




📌 友情提示:
本文内容由银河易创AI(https://ai.eaigx.com)创作平台的gpt-4-turbo模型生成,旨在提供技术参考与灵感启发。文中观点或代码示例需结合实际情况验证,建议读者通过官方文档或实践进一步确认其准确性。
随着人工智能技术的不断发展,智能代理(AI Agent)作为一个重要的技术概念,已经逐渐进入了我们的视野。从自动化客服到自主决策的机器人,AI Agent正变得越来越智能,并且广泛应用于各种领域,如互联网服务、金融分析、自动驾驶等。本文将深入探讨AI Agent的定义、工作原理、技术实现及其广泛应用场景,帮助大家更好地理解这一前沿技术。
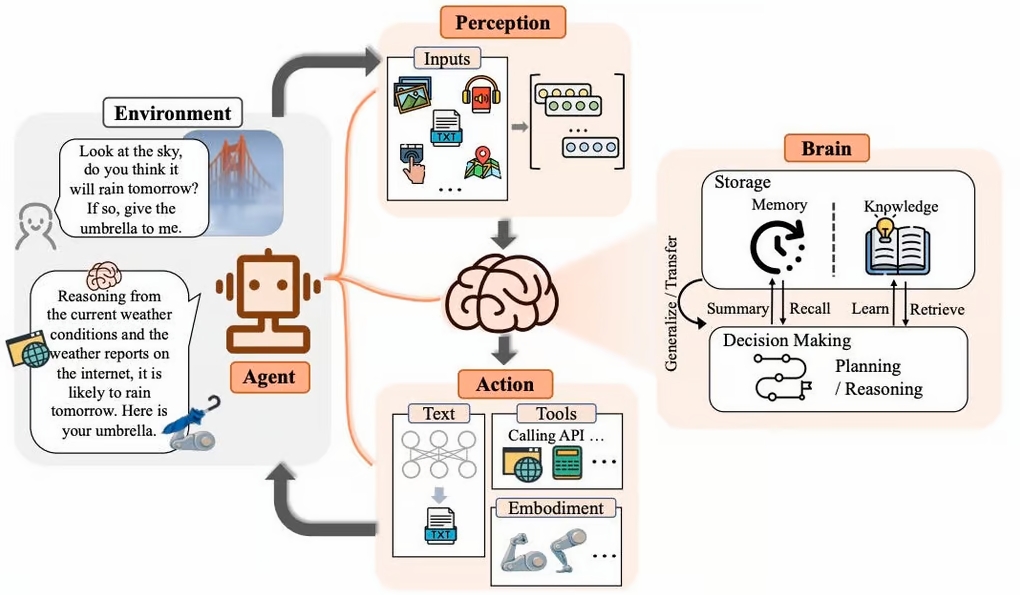
一. 什么是AI Agent?
AI Agent(智能代理)是指一种能够自主感知环境、进行决策并执行任务的智能系统。与传统的计算机程序不同,AI Agent不仅仅根据预设规则执行简单的任务,而是能够根据不断变化的环境进行动态的决策和行动,体现出较高的自主性和灵活性。AI Agent通常具有以下几个特点:
-
自主性(Autonomy)
AI Agent能够在没有人为干预的情况下自主运行。这意味着它能够独立分析环境并做出决策,执行预定的任务。这种自主性是AI Agent区别于传统计算机程序的核心特点。 -
感知能力(Perception)
AI Agent通过传感器、数据源、API接口等获取关于环境的实时数据。例如,自动驾驶汽车中的AI Agent通过摄像头、雷达、激光雷达等设备感知周围环境,以此来做出行车决策。 -
推理能力(Reasoning)
感知到的信息需要经过分析与处理,AI Agent需要具备强大的推理能力。在推理过程中,它可能会使用规则、模型或者算法来分析环境信息,并据此做出决策。例如,在金融分析中,AI Agent可能通过大量的历史数据,识别市场趋势,预测股市变化。 -
行动能力(Action)
一旦AI Agent做出决策,它就会根据目标采取相应的行动。行动可以是虚拟的(如调整网络参数、发送消息等)或物理的(如控制机器人的移动、执行自动化操作等)。这一过程需要AI Agent能够根据实际环境反馈实时调整策略。 -
目标导向(Goal-Oriented)
AI Agent的行为通常是为了实现特定的目标。这些目标可能是预设的,也可能是通过与环境的交互逐渐定义和优化的。目标导向的特性使得AI Agent能够在复杂环境中持续运作并适应变化。 -
学习与适应能力(Learning and Adaptation)
现代AI Agent不仅仅局限于静态规则或模型,它们通常具备学习能力,能够通过与环境的交互逐渐优化自己的行为。AI Agent可以通过强化学习、迁移学习等方法,自我提高决策和执行能力。
简而言之,AI Agent不仅能在复杂和动态的环境中感知、推理、决策,还能根据目标采取行动,甚至在面临新的挑战时,通过学习逐步优化自己的表现。它们能够不断改进,解决不同领域中的多种任务,比如自动驾驶、智能推荐、智能客服等。
二. AI Agent的工作原理
AI Agent的工作原理可以从感知、推理、决策和行动等几个关键过程来解释。以下是AI Agent工作原理的详细解析:
2.1 感知阶段(Perception Phase)
AI Agent的第一个步骤是
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









