






一、Transformer 架构总览
从结构上看,Transformer 由两大核心模块构成
- 编码器(Encoder):负责 “理解” 输入序列,生成富含上下文信息的向量表示;
- 解码器(Decoder):负责 “生成” 目标序列,基于编码器的理解结果和已生成内容,逐步输出最终结果。
这两个模块可灵活组合:既可以单独使用(如仅用编码器做文本理解,仅用解码器做文本生成),也可协同工作(如编码器 - 解码器组合做机器翻译),构成现代大模型的 “骨架”。
无论是编码器还是解码器,核心都依赖自注意力机制(Self Attention)—— 它能让模型 “聚焦关键信息”(比如读 “小明给小红买冰淇淋” 时,重点关注 “小明 / 小红 / 冰淇淋”),这是 Transformer 比传统模型更懂上下文的关键。
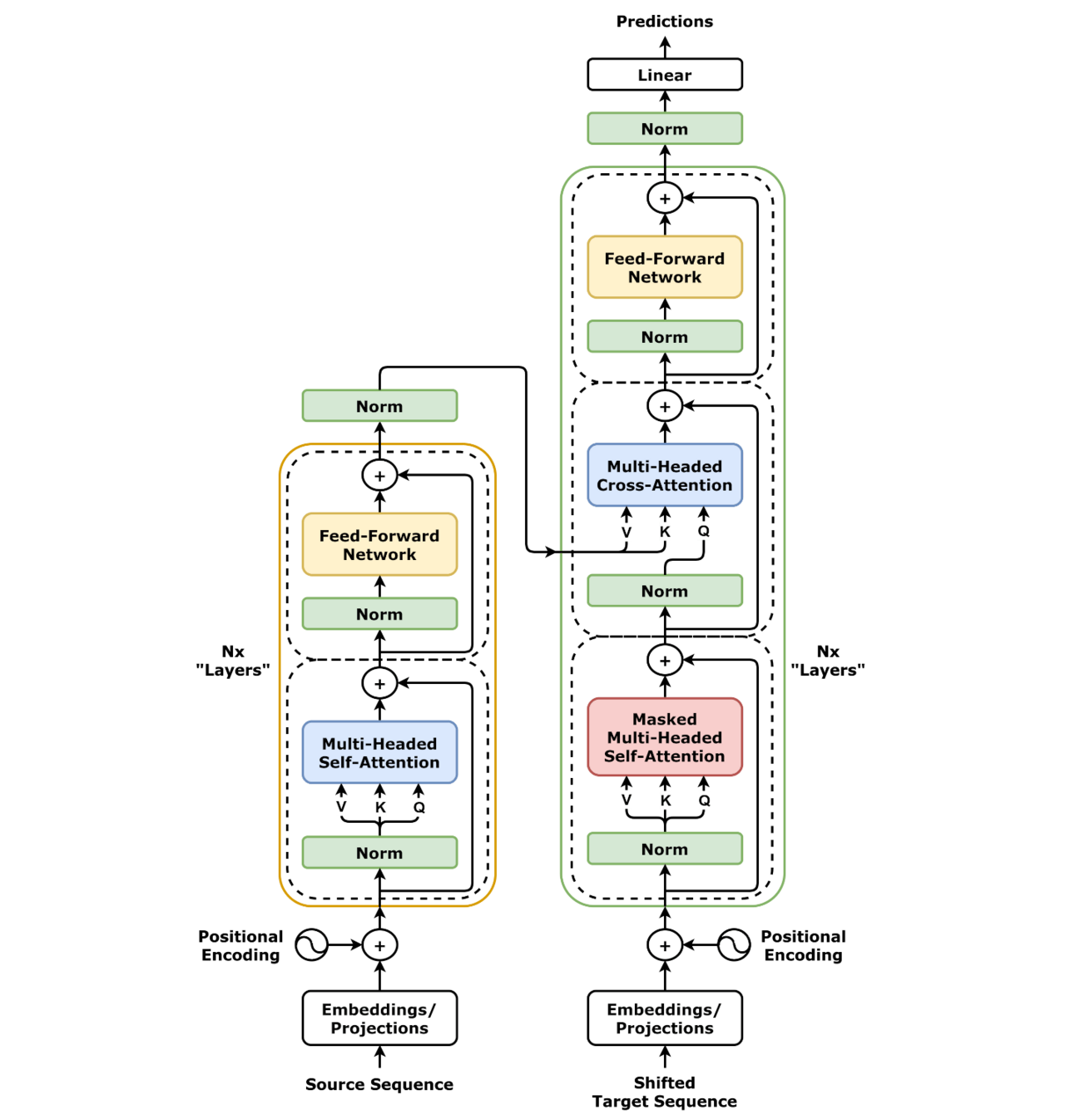
transformer架构图:左边为编码器,右边为解码器
注:图示与原论文Post-LN结构不同,采用Pre-LN设计以缓解梯度消失问题。依据:《On Layer Normalization in the Transformer Architecture》(ICML 2020)
二、核心对比:BERT 与 GPT 如何 “改造” Transformer?
(一)架构选择差异:对 Transformer 模块的 “取舍” 不同
1. BERT:仅用编码器(Encoder-only)—— 聚焦 “双向语义理解”
BERT(Bidirectional Encoder Representations from Transformers,2018)由 Google 提出,其核心是堆叠多层编码器,完全舍弃了解码器。
- ✅ 优势:能够同时看到一个词的前后文,实现真正的 “双向理解”;
- ❌ 局限:不具备自回归生成能力,无法直接用于文本续写;
- 📌 应用场景:适合需要 “读懂” 文本的任务,如情感分析、命名实体识别、语义相似度判断。
2. GPT:仅用解码器(Decoder-only)—— 聚焦 “单向文本生成”
GPT(Generative Pre-trained Transformer,2018)由 OpenAI 提出,基于 Transformer 的解码器部分构建。
- ✅ 优势:采用自回归方式,逐词生成,天然适合文本创作;
- ❌ 局限:只能看到 “过去的词”,无法像 BERT 那样双向感知;
- 📌 应用场景:适合需要 “写出” 内容的任务,如对话生成、文章续写、代码补全。
💡 关键洞察:BERT 和 GPT 的根本差异,不是 “谁更先进”,而是对 Transformer 模块的不同取舍,反映了 “理解” 与 “生成” 两类任务的本质区别。
(二)训练目标差异:从 “学理解” 到 “学生成” 的核心区别
1. BERT:掩码语言模型(MLM)+ 句子关系预测(NSP)
BERT 的预训练任务有三个,通过 “考试式” 训练强化语义关联能力:
MLM(Masked Language Modeling):
随机遮盖输入中 15% 的词,让模型根据上下文预测被遮盖的词。
例:“我喜欢 [MASK] 天去公园” → 模型预测 “每”。
训练目标:让模型掌握 “词的搭配逻辑”“句子的语义结构”,比如 “喝” 常搭配 “水 / 咖啡”,“首都” 常对应 “国家名称”。
NSP(Next Sentence Prediction):
判断两个句子是否连续,增强模型对篇章结构的理解。
例:“我喜欢吃草莓”+“它的酸甜味很特别”(连续);“我喜欢吃草莓”+“今天下雨了”(不连续)。
训练目标:让模型掌握 “文本的叙事逻辑”“因果 / 顺承关系”,比如 “买了食材” 后常接 “开始做饭”,而非 “去看电影”。
⚠️ 注:后续研究(如 RoBERTa)发现 NSP 任务收益有限,许多现代模型已弃用。
下游任务微调(Fine-tuning):
在少量标注数据上,通过在输出层增加任务相关模块,对整个模型进行端到端微调。
例:若任务是 “情感分析”(判断评论正负):在 BERT 输出层加 “二分类头”,用标注好的 “好评 / 差评” 数据微调,让模型学会将 “这家店服务超差” 映射为 “负面”,“菜品很惊艳” 映射为 “正面”。
训练目标:让模型从 “通用理解” 转向 “任务专用”,在具体场景中输出精准结果,而非仅具备 “泛泛的语义能力”。
2. GPT:因果语言模型(CLM,又称自回归语言模型)
GPT 采用 “写作式” 训练,通过从左到右的文本续写强化生成逻辑:
- 输入:“人工智能正在”;
- 目标:预测下一个词 “改变” → 再预测 “世界” → 如此循环,逐步生成连贯文本。
💡 本质区别:BERT 在 “做填空题和阅读理解”,GPT 在 “写作文和讲故事”。
(三)能力与场景差异:“理解专才” 与 “生成专才” 的应用分野
| 维度 | BERT | GPT |
|---|---|---|
| 核心能力 | 语义理解、文本分类 | 文本生成、逻辑推理 |
| 典型任务 | 情感分析、实体识别、语义匹配 | 对话系统、文章创作、代码生成 |
| 代表模型 | BERT、RoBERTa、ERNIE | GPT-2、GPT-3、ChatGPT、GPT-4 |
| 微调方式 | 添加分类头,微调整个模型 | 提示工程(Prompting)或微调解码器 |
🌰 实例对比:
- 判断 “这部电影真棒!” 是正面还是负面情感?→ BERT 更擅长;
- 续写 “从前有一只小猫,它……” → GPT 更擅长。
三、延伸拓展:Transformer 的更多 “应用变形”
除了 Encoder-only 的 BERT 和 Decoder-only 的 GPT,研究者还尝试不同组合与扩展,衍生出多种应用变形。
(一)Encoder-Decoder 双全型:T5、BART—— 兼顾 “理解” 与 “生成”
当任务既需要理解又需要生成时(如翻译、摘要),完整的 Encoder-Decoder 架构再次回归,融合两类能力:
- T5(Text-to-Text Transfer Transformer):将所有 NLP 任务统一为 “文本到文本” 格式,如 “翻译:Hello → 你好”;
- BART:先用编码器 “破坏” 文本(如删除、打乱),再用解码器 “修复”,在文本摘要、机器翻译中表现优异。
(二)垂直领域定制型:RoBERTa、CodeGPT—— 让 Transformer 适配细分需求
在 BERT/GPT 基础上,通过优化训练策略或数据,打造领域专用模型,精度远超通用模型:
- RoBERTa:去掉 NSP 任务、增大 batch size、使用更多训练数据,显著提升 BERT 性能;
- CodeGPT / Codex:在海量代码语料上训练 GPT,实现 “自然语言→代码” 生成;
- BioBERT / SciBERT:在生物医学文献或学术论文上微调,提升专业领域文本理解能力。
(三)多模态延伸:ViT、FLAVA——Transformer 突破 “文本边界”
Transformer 的成功不仅限于文本,还被扩展到图像、语音等模态,成为统一多模态智能的通用架构:
- 架构迁移型:ViT、Whisper——将非文本数据结构化为“序列”,适配 Transformer
- 跨模态融合型:CLIP、FLAVA——联合训练图文编码器,实现语义对齐与检索
四、总结与启示 —— Transformer 的 “灵活性” 成就大模型生态
(一)核心结论:BERT 与 GPT 的差异,本质是 Transformer 模块的 “差异化应用”
- BERT 是 “理解专家”:源于编码器 + MLM 训练,擅长语义分析、文本判断类任务;
- GPT 是 “生成大师”:源于解码器 + CLM 训练,擅长文本创作、逻辑续写类任务;
- 两者并非对立关系,而是同一架构在不同任务目标下的合理演化,共同构成大模型 “理解 - 生成” 能力的基础。
(二)技术启示:Transformer 的可扩展性,是大模型持续进化的关键
大模型的创新,往往不是 “从零发明”,而是基于 Transformer 架构的 “乐高式组合”:
- 架构重组:如仅用 Encoder 做理解、仅用 Decoder 做生成,或两者结合做跨模态任务;
- 数据驱动:通过更大规模、更高质量的语料(如多语言文本、多模态数据)提升模型泛化能力;
- 目标对齐:设计与任务匹配的预训练目标(如 MLM 适配理解、CLM 适配生成),让模型 “学有专攻”。
这种灵活的创新范式,不仅降低了大模型的研发门槛,更推动了从单一文本任务到多模态智能的快速演进,成为当前 AI 技术突破的核心动力。
当然,Transformer 也非万能:其高计算成本、生成幻觉等问题仍待解决。但其展现出的架构灵活性,无疑为未来 AI 提供了最坚实的演化基础。

















 526
526

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









