






主要内容:
1,Selenium的使用
2,验证码识别
1,Selenium
(1)Selenium是一种开源工具,属于python的第三方库,可以实现模拟人操作浏览器,实现网页操作自动,减少重复性工作。 主要运用于爬虫,自动化测试等领域。
(2)Selenium优势:
- 逼真模拟用户操作网页
- 跨平台(windows,Linux,android,iOS)
- 跨浏览器(Firefox,IE,chrome,opera,safari)
- 多语言支持(java,c#,python,ruby,php,perl,js)
- 开源免费
- 不要钱的web测试工具
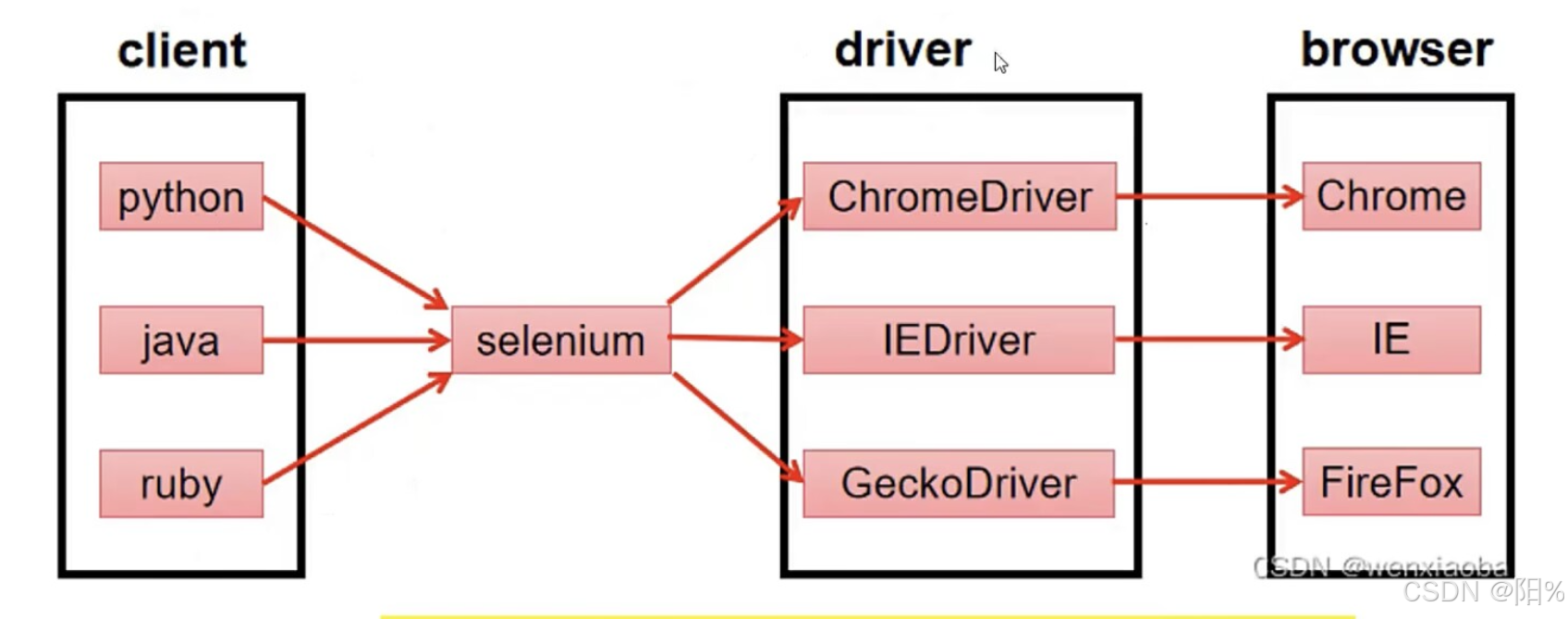
(只是工具,需要与第三方浏览器结合使用)
课前下载:
<1>,chrome-win64 ----在官网下载,注意,要和谷歌浏览器的版本号相一致,下载后要放在python文件的script中;
<2>,Selenium,这玩意在windows+r终端中下载,---pip install Selenium 即可
<3>,vscode
2,简单的一些代码操作:
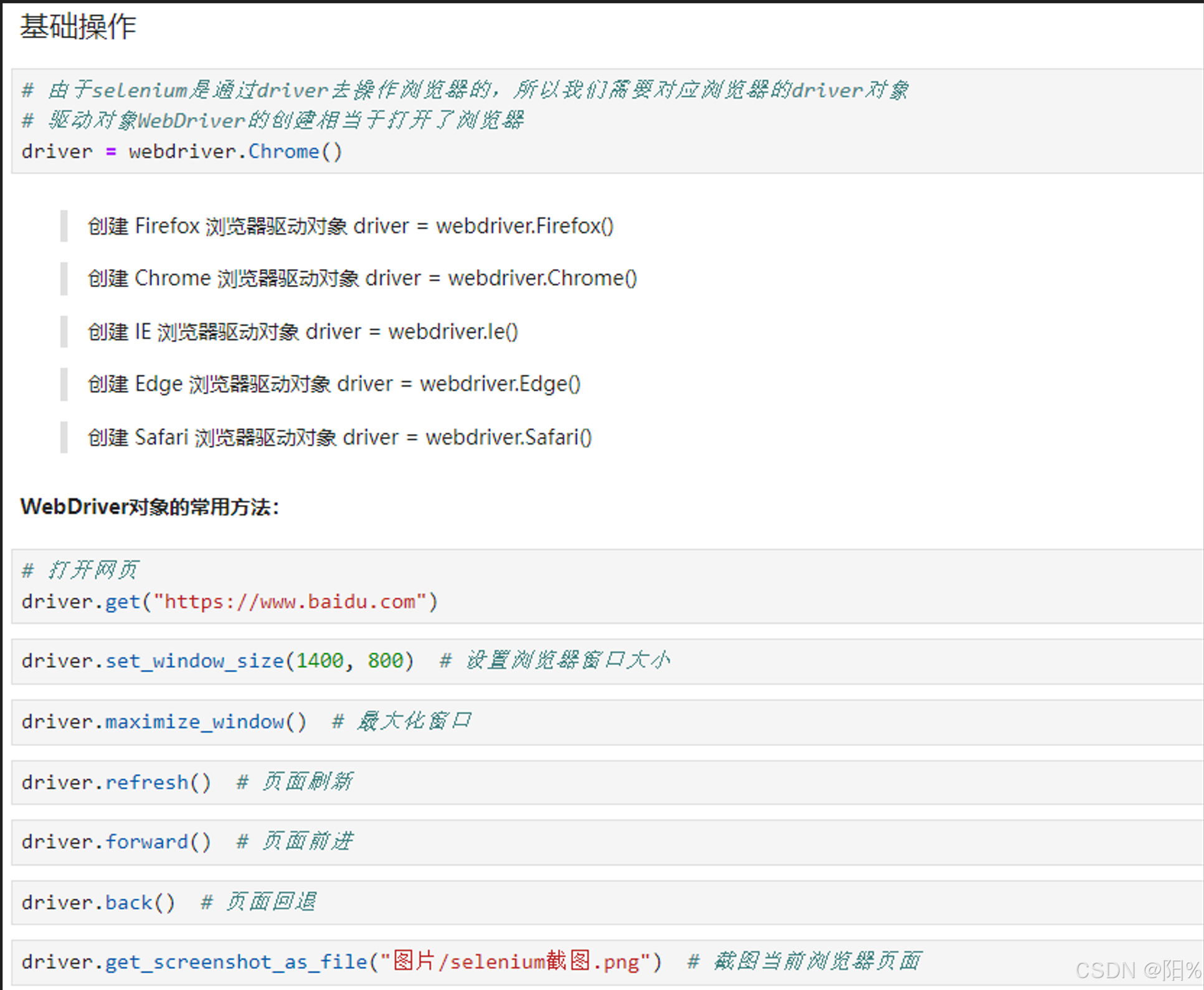
(1) 这是人机操作打开浏览器:
import time
from selenium import webdriver
# 初始化一个浏览器对象
browers=webdriver.Chrome()
# 打开指定网页
browers.get("https://www.baidu.com")(2)人机截图:
# 我们尝试一下截图操作:
browers.save_screenshot("文件名.jpg")(3)人机推出浏览器:
# 人机退出浏览器
browers.quit()(但如果我们设置了time.sleep()他会自动退出)
(4)人机操作浏览器帮我们搜索东西:
我们先去获取搜索栏的基础信息:
据我们了解,id的值一般都是唯一的(不然我们也可以在当页搜索栏查找一下,看有没有在其他地方被使用)
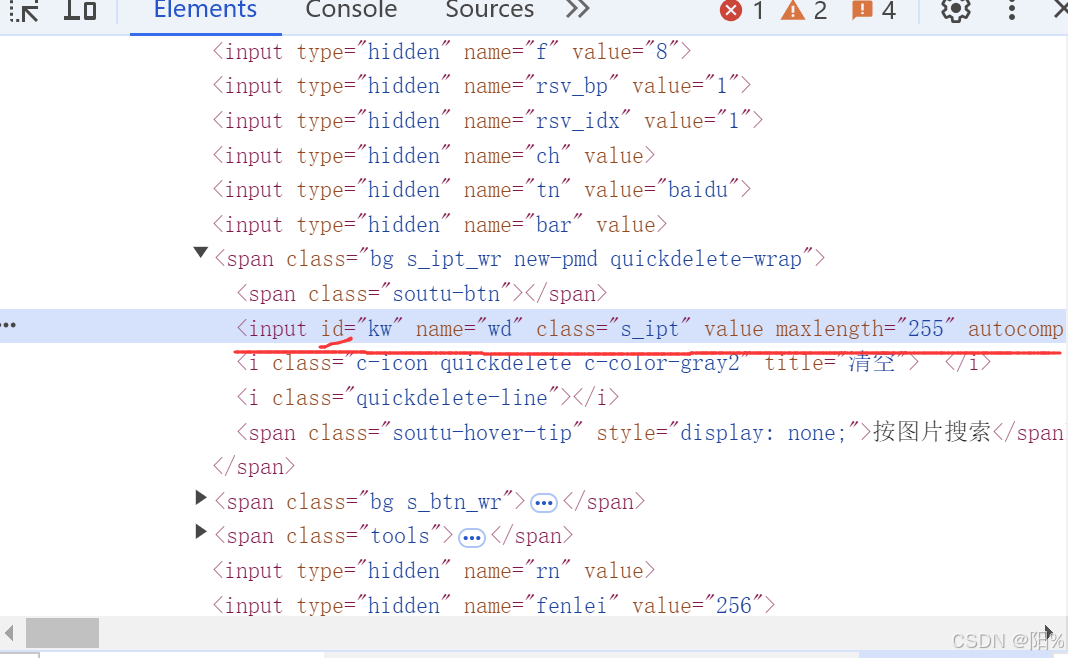
我们优先导入选择器:
# 这是selenium中的标签选择器
from selenium.webdriver.common.by import By通过这玩意,我们可以查到很多标签:如下:
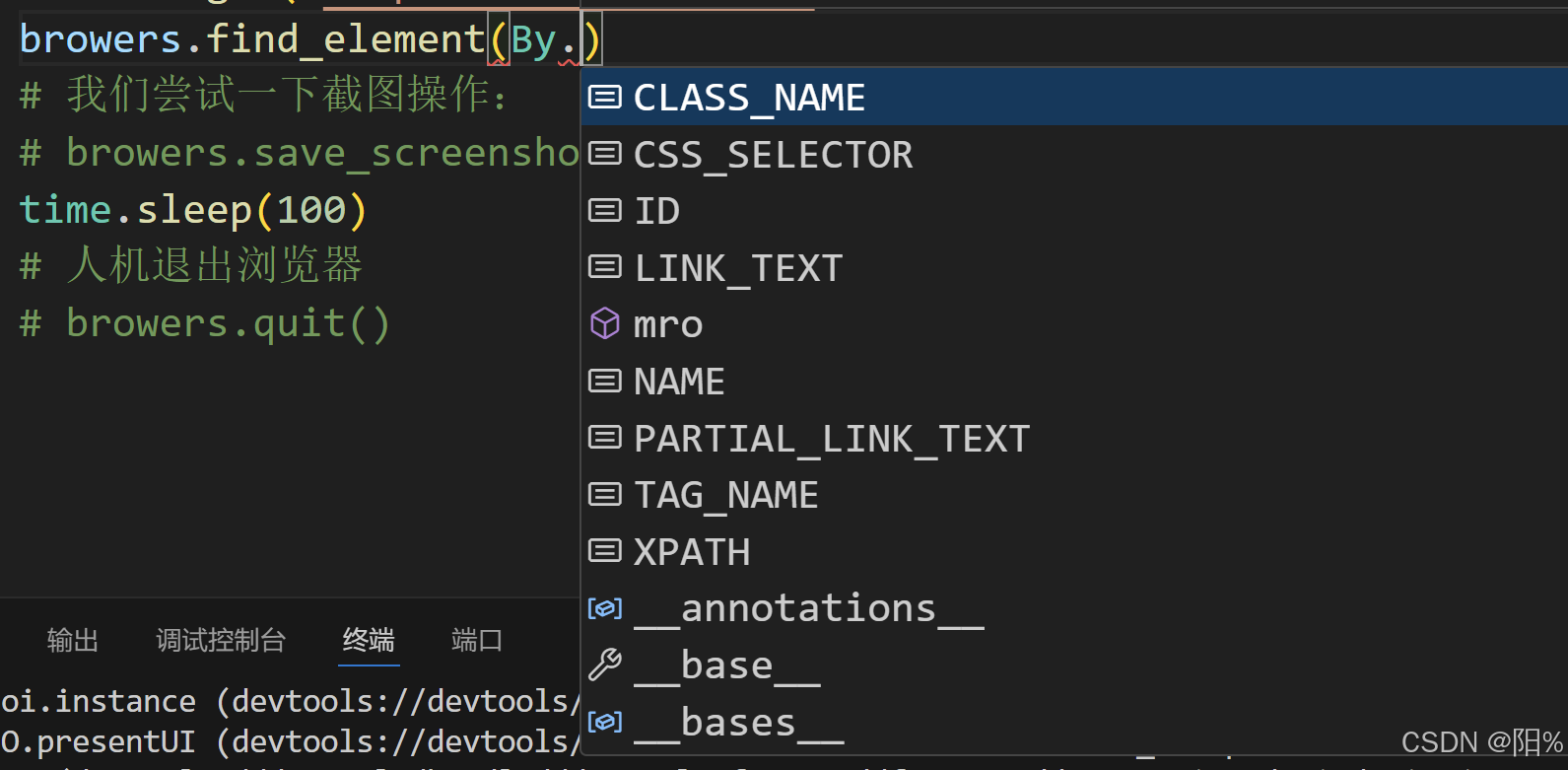
接着:
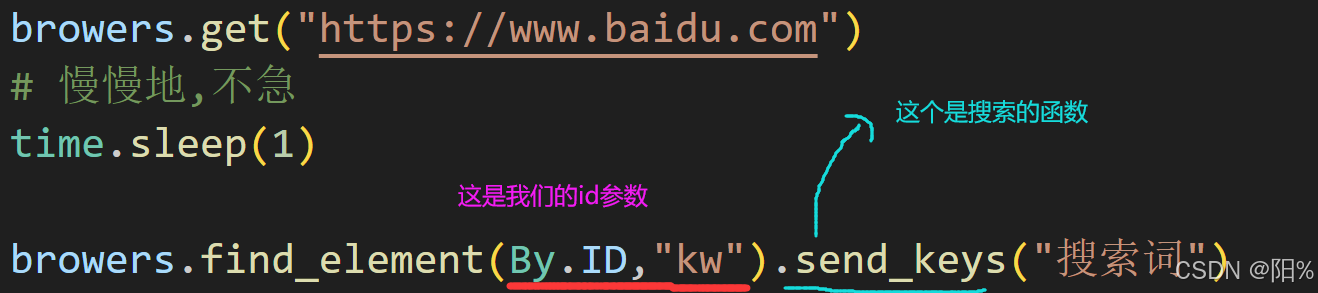
执行:
(5)得寸进尺一点,我们让人机待我们敲键盘:
先导入键盘中的各种键:
from selenium.webdriver.common.keys import Keys# 模拟敲一个空格
browers.find_element(By.ID,"kw").send_keys(Keys.SPACE)其他键盘指令;

一个完整的搜索指令代码:
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
browers=webdriver.Chrome()
browers.get("https://www.baidu.com")
time.sleep(1)
browers.find_element(By.ID,"kw").send_keys("搜索词")
time.sleep(1)
# 你当然可以选择不让他休息
browers.find_element(By.ID,"kw").send_keys(Keys.ENTER)补充:
基础操作:
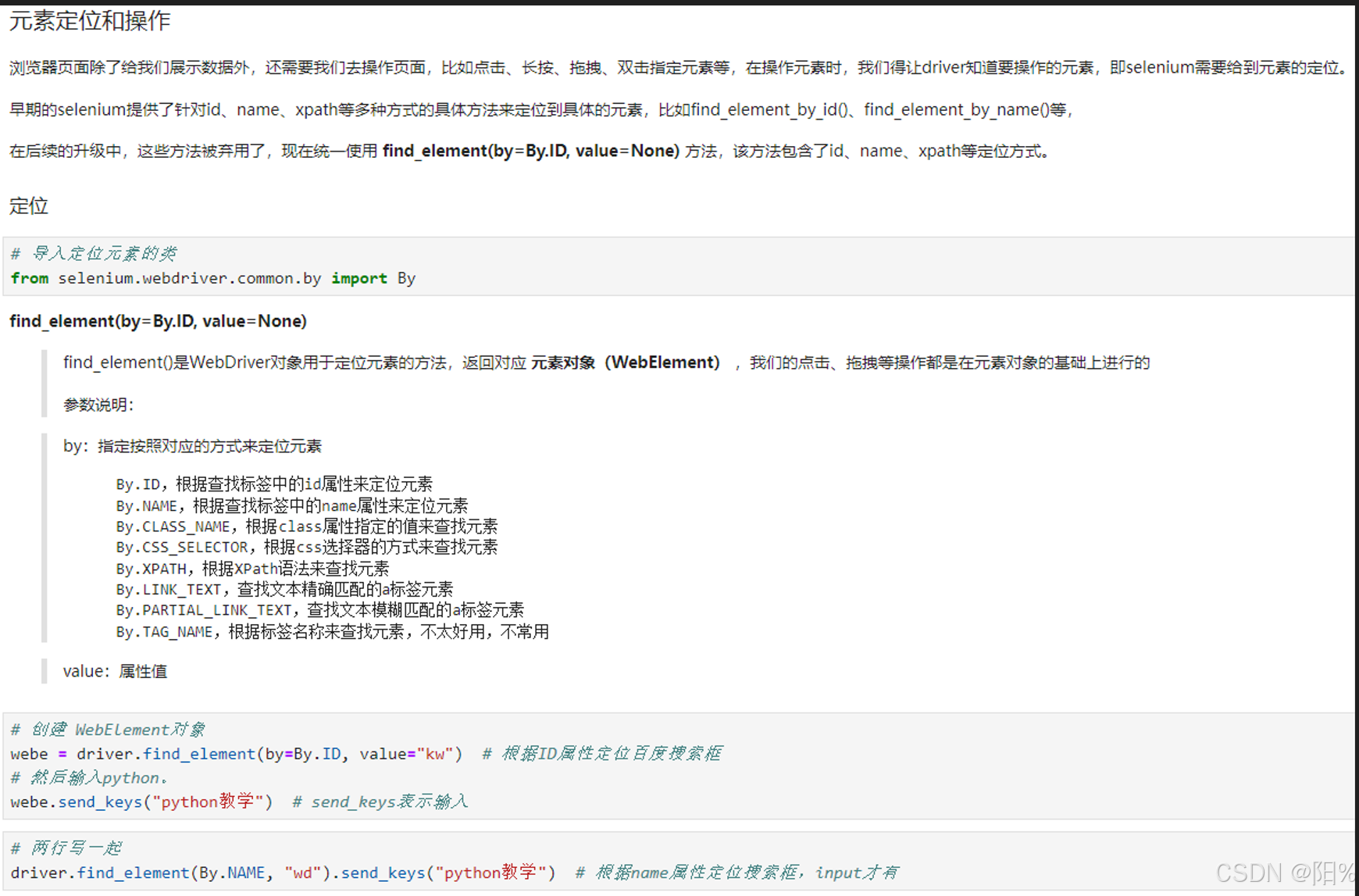
selenium元素定位:
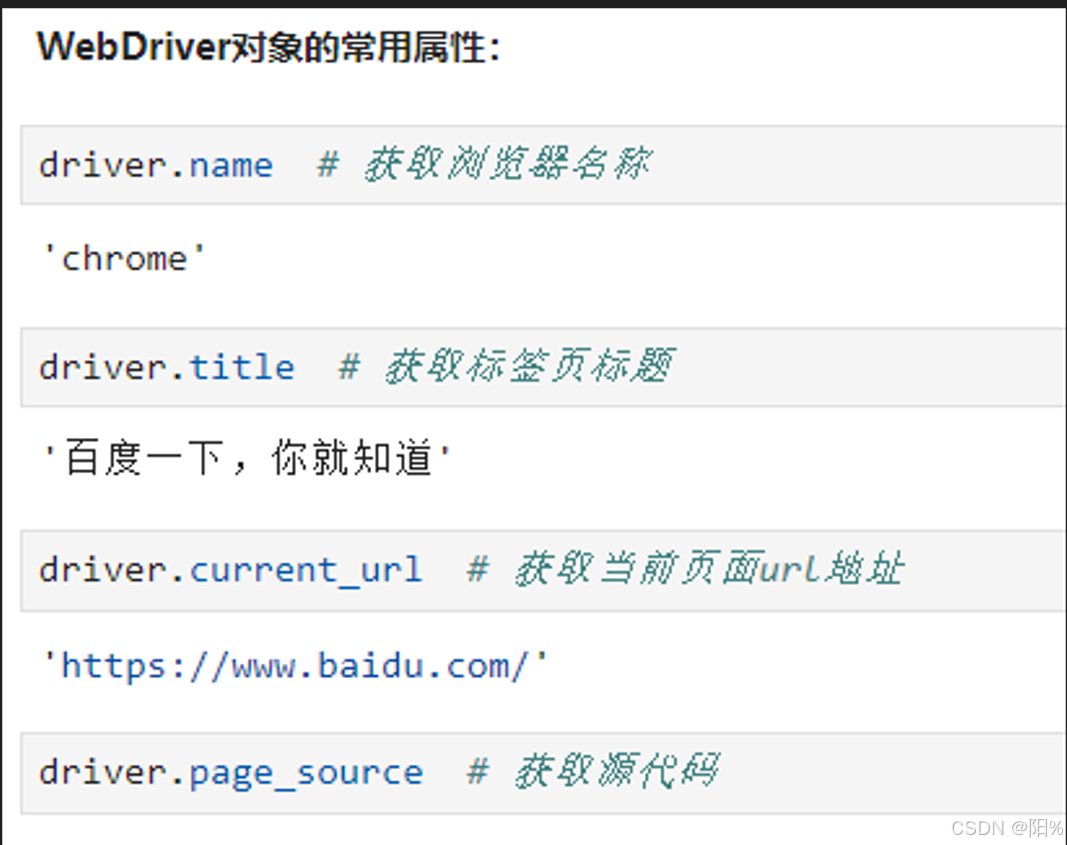
selenium常用属性:
2,验证码
(1)验证码:全名:“全自动区分计算机和人类的图灵测试”,简称CAPTCHA;用于区分人和计算机
类型:字母,字母加数字,人物或物品识别,滑动验证码等。
(2)关于破译验证码的一些操作:
网址推荐:"图片识别-广告识别-目标检测-准muq快信息技术有限公司"----可用于图片验证码的破译: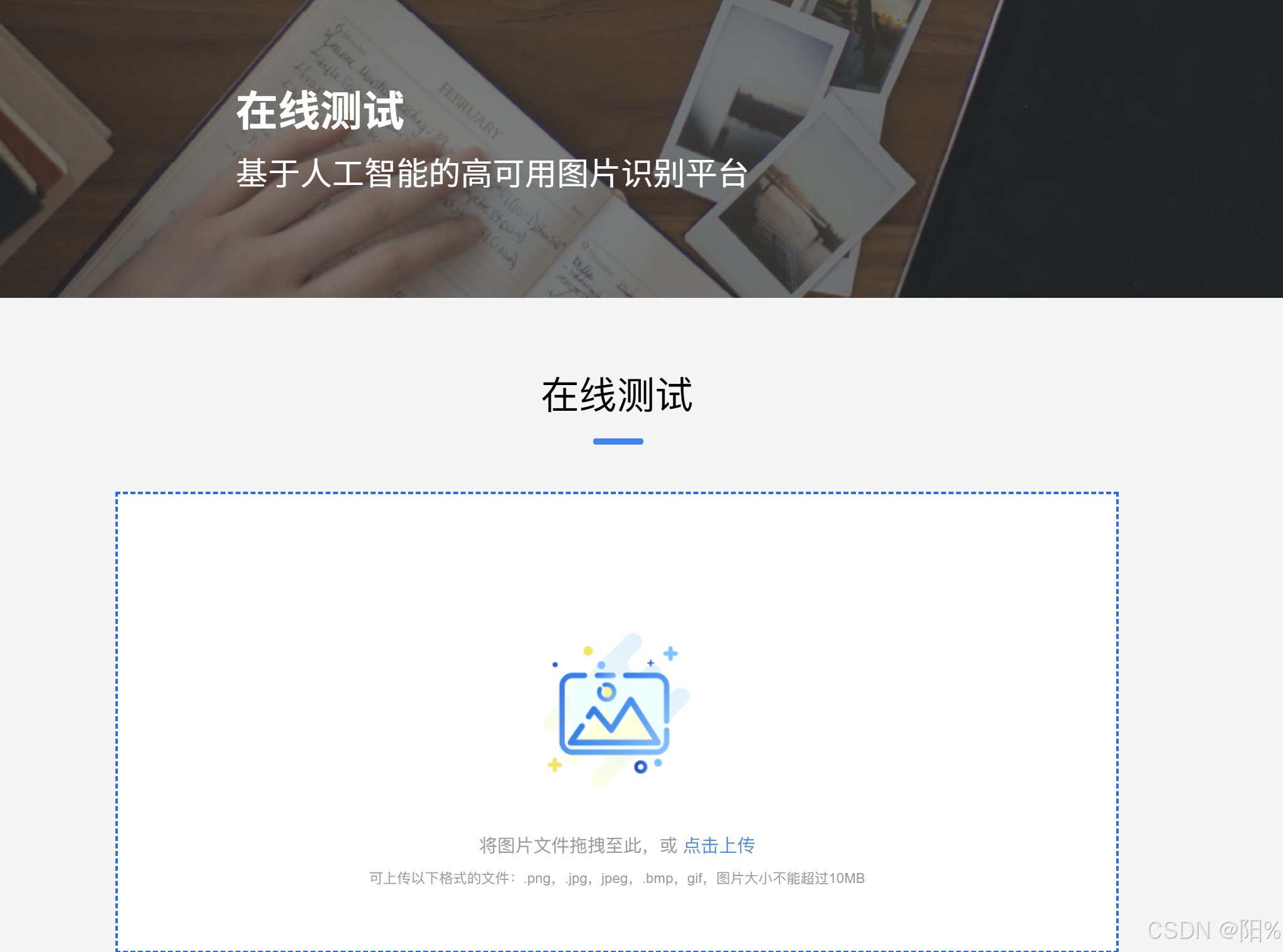
识别并非百分比;
当我们利用python去爬取网页需要破解二维码时:
import base64
import json
import requests
# 一、图片文字类型(默认 3 数英混合):
# 1 : 纯数字
# 1001:纯数字2
# 2 : 纯英文
# 1002:纯英文2
# 3 : 数英混合
# 1003:数英混合2
# 4 : 闪动GIF
# 7 : 无感学习(独家)
# 11 : 计算题
# 1005: 快速计算题
# 16 : 汉字
# 32 : 通用文字识别(证件、单据)
# 66: 问答题
# 49 :recaptcha图片识别
# 二、图片旋转角度类型:
# 29 : 旋转类型
#
# 三、图片坐标点选类型:
# 19 : 1个坐标
# 20 : 3个坐标
# 21 : 3 ~ 5个坐标
# 22 : 5 ~ 8个坐标
# 27 : 1 ~ 4个坐标
# 48 : 轨迹类型
#
# 四、缺口识别
# 18 : 缺口识别(需要2张图 一张目标图一张缺口图)
# 33 : 单缺口识别(返回X轴坐标 只需要1张图)
# 五、拼图识别
# 53:拼图识别
def base64_api(uname, pwd, img, typeid):
with open(img, 'rb') as f:
base64_data = base64.b64encode(f.read())
b64 = base64_data.decode()
data = {"username": uname, "password": pwd, "typeid": typeid, "image": b64}
result = json.loads(requests.post("http://api.ttshitu.com/predict", json=data).text)
if result['success']:
return result["data"]["result"]
else:
#!!!!!!!注意:返回 人工不足等 错误情况 请加逻辑处理防止脚本卡死 继续重新 识别
return result["message"]
return ""
if __name__ == "__main__":
img_path = "C:/Users/Administrator/Desktop/file.jpg"
result = base64_api(uname='你的账号', pwd='你的密码', img=img_path, typeid=3)
print(result)
直接套用上列代码,这串代码也可以从上面链接里面的开发文档里面找到,使用时,输入你的网页账号和密码,还有你需要破解验证码的地址即可;
3,实战教程:
(1)我们先打开网页: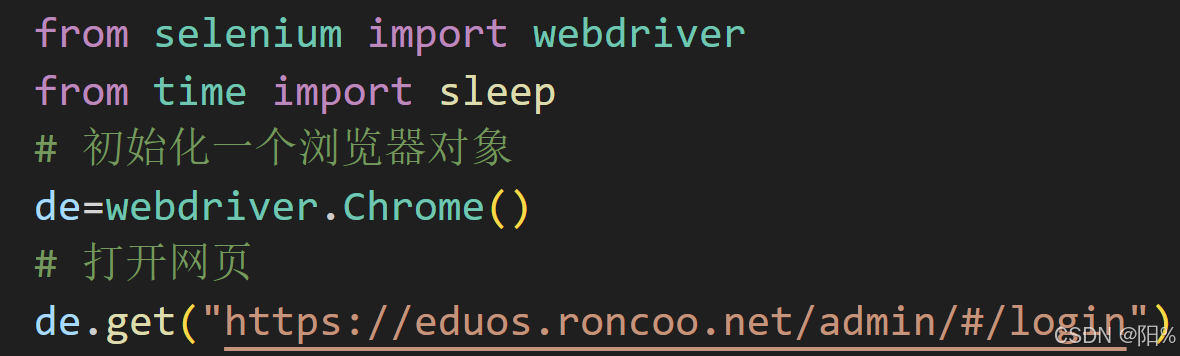
不出意外:

那我们接着来获取他的输入框:
当我们尝试操作输入框内容时:
 出现了以下错误:
出现了以下错误:

他居然说找不到这个id;
我们刷新一下网站:

这里id居然变了,说明这个浏览器做了一些反扒措施,对id进行了加密;id会经常变;
既然这个不行,那我们换个查找方式:
例如我们查找这个class

可以了解到这玩意有三个,但我们是find_element,没有带s,不确定我们找到的是哪一个,但我需要的是第一个,那我们就干脆先加个s呗:

打印一下看看:-----------------------------ok,都给我们了,注意:我们不要随意的设置sleep时间,否则有的时候我们还没打开网站进行下面的操作,网页就自动关闭了,这样返还给你的内容就是空。
因为返回给我们的是列表,那我们就可以使用下标的方式提取里面的信息了;
因为我们要的是第一个,那么我们就直接date[0]就好了,
(2)那现在我们来往用户名里面添加信息:
![]()
用户名行确实增加了xxxx

但我们要先删除原本的用户名,再添加我们的用户名:-------那我们就先清理:
# 清除用户名:
date[0].clear()好,运行一下

既然这么听话,我们就接着往下进行吧!
密码操作是一样的;这边不细说了;
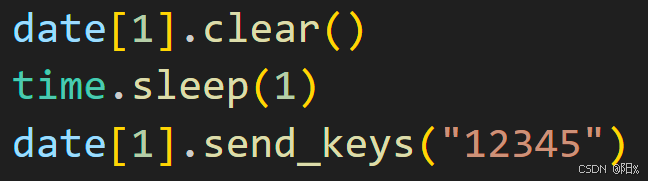
(3)现在我们来搞定验证码------------这也是最麻烦的

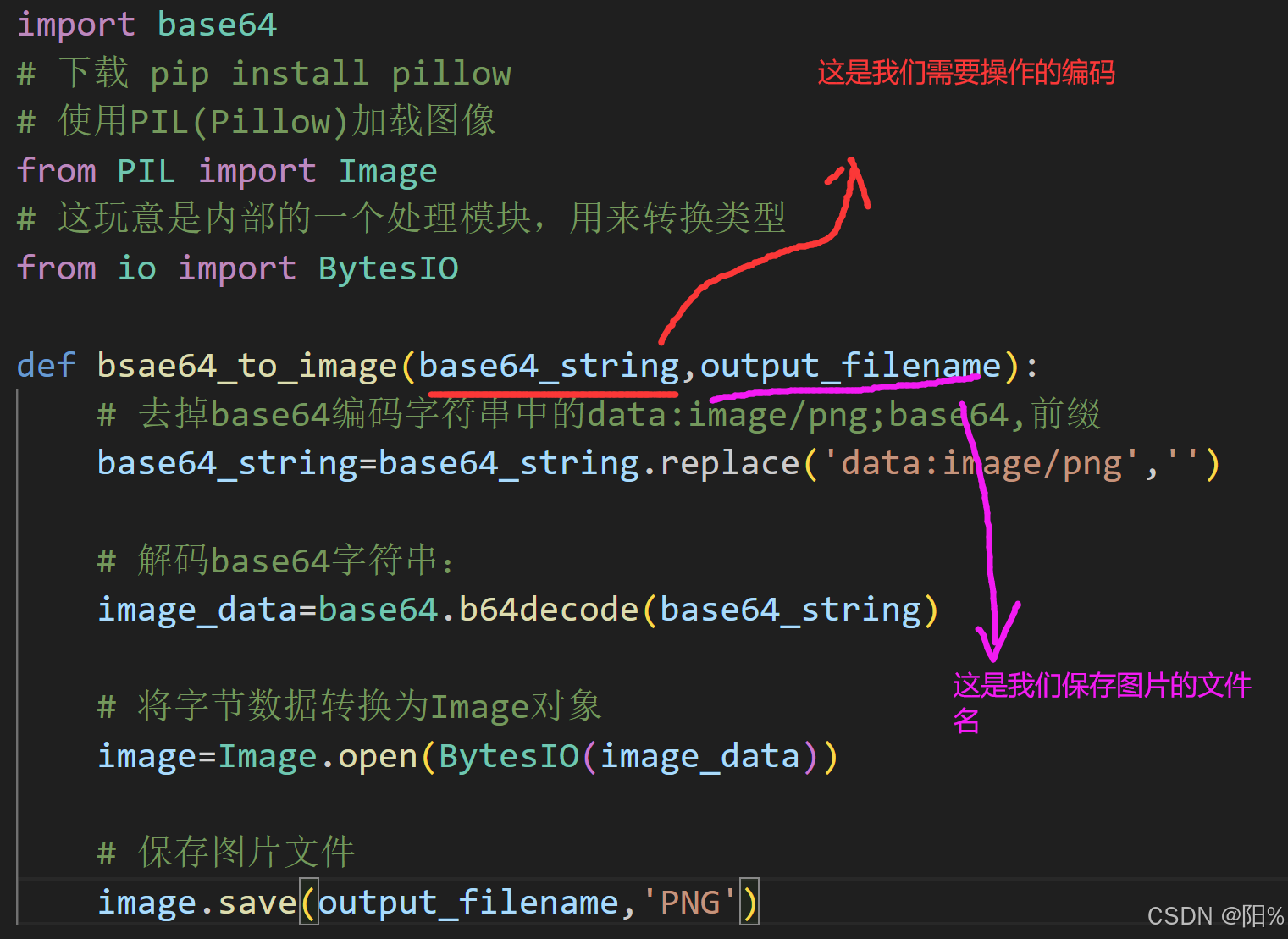
我们看看以验证码的源代码;可以发现验证码是由bs64进行编码的,而我们想要将编码变成图片文件,那我们也来写个base64函数:
import base64
# 下载 pip install pillow
# 使用PIL(Pillow)加载图像
from PIL import Image
# 这玩意是内部的一个处理模块,用来转换类型
from io import BytesIO
def bsae64_to_image(base64_string,output_filename):
# 去掉base64编码字符串中的data:image/png;base64,前缀
base64_string=base64_string.replace('data:image/png','')
# 解码base64字符串:
image_data=base64.b64decode(base64_string)
# 将字节数据转换为Image对象
image=Image.open(BytesIO(image_data))
# 保存图片文件
image.save(output_filename,'PNG')注意我们的参数
那现在我们来调用一下我们刚才的函数:
很好的拿到了;
那我们现在就是继续浏览器人机操作获取图片的bs64编码
我们发现,验证码界面没有设置反扒的措施,
那我们先获取第一步的信息:
# 拿到图片标签页面
yanzm=de.find_element(By.CLASS_NAME,"var-img")
print(yanzm)返还给我们的是下面这串信息

这是selenium模块里面的信息,我们无需看得懂
目的明确,我们需要的是var-img中的src属性内容
因为,yanzm就是我们var-img行代表的内容,那我们就用vs自带的函数(.get_attribute("标签名") )来获取其中的属性内容
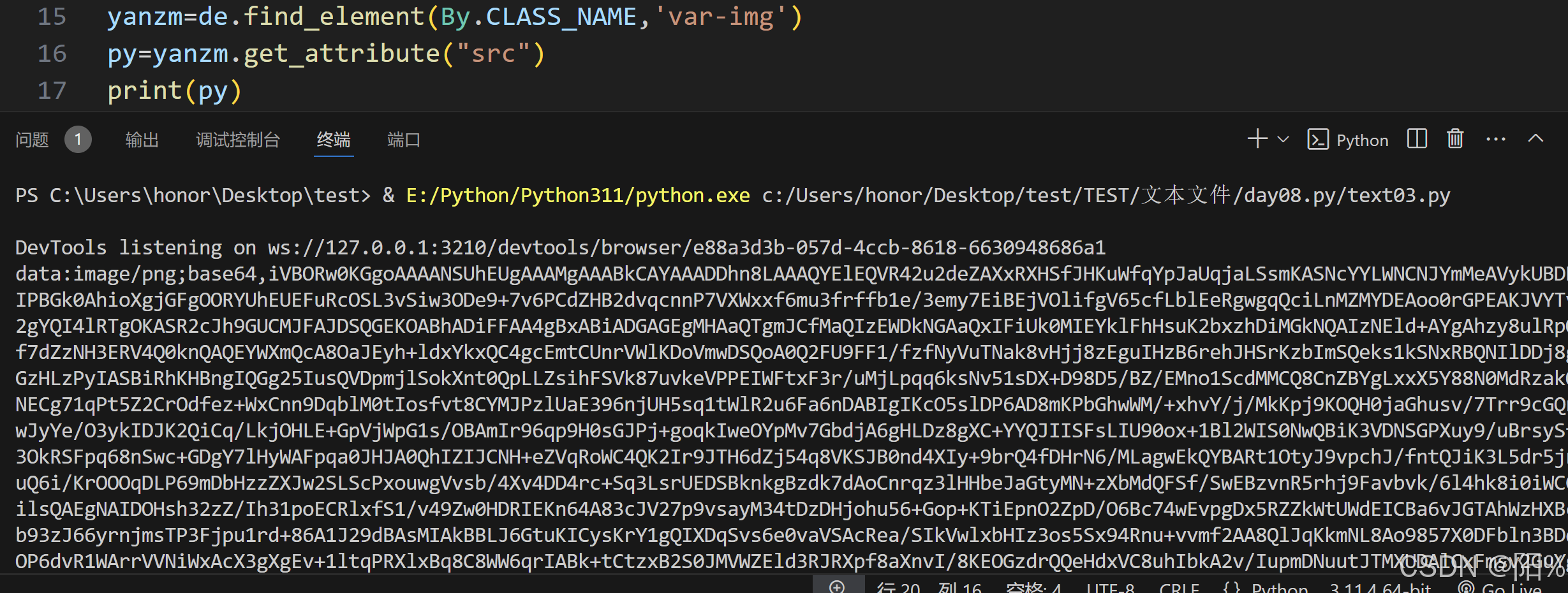
那我们现在来调用我们bs64函数文件

然后我们再调用一下,就可以获得相应验证码的编码了
name="文件1.jpg"
base64_to_image(py,name)那现在我们来对验证码进行破译:
同样的方式,我们引用外部的文件中的函数:---------------外部文件指的是容纳我们在验证码官网找的代码的文件
from text02 import base64_api然后我们直接调用就可以了
base64_api(uname='用户名', pwd='密码', img=name, typeid=7)(4)现在我们来输入验证码
ak=base64_api(uname='用户名', pwd='密码', img=name, typeid=7)
date[2].send_keys(ak)
那现在我们搞个登录点击事件:
我们先找到登录按钮点击的源码:

然后再在vs里面操作:
de.find_element(By.TAG_NAME,'button').click()(注意:我们不能用clss属性进行搜索,因为class不是他的标签名;TAG_NAME具有查找关键字的功能)
那现在我们就完成了一个比较完整的闭环:
目前为止我们的代码:
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
from text02 import base64_api
from base_to_pic import base64_to_image
de=webdriver.Chrome()
de.get("https://eduos.roncoo.net/admin/#/login")
date=de.find_elements(By.CLASS_NAME,"el-input__inner")
yanzm=de.find_element(By.CLASS_NAME,"var-img")
date[0].clear()
time.sleep(1)
date[0].send_keys("xxxx")
date[1].clear()
time.sleep(1)
date[1].send_keys("12345")
name="文件1.jpg"
py=yanzm.get_attribute("src")
time.sleep(1)
base64_to_image(py,name)
ak=base64_api(uname='用户名', pwd='密码', img=name, typeid=7)
time.sleep(1)
date[2].send_keys(ak)
time.sleep(1)
de.find_element(By.TAG_NAME,'button').click()
time.sleep(300)运行完结果:------------我们账号密码输的本来就不对,这个不要在意

不懂就问,万一网站的验证码给我们设置了反爬措施,我们应该怎么办?
补充:解决网站验证码设置的反爬
还是实战讲解;
实战网址:登录-全本小说网
(1)我们先看看他是怎么进行反扒的:
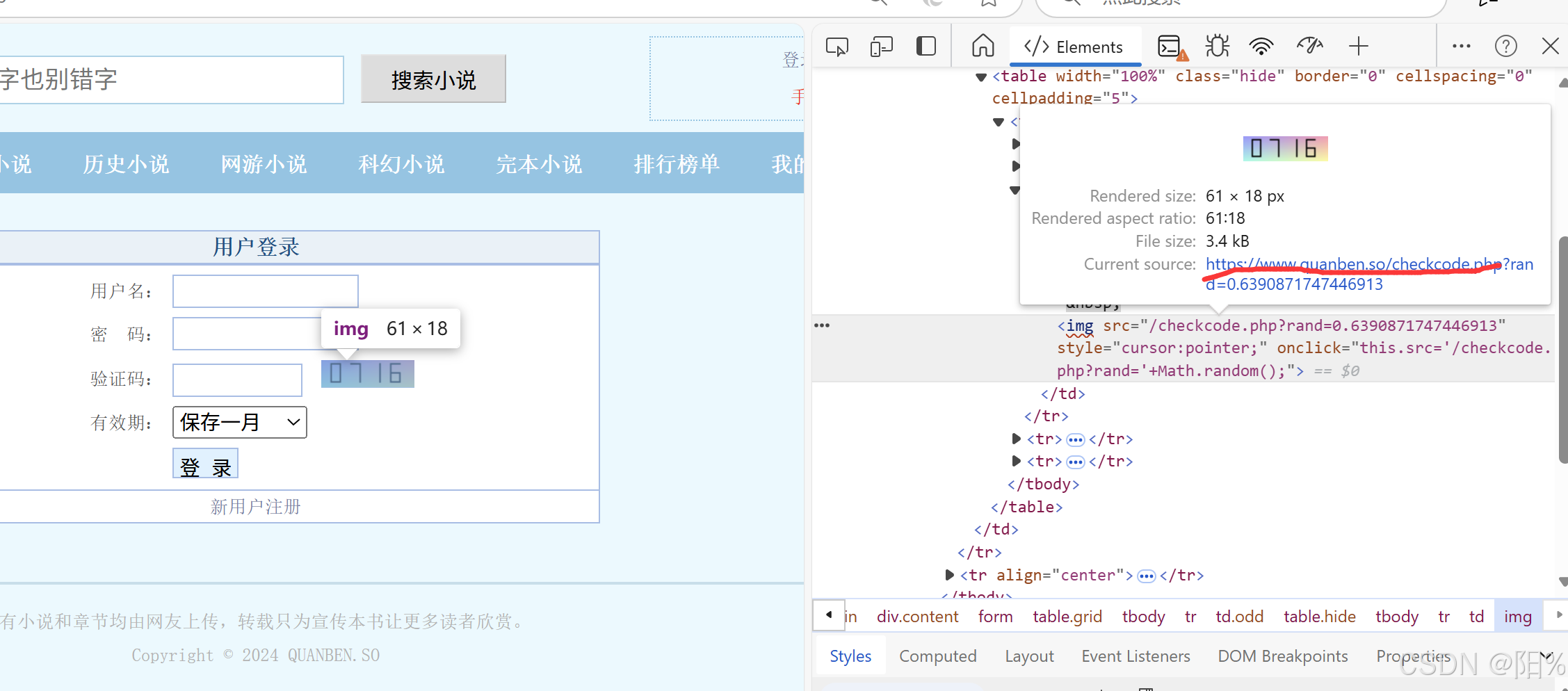
我们点击画线处:
 发现这个dm给我们返还的居然是这玩意,说明他的验证码网址,只要我们访问它,他就会刷新地址;
发现这个dm给我们返还的居然是这玩意,说明他的验证码网址,只要我们访问它,他就会刷新地址;
我们首先还是先进行原本的输入操作:
这个和之前的代码类似或者说相同,我这边就不再说明
那我们就直接说怎样去破解验证码,
方法1:
我们可以打开截图,然后去截取验证码所在的位置,把截图保存下来然后利用刚才的步骤去破解他
(我们前面也讲了一个截取百度网页的操作,但那玩意截的是一整页,不是我们想要的验证码位置,所以我们不用)
第一步:

第二步:
我们来定义一下截图的位置:
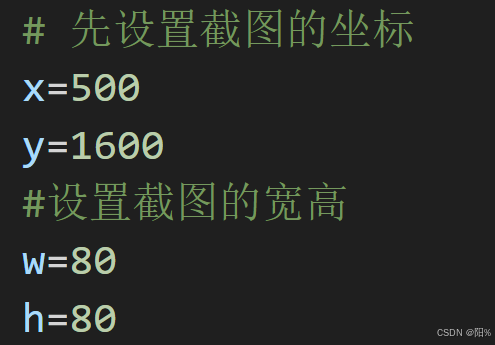 -----------------这个坐标,大家可以通过自己相关的软件工具查询到
-----------------这个坐标,大家可以通过自己相关的软件工具查询到
然后我们再来写一个截图函数:
def capture_region(x,y,w,h):
im=ImageGrab.grab(bbox=(x,y,x+w,y+h))
im.save(image)再调用
# 截取验证码图像
capture_region(x,y,w,h)不出意外我们可以获取验证码图像的文件,

那现在我们重复我们第一个实战的过程:
引用base64_api然后再在下面使用

最后一步,点击登录:
![]()
完成!!
最后我们的整体代码:
import time
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from text02 import base64_api # 前面的是文件名,然后调用里面的函数
from PIL import ImageGrab
de=webdriver.Chrome()
de.get("https://www.quanben.so/login.php")
time.sleep(1)
de.maximize_window()
time.sleep(1)
date=de.find_elements(By.CLASS_NAME,'text')
time.sleep(1)
date[0].send_keys("账号")
time.sleep(1)
date[1].send_keys("密码")
image="xxx.jpg"
def capture_region(x,y,w,h):
im=ImageGrab.grab(bbox=(x,y,x+w,y+h))
im.save(image)
x=1600
y=700 # 这些坐标根据自己的坐标软件进行定位
w=130
h=80
capture_region(x,y,w,h)
time.sleep(1)
ak=base64_api(uname='账号', pwd='密码', img=image, typeid=7)
time.sleep(1)
date[2].send_keys(ak)
time.sleep(1)
de.find_element(By.CLASS_NAME,'button').click()
time.sleep(120)ok,那当我们登录进去后就可以尽情地爬取里面的内容了;


















 4137
4137

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









