




📌 友情提示:
本文内容由银河易创AI(https://ai.eaigx.com)创作平台的gpt-4-turbo模型生成,旨在提供技术参考与灵感启发。文中观点或代码示例需结合实际情况验证,建议读者通过官方文档或实践进一步确认其准确性。
在人工智能的快速发展中,扩散模型(Diffusion Models)作为一种新兴的生成模型,正逐渐成为计算机视觉、自然语言处理等领域的热门研究方向。与传统的生成对抗网络(GAN)相比,扩散模型展现出了更好的生成质量和稳定性。本文将探讨扩散模型的基本原理、应用实例及其未来的发展趋势。
一、扩散模型的基本原理
扩散模型的基本原理源自物理学中的扩散过程,旨在通过模拟噪声的添加和去除,实现数据生成。这一过程通常分为两个阶段:前向扩散过程和反向扩散过程。
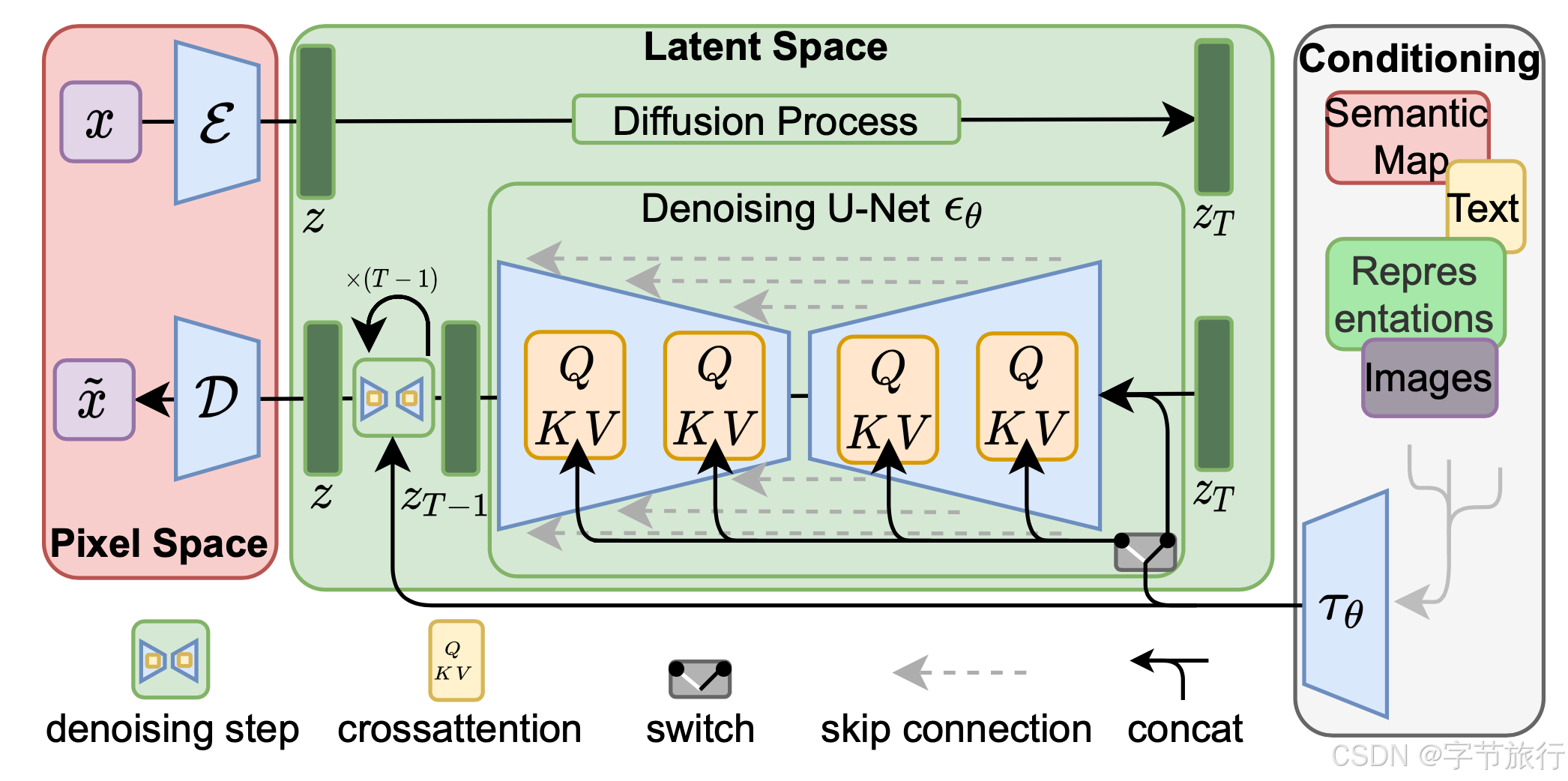
1. 前向扩散过程
前向扩散过程的目标是将原始数据逐步转换为完全随机的噪声。具体操作如下:
-
渐进添加噪声:从一个真实图像 x0x0 开始,模型通过一系列的步骤 TT 将高斯噪声逐步添加到该图像中。每一步 tt 都是通过一个固定的方程式进行的:
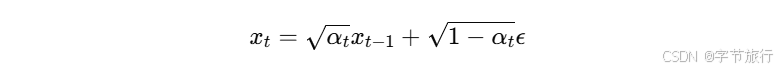
其中,xt 是当前步生成的图像,ϵ 是从标准
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 495
495

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









