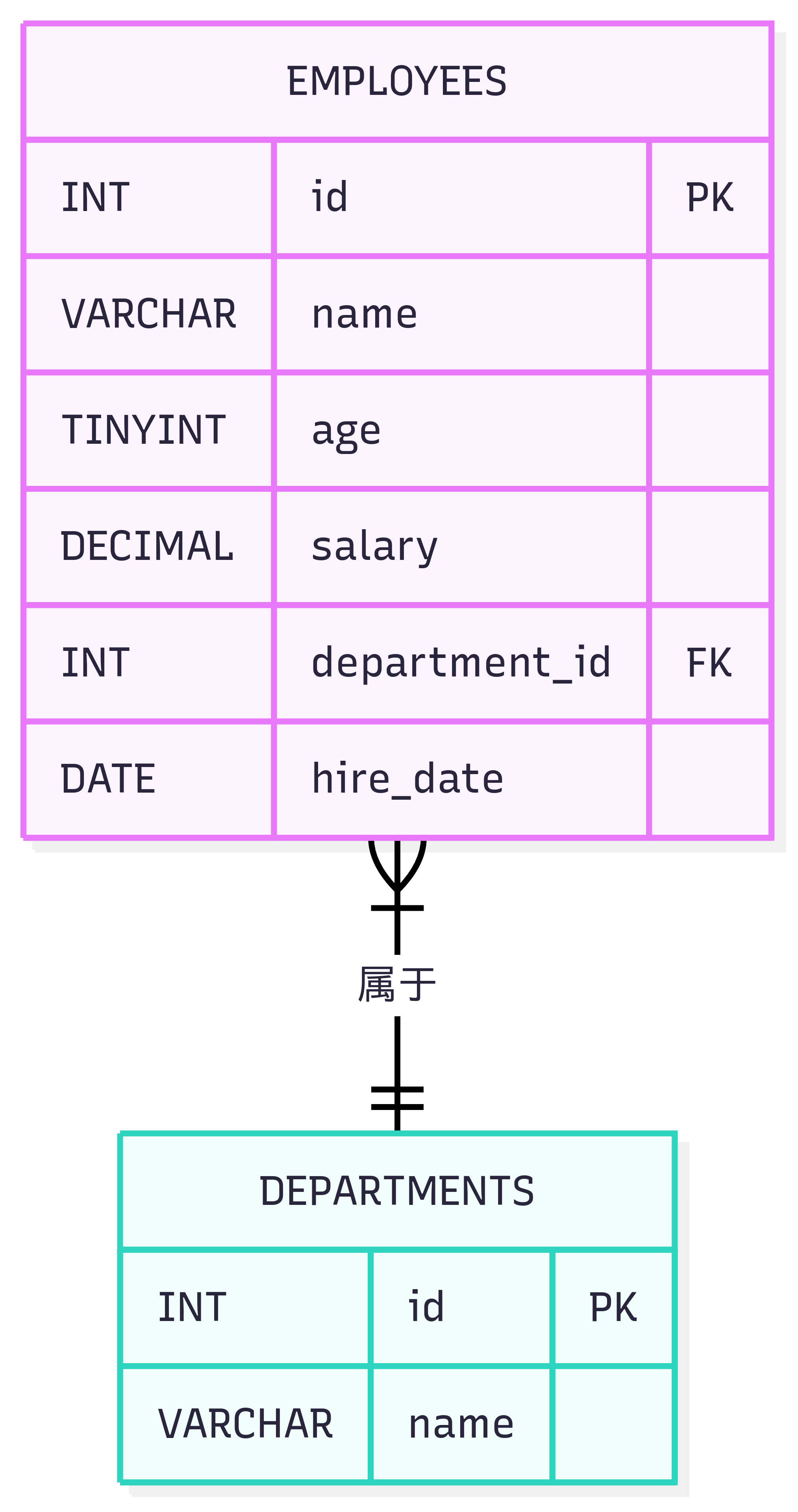
CREATE TABLE employees (
id INT PRIMARY KEY AUTO_INCREMENT COMMENT '员工ID',
name VARCHAR(50) NOT NULL COMMENT '姓名',
age TINYINT UNSIGNED CHECK (age >= 18) COMMENT '年龄',
salary DECIMAL(10,2) NOT NULL DEFAULT 0 COMMENT '工资',
department_id INT COMMENT '部门ID',
hire_date DATE NOT NULL COMMENT '入职日期',
-- 外键约束
FOREIGN KEY (department_id) REFERENCES departments(id)
ON DELETE SET NULL -- 部门删除时,员工的部门ID设为NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT '员工表';
表结构可视化:
2.1.2 ALTER TABLE(修改表)
表结构变更的常见操作及影响:
-- 1. 添加字段
ALTER TABLE employees
ADD COLUMN email VARCHAR(100) UNIQUE AFTER name;
-- 2. 修改字段类型
ALTER TABLE employees
MODIFY COLUMN salary DECIMAL(12,2); -- 扩大工资字段长度
-- 3. 删除字段
ALTER TABLE employees
DROP COLUMN age;
-- 4. 添加索引
ALTER TABLE employees
ADD INDEX idx_department_hire (department_id, hire_date);
修改流程示意图:

注意:大表 ALTER 操作可能导致长时间锁表,生产环境建议使用pt-online-schema-change等工具实现无锁变更。
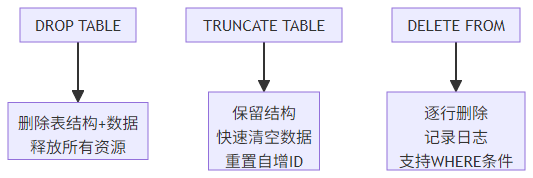
2.1.3 DROP 与 TRUNCATE(删除操作)
|
命令 |
作用 |
特点 |
适用场景 |
|
DROP TABLE |
删除表结构及数据 |
不可恢复,释放所有空间 |
彻底移除无用表 |
|
TRUNCATE TABLE |
清空表数据(保留结构) |
速度快,不写日志,自增 ID 重置 |
保留表结构但需清空数据 |
|
DELETE FROM |
逐行删除数据 |
可回滚,写日志,自增 ID 不重置 |
需要条件删除或事务控制 |
执行差异:
2.2 索引管理图解
索引是提升查询性能的核心,需理解不同类型的适用场景。
2.2.1 索引类型及创建
-- 1. 主键索引(唯一且非空)
ALTER TABLE employees ADD PRIMARY KEY (id);
-- 2. 唯一索引(允许NULL但值唯一)
ALTER TABLE employees ADD UNIQUE INDEX idx_email (email);
-- 3. 普通索引(最常用)
ALTER TABLE employees ADD INDEX idx_department (department_id);
-- 4. 复合索引(多字段组合)
ALTER TABLE employees ADD INDEX idx_dept_hire_salary (department_id, hire_date, salary);
复合索引顺序原则:

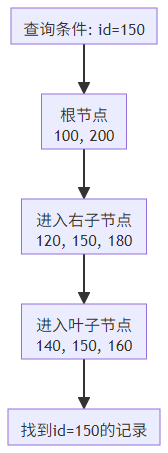
2.2.2 B-Tree 索引结构(MySQL 默认)
B-Tree 索引通过分层结构实现快速查找,适合范围查询:
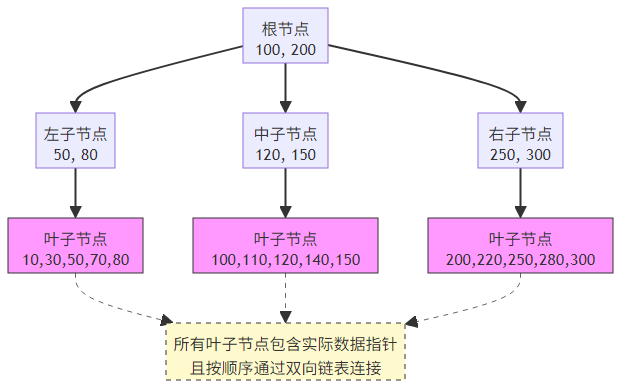
三、数据查询语言(DQL)图解
3.1 SELECT 基础语法
SELECT
[DISTINCT] -- 去重
列名1 [AS 别名1],
列名2 [AS 别名2],
聚合函数(列名) -- 如COUNT/SUM/AVG
FROM
表名1 [AS 别名1]
[JOIN 表名2 ON 连接条件] -- 关联查询
[WHERE 行过滤条件]
[GROUP BY 分组列]
[HAVING 组过滤条件]
[ORDER BY 排序列 [ASC|DESC]]
[LIMIT 偏移量, 行数];
示例解析:
SELECT
d.name AS dept_name,
COUNT(e.id) AS emp_count,
AVG(e.salary) AS avg_salary
FROM
departments d
LEFT JOIN
employees e ON d.id = e.department_id
WHERE
d.establish_year >= 2010
GROUP BY
d.id, d.name -- GROUP BY需包含SELECT中非聚合列
HAVING
emp_count >= 10
ORDER BY
avg_salary DESC
LIMIT 5;
3.2 JOIN 关联查询详解
关联查询是多表数据整合的核心,不同 JOIN 类型的差异如下:
3.2.1 INNER JOIN(内连接)
只返回两表中匹配条件的记录:
SELECT
e.name, d.name AS department
FROM
employees e
INNER JOIN
departments d ON e.department_id = d.id;
匹配逻辑:

3.2.2 LEFT/RIGHT JOIN(外连接)
- LEFT JOIN:保留左表所有记录,右表无匹配则为 NULL
- RIGHT JOIN:保留右表所有记录,左表无匹配则为 NULL
-- 左连接示例:所有员工及其部门(包括无部门的员工)
SELECT
e.name, d.name AS department
FROM
employees e
LEFT JOIN
departments d ON e.department_id = d.id;
匹配逻辑:

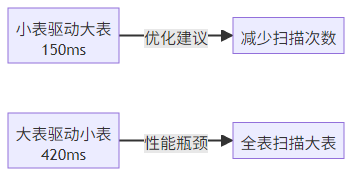
3.2.3 多表 JOIN 顺序优化
JOIN 顺序对性能影响较大,遵循小表驱动大表原则:
-- 高效:小表(departments)作为驱动表
SELECT ...
FROM departments d
JOIN employees e ON d.id = e.department_id
JOIN salaries s ON e.id = s.employee_id;
执行效率对比:
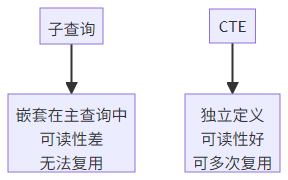
3.3 子查询与 CTE(公用表表达式)
3.3.1 子查询类型
-- 1. 标量子查询(返回单个值)
SELECT name, salary
FROM employees
WHERE salary > (SELECT AVG(salary) FROM employees);
-- 2. 列子查询(返回单列多行)
SELECT name
FROM employees
WHERE department_id IN (SELECT id FROM departments WHERE location = 'Beijing');
-- 3. 行子查询(返回一行多列)
SELECT *
FROM employees
WHERE (department_id, salary) = (SELECT id, MAX(salary) FROM employees GROUP BY id);
-- 4. 表子查询(返回多行多列)
SELECT e.name, d.dept_name
FROM (SELECT * FROM employees WHERE hire_year = 2023) e
JOIN departments d ON e.department_id = d.id;
3.3.2 CTE(Common Table Expression)
CTE 是 MySQL 8.0 引入的特性,使复杂子查询更易读:
WITH high_earners AS (
-- 定义CTE:薪资前20%的员工
SELECT *
FROM employees
WHERE salary > (SELECT PERCENTILE_CONT(0.8) WITHIN GROUP (ORDER BY salary) FROM employees)
)
-- 使用CTE
SELECT
department_id, COUNT(*) AS high_earner_count
FROM high_earners
GROUP BY department_id;
CTE 与子查询对比:
四、数据操作语言(DML)图解
4.1 INSERT(插入数据)
4.1.1 基础插入
-- 1. 全字段插入(需按表结构顺序)
INSERT INTO employees
VALUES (NULL, '张三', 30, 8000, 1, '2023-01-15');
-- 2. 指定字段插入(推荐,字段顺序可自定义)
INSERT INTO employees (name, salary, department_id, hire_date)
VALUES ('李四', 9000, 2, '2023-02-20');
4.1.2 批量插入
INSERT INTO employees (name, salary, hire_date)
VALUES
('王五', 7500, '2023-03-01'),
('赵六', 8200, '2023-03-05'),
('钱七', 9500, '2023-03-10');
性能优势:批量插入比单条插入快 5-10 倍(减少网络交互和事务开销)。
4.2 UPDATE(更新数据)
-- 1. 简单更新
UPDATE employees
SET salary = salary * 1.1 -- 全体涨薪10%
WHERE department_id = 3; -- 仅3号部门
-- 2. 多表关联更新
UPDATE employees e
JOIN departments d ON e.department_id = d.id
SET e.salary = e.salary * 1.05
WHERE d.location = 'Shanghai'; -- 上海的部门涨薪5%
更新机制:

注意:UPDATE 语句若无 WHERE 条件,会更新全表并加表锁,生产环境务必谨慎!
4.3 DELETE(删除数据)
-- 1. 条件删除
DELETE FROM employees
WHERE hire_date < '2010-01-01' AND performance_rating < 3;
-- 2. 多表关联删除
DELETE e
FROM employees e
JOIN departments d ON e.department_id = d.id
WHERE d.name = '临时项目组'; -- 删除临时项目组的所有员工
批量删除优化:大表删除避免一次性删除过多数据,建议分批删除:
-- 分批删除(每次1000行,避免长事务和锁表)
WHILE (SELECT COUNT(*) FROM logs WHERE create_time < '2023-01-01') > 0 DO
DELETE FROM logs WHERE create_time < '2023-01-01' LIMIT 1000;
COMMIT; -- 每批提交一次
SLEEP(1); -- 避免IO峰值
END WHILE;
五、索引与查询优化图解
5.1 索引类型及适用场景
|
索引类型 |
结构 |
适用场景 |
不适用场景 |
|
B-Tree 索引 |
平衡树 |
等值查询、范围查询、排序 |
模糊查询前缀不确定(如%abc) |
|
哈希索引 |
哈希表 |
等值查询(=、IN) |
范围查询(>、<)、排序 |
|
全文索引 |
倒排索引 |
文本搜索(MATCH AGAINST) |
短文本、精确匹配 |
|
空间索引 |
R 树 |
地理空间数据 |
非空间数据 |
B-Tree 索引查询流程:
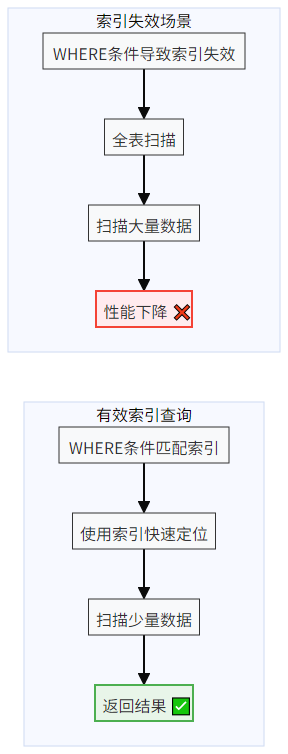
5.2 索引失效场景分析
5.2.1 索引失效的常见情况
-- 1. 函数操作索引列
SELECT * FROM employees WHERE YEAR(hire_date) = 2020; -- 索引失效
-- 优化:改为索引列直接比较
SELECT * FROM employees WHERE hire_date >= '2020-01-01' AND hire_date < '2021-01-01';
-- 2. 隐式类型转换
SELECT * FROM users WHERE phone = 13800138000; -- phone是VARCHAR,索引失效
-- 优化:保持类型一致
SELECT * FROM users WHERE phone = '13800138000';
-- 3. 否定条件
SELECT * FROM products WHERE price NOT IN (100, 200); -- 可能失效
-- 4. 模糊查询前缀不确定
SELECT * FROM articles WHERE title LIKE '%mysql'; -- 索引失效
索引失效示意图:
5.2.2 复合索引最左前缀原则
复合索引(a, b, c)的有效使用场景:
-- 有效:匹配最左前缀a
SELECT * FROM table WHERE a = 1;
-- 有效:匹配a+b
SELECT * FROM table WHERE a = 1 AND b = 2;
-- 有效:匹配a+b+c
SELECT * FROM table WHERE a = 1 AND b = 2 AND c = 3;
-- 无效:跳过a直接查b
SELECT * FROM table WHERE b = 2;
-- 部分有效:只使用a列索引
SELECT * FROM table WHERE a = 1 AND c = 3;
索引匹配示意图:

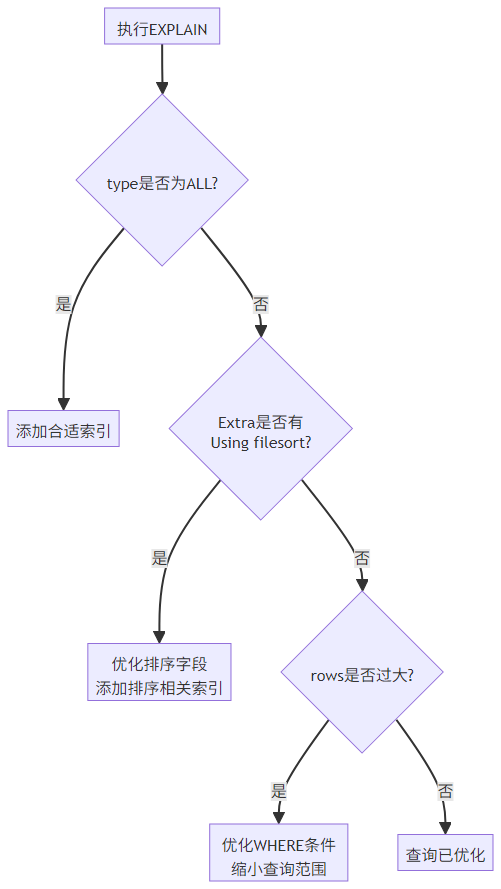
5.3 EXPLAIN 执行计划分析
EXPLAIN 是优化查询的核心工具,通过分析执行计划判断是否使用索引:
EXPLAIN
SELECT * FROM orders
WHERE user_id = 100 AND create_time > '2023-01-01'
ORDER BY total_amount DESC;
关键字段解析:
|
字段 |
含义 |
优化目标 |
|
type |
连接类型 |
至少达到range,最好是ref/eq_ref |
|
key |
实际使用的索引 |
非NULL,且与possible_keys一致 |
|
rows |
估算扫描行数 |
越小越好 |
|
Extra |
额外信息 |
避免Using filesort(文件排序)、Using temporary(临时表) |
执行计划优化流程:
六、事务与锁机制图解
6.1 事务 ACID 特性
事务是保证数据一致性的核心,具备四大特性:
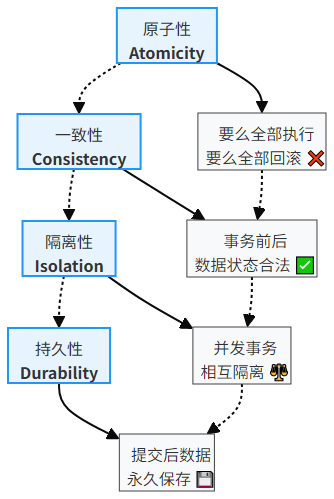
6.2 事务隔离级别
MySQL 默认隔离级别为REPEATABLE READ,不同级别解决的问题不同:
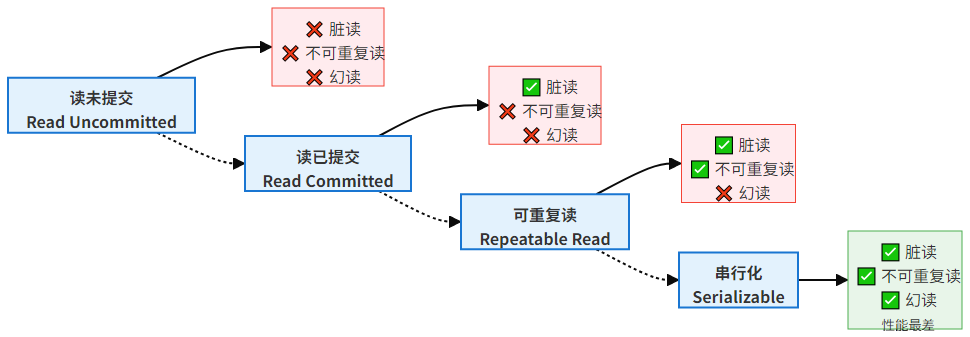
隔离级别设置:
-- 查看当前隔离级别
SELECT @@transaction_isolation;
-- 设置隔离级别
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
6.3 锁机制详解
MySQL 的锁按粒度分为行锁和表锁,InnoDB 主要使用行锁提升并发:
6.3.1 行锁类型
- 共享锁 (S 锁):读锁,多个事务可同时获取,阻塞写操作
- 排他锁 (X 锁):写锁,仅允许一个事务获取,阻塞读写操作
-- 获取共享锁
SELECT * FROM products WHERE id = 1 FOR SHARE;
-- 获取排他锁
SELECT * FROM products WHERE id = 1 FOR UPDATE;
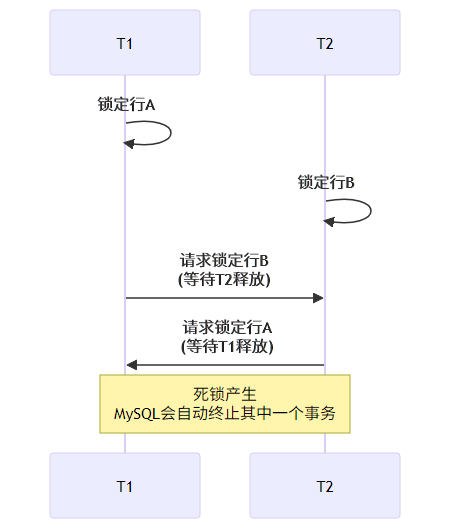
6.3.2 死锁产生与避免
死锁是并发事务相互等待资源导致的僵局:
避免死锁的方法:
- 统一事务内的加锁顺序(如按 ID 升序)
- 减少事务持有锁的时间(小事务)
- 避免长事务
七、SQL 性能优化最佳实践
7.1 查询优化 Checklist
a.索引优化:
-
- 为 WHERE、JOIN、ORDER BY 列创建索引
-
- 避免过度索引(影响写性能)
-
- 定期重建碎片化索引(OPTIMIZE TABLE)
b.查询语句优化:
-
- 避免SELECT *,只查询需要的列
-
- 用 JOIN 替代子查询(尤其是 NOT IN)
-
- 大表分页用WHERE id > 上一页最大ID替代LIMIT 大偏移量
c.数据量控制:
-
- 分区表存储大表(按时间 / 范围分区)
-
- 定期归档历史数据
-
- 冷热数据分离存储
7.2 性能监控与调优流程
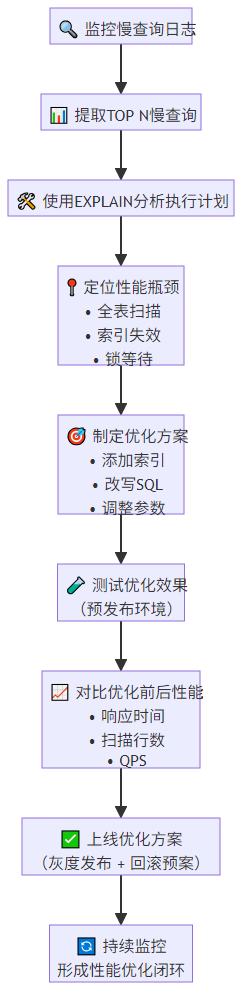
7.3 常见 SQL 陷阱与解决方案
|
陷阱 |
解决方案 |
|
SELECT COUNT(*) FROM table效率低 |
InnoDB 用EXPLAIN估算,或维护计数器表 |
|
大表ALTER TABLE锁表 |
使用pt-online-schema-change无锁变更 |
|
OR条件导致索引失效 |
改为UNION查询 |
|
LIKE '%value'无法使用索引 |
改用全文索引或应用层处理 |
八、总结
MySQL SQL 命令是数据库运维的核心技能,掌握以下关键点可显著提升效率:
- 理解 SQL 执行顺序与 JOIN 类型差异,写出正确的关联查询
- 合理设计索引,遵循最左前缀原则,通过 EXPLAIN 优化查询
- 掌握事务隔离级别与锁机制,避免并发问题
- 大表操作需分批处理,避免影响生产环境
- 定期分析慢查询日志,持续优化 SQL 性能
通过系统化学习和实践,可逐步形成 “写 SQL→分析执行计划→优化索引→验证性能” 的闭环思维,应对各类复杂业务场景。

















 809
809

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









