






本文仅记录个人学习思考过程,不涉及具体论文内容或代码实现,仅供交流参考。
本文记录了本人从零基础学习并利用相关工具做深度学习毕设的过程,相信你也可以。
一、前置学习(必要理论基础等)
参考视频如下:
- 强推必看,黑马永远的神:黑马程序员10小时搞定毕业设计全套教程,AI智能助力毕业生打造自己专属毕设(含毕设论文模板、毕设选题、开题报告、项目案例、毕业论文写作、论文查重降重、答辩技巧)
- 目标检测1:(包括优化改进YOLO)深度学习目标检测YOLO算法毕业设计项目讲解
- 目标检测2:如何获得项目,常见问题回答,毕设选题避坑,毕设流程讲解
- 目标检测3:项目环境安装配置,项目代码讲解,训练结果和图表讲解,如何使用自己的数据集训练Yolo等模型
- 目标检测4:目标检测论文写作讲解,如何答辩,开题报告如何写
- 深度学习常见实验问题与实验技巧(适用于所有模型,小白初学者必看!)
- 笔记:数据集分配问题:建议尽量分 训练、验证、**测试**集。比例一般为 6:2:2 或 7:1:2。
- 目标检测领域如何水一篇论文,怎样学能快速出结果?迪哥精讲YOLO全系列、DTER模型、R-CNN系列目标检测算法!
- 【硕士论文】用YOLOv8改进做目标检测!这可能是CV方向最好水论文的方向【附14个改进策略】-CVPR论文、硕士论文、毕业论文
- 超详细!实操三天学会YOLOv8模型毕业设计,基于深度学习学习的人脸表情识别l论文+模型详解
- Cursor教程:掌握git指令拿捏代码管理
- 摘要(下面图片来源于上述视频,侵删):
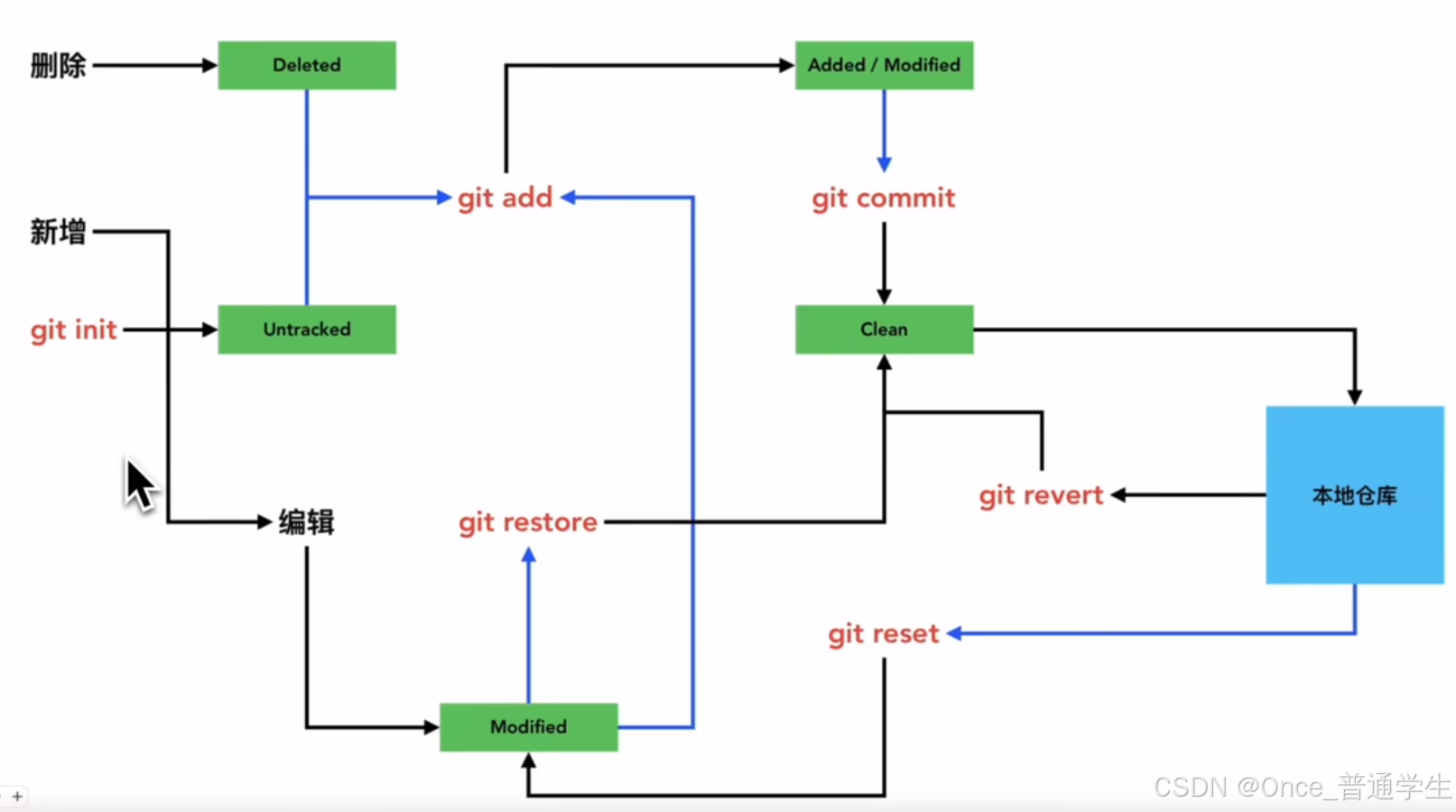

git使用参考:Git向仓库提交代码三步走(add、commit、push)
- 摘要(下面图片来源于上述视频,侵删):
二、YOLO模型训练关键方法
1、 用YOLOv8训练自己数据集的步骤
若提前已经下载好了公开数据集,如果公开数据集内未划分好train、val、test集首先用下面脚本划分。
划分数据集脚本
import cv2
import matplotlib.pyplot as plt
import numpy as np
import random
from tqdm import tqdm
import shutil
import os
def CollateDataset(image_dir, label_dir):
valid_images = []
valid_labels = []
# 收集有效图片和标签
for image_name in os.listdir(image_dir):
image_path = os.path.join(image_dir, image_name)
ext = os.path.splitext(image_name)[-1]
label_name = image_name.replace(ext, ".txt")
label_path = os.path.join(label_dir, label_name)
if not os.path.exists(label_path):
print(f"Label missing: {label_path}")
else:
valid_images.append(image_path)
valid_labels.append(label_path)
# 按比例分配数据集
for i in tqdm(range(len(valid_images))):
image_path = valid_images[i]
label_path = valid_labels[i]
r = random.random()
# 修改后的比例判断逻辑 (8:1:1)
if r < 0.1:
destination = "C:/ultralytics-8.3.81/datasets/design_mian_data/test" #这里需要改,改成你需要保存test集的路径
elif r < 0.2:
destination = "C:/ultralytics-8.3.81/datasets/design_mian_data/val" #这里需要改,改成你需要保存val集的路径
else:
destination = "/ultralytics-8.3.81/datasets/design_mian_data/train" #这里需要改,改成你需要保存train集的路径
# 创建目标目录
os.makedirs(os.path.join(destination, "images"), exist_ok=True)
os.makedirs(os.path.join(destination, "labels"), exist_ok=True)
# 复制文件
shutil.copy(image_path, os.path.join(destination, "images", os.path.basename(image_path)))
shutil.copy(label_path, os.path.join(destination, "labels", os.path.basename(label_path)))
if __name__ == '__main__':
CollateDataset(
"C:/ultralytics-8.3.81/datasets/design_mian_data/images", #这里需要改,改成你的images的路径
"C:/ultralytics-8.3.81/datasets/design_mian_data/labels" #这里需要改,改成你的labels的路径
)#改为下载好的公开数据集的images和labels路径
2、 如何对已经训练过的模型继续训练
下面是腾通元宝给出的代码。
# 加载模型和检查点
model = YOLO("runs/detect/train/weights/last.pt")
# 继续训练
model.train(
data="data.yaml",
epochs=300,
resume=True,
batch=16,
imgsz=640,
lr0=0.001, # 可选:调整学习率
flipud=0.5 # 可选:新增数据增强
)
3、 训练脚本
from ultralytics import YOLO
import torch
import cv2
import matplotlib.pyplot as plt
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
def train():
# model = YOLO("./ultralytics/cfg/models/v8/mtyolov8.yaml") #未预训练
model = YOLO("./yolov8n.pt") #官方模型,预训练过
# model = YOLO('yolov8s-obb.yaml').load('yolov8s-obb.pt')
# model = YOLO("runs/detect/train54/weights/last.pt") #继续训练
model.train(data="./test2.yaml", epochs=500) #改为自己写的yaml文件路径
result = model.val()
if __name__ == '__main__':
train()
4、训练完后,如何进行预测?
下面是腾通元宝给出的代码。
from ultralytics import YOLO
# 加载模型
model = YOLO("runs/detect/train/weights/best.pt") # 替换为你的权重路径
# 预测单张图像
results = model.predict("test.jpg", save=True) # save=True 保存结果到 runs/detect/predict
# 预测文件夹内所有图像
results = model.predict("input_images/", save=True)
# 预测视频文件
results = model.predict("video.mp4", save=True, imgsz=1280)
# 使用摄像头(ID=0表示默认摄像头)
results = model.predict(source=0, show=True, stream=True) # stream=True 启用实时模式
# 按ESC退出
while True:
for result in results:
cv2.waitKey(1)
if cv2.waitKey(1) == 27: # ESC键
break
5、预测脚本
from ultralytics import YOLO
import torch
import cv2
import matplotlib.pyplot as plt
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
def predict():
model = YOLO("runs/detect/train55/weights/best.pt") #改为训练好的best.pt文件路径
results = model.predict("WPS拼图0.jpg", save=True) #改为预测单张图片的路径
if __name__ == '__main__':
predict()
6、如何进行数据扩充?
利用有限的数据集,经过图像变换获得大量数据集,更改range内的值就能获得不同数据量的数据。
# -*- coding: utf-8 -*-
import cv2
import os
import numpy as np
from albumentations import (
HorizontalFlip, VerticalFlip, Rotate, RandomBrightnessContrast,
Compose, OneOf
)
# 配置路径(使用独立输出目录)
input_images_dir = r"D:\backup\images"
input_labels_dir = r"D:\backup\labels"
output_images_dir = r"D:\backup\images_aug" # 新增目录防止覆盖
output_labels_dir = r"D:\backup\labels_aug"
# 创建输出目录(强制UTF-8编码)
os.makedirs(output_images_dir, exist_ok=True)
os.makedirs(output_labels_dir, exist_ok=True)
# 定义增强管道(YOLO格式专用)
aug = Compose([
OneOf([
HorizontalFlip(p=0.5),
VerticalFlip(p=0.5),
Rotate(limit=15, border_mode=cv2.BORDER_CONSTANT, p=0.5)
], p=0.8),
RandomBrightnessContrast(brightness_limit=0.2, contrast_limit=0.2, p=0.5)
], bbox_params={'format': 'yolo', 'label_fields': ['class_labels']})
# 遍历处理文件
for img_name in os.listdir(input_images_dir):
# 处理中文文件名乱码
try:
img_name_decoded = img_name.encode('cp1252').decode('gbk')
except UnicodeDecodeError:
img_name_decoded = img_name.encode('utf-8').decode('gbk', 'ignore')
# 过滤非图片文件
if not img_name_decoded.lower().endswith(('.jpg', '.jpeg', '.png')):
continue
# 生成路径
base_name = os.path.splitext(img_name_decoded)[0]
img_path = os.path.join(input_images_dir, img_name)
label_path = os.path.join(input_labels_dir, f"{base_name}.txt") # 关键修正
# 检查文件存在性
if not os.path.exists(img_path):
print(f"图片不存在: {img_path}")
continue
if not os.path.exists(label_path):
print(f"标签不存在: {label_path}")
continue
# 读取图片
img = cv2.imread(img_path)
if img is None:
print(f"图片读取失败: {img_path}")
continue
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 解析YOLO标签
with open(label_path, 'r') as f:
lines = f.readlines()
bboxes = []
class_labels = []
for line in lines:
parts = line.strip().split()
if len(parts) != 5:
print(f"无效标签格式: {label_path}")
continue
class_id, x_center, y_center, width, height = map(float, parts)
bboxes.append([x_center, y_center, width, height])
class_labels.append(class_id)
# 应用增强(每个样本生成35个增强版本)
for aug_idx in range(35):
try:
augmented = aug(image=img, bboxes=bboxes, class_labels=class_labels)
except Exception as e:
print(f"增强失败: {img_path} - {str(e)}")
continue
aug_img = augmented['image']
aug_bboxes = augmented['bboxes']
aug_labels = augmented['class_labels']
# 生成新文件名
new_base_name = f"{base_name}_aug{aug_idx}"
new_img_name = f"{new_base_name}.jpg"
new_label_name = f"{new_base_name}.txt"
# 保存增强图片
aug_img_bgr = cv2.cvtColor(aug_img, cv2.COLOR_RGB2BGR)
cv2.imwrite(os.path.join(output_images_dir, new_img_name), aug_img_bgr)
# 保存新标签(过滤越界坐标)
with open(os.path.join(output_labels_dir, new_label_name), 'w') as f:
for label, bbox in zip(aug_labels, aug_bboxes):
# 坐标合法性检查
if any(coord < 0 or coord > 1 for coord in bbox):
continue
line = f"{int(label)} {bbox[0]:.6f} {bbox[1]:.6f} {bbox[2]:.6f} {bbox[3]:.6f}\n"
f.write(line)
print(f"增强完成!结果保存在: {output_images_dir}")
将模型转换为onnx:yolo mode=export model=runs/detect/train72/weights/best.pt format=onnx simplify=True(注意改model后面的路径),参考:yolov8.1超简单环境搭建、标注、训练、转onnx、转输出维度
7、OCR入门
参考视频:Python 实现 OCR 识别提取图片文字,多语言支持,步骤简单小白也能学
二、YOLOv8改进
1.添加注意力机制模块
参考资料:YOLOv8模型改进 第九讲 添加EMAttention注意力机制
2.添加损失函数
参考资料:YOLOv8模型改进 第十一讲 添加自适应阈值焦点损失(ATFL)函数解决类别不平衡
3.替换优化器
参考资料:Yolov8目标检测模型改进 模型替换 优化器 一通百通
三、OCR模块改进
1. 智能倾斜旋转
2. 药品数据库辅助
3. 借助大模型纠正
四、SQLite
参考资料:世界上装机量最大的数据库SQLite,低调但不小众
五、论文图像绘制
参考资料:
六、问题记录


- 训练模型是出现
WARNING NMS time limit 2.150s exceeded解决方法。 - VSCode用jupyter绘图时出现例如
<Figure size 600x600 with 1 Axes>解决方法:在导入库的代码之后添加%matplotlib inline。 - 在VSCode中如果运行代码出现
FileNotFoundError: [WinError 3] 系统找不到指定的路径。: './images'类似问题 解决方法:将./images路径改为绝对路径,具体方法:右键点击复制路径,注意将路径中的\改为/。 建议能使用绝对路径就尽量使用绝对路径(看需要,有的则只需要相对路径即可,具体问题具体分析)。 - 报错
OutOfMemoryError: CUDA out of memory. Tried to allocate 16.00 MiB (GPU 0; 4.00 GiB total capacity; 2.72 GiB already allocated; 0 bytes free; 2.81 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF我是打开俩个VSCode进行跑了,有一个跑完没关,可能没释放内存,建议跑完一个训练模型后关掉再跑另一个,就正常训练了。 - 下载公开数据集没有
classes文件怎么知道分类,下面是腾通元宝给出的代码,可以知道分类。其实看labels文件夹里面的txt文件的命名方式即可。如car_001.jpg,person_005.png(如果都是数字,则一般第一个数字是类别,结合具体图片了解后面数字代表含义) - 报错
RuntimeError: DataLoader worker (pid(s) 43684, 32944, 31592) exited unexpectedly。解决方法:在命令行python下import torch torch.cuda.empty_cache() # 如果使用 GPU 可行 exit()重新运行训练代码即可(或者关闭一些无用的后台应用,减少内存占用)。 - 数据集太大,需要自己手动标注,或者用自动标注后需要手动修改,记得一定要勾选自动保存,不然一切重头开始,真的很搞心态。
import os
def find_classes(label_dir):
class_ids = set()
# 遍历所有标签文件
for label_file in os.listdir(label_dir):
if not label_file.endswith(".txt"):
continue # 跳过非txt文件
file_path = os.path.join(label_dir, label_file)
with open(file_path, 'r') as f:
for line in f:
parts = line.strip().split()
if len(parts) >= 5: # YOLO格式至少5个值(class, cx, cy, w, h)
class_id = int(parts[0])
class_ids.add(class_id)
return sorted(class_ids)
# 使用示例
label_dir = "dataset/labels/" # 根据实际情况修改路径
detected_classes = find_classes(label_dir)
print(f"数据集中存在的类别ID: {detected_classes}")
# 生成classes.txt(需手动映射ID到名称)
with open("dataset/classes.txt", 'w') as f: # 根据实际情况修改路径
f.write("\n".join(map(str, detected_classes)))
yaml文件修改后记得按ctrl加s保存,再训练,不然会报错。- 使用
cursor提问chat修改代码时,最好给出文件给它提问,这样可能会更快达到预期。 - 有时候不知道为什么无缘无故运行
python代码会出现莫名其妙的语法错误,而且在cursor中不报错,在VsCode中就报错,没搞懂为什么?但是删了这个文件重建一个文件,把内容拷贝过去就可以了,懂的大佬可以评论解释一下。 - Tensorrt部署问题:
- 解决问题:Could not locate zlibwapi.dll. Please make sure it is in your library path!
RuntimeError: failed to load ONNX file原因:路径中存在中文(中文路径害人不浅啊 呜呜呜)把pt模型或onnx模型移动到一个路径没有中文的目录下再转Tensorrt的engine模型。
- 微信开发者工具真机调试报错:
“errno“: 600001, “errMsg“: “request:fail -2:net::ERR_FAILED“,但是电脑端直接预览没有错,我搜了资料说是“手机和电脑不在同一个局域网,或者在了同一个局域网内IP地址没写对”,参考:解决微信小程序真机测试出现errno:600001错误,但我检查了,都是一致的。结果我发现我手机开的vpn,把vpn关掉就行了。 - 不能语音播报?手机开静音模式了,笑了。
七、模型评价(性能指标)
参考:【YOLOv8小白入门09】目标检测模型性能指标;深度学习实验部分常见疑问解答三!(怎么判断模型是否收敛?模型过拟合怎么办?);Yolov8网络模型训练参数详解
论文中图像绘制:手把手教你YOLOv8画对比图,画改进后的对比图,支持多个实验结果,写作和科研必备(全网最详细)
八、前端:微信小程序速成
建议:前后端开发同时进行,先完成接口,先完成再完善。
参考视频及资料:
重点笔记及摘要:
app.json文件不能写任何注释
九、后端:Flask速成
建议:前后端开发同时进行,先完成接口,先完成再完善。
十、云服务器的使用:部署后端代码
- 为什么要用云服务器?:用
Flask部署有网络IP限制:手机与电脑连接同一个网络或热点才能正常运行,若要解除这个限制,就用到了云服务器。- 参考资料:一文教你免费拥有,阿里云、腾讯云服务器!
- 如何上传自己电脑上的文件/项目到云服务器上?
使用 WinSCP(图形界面,更直观) (具体使用方法参考文件传输工具WinSCP安装与使用教程)
- 域名申请
十一、好用工具
- git入门使用,参考给傻子的Git教程(国内版)、【VSCode ☆ Git 】最佳代码管理 ➔ 高效且优雅
- Overleaf & Latex 的使用,参考8分钟入门 Overleaf & Latex
- Github Copilot的使用,参考【编程神器】免费使用Github Copilot:手把手教你注册与使用
- iPhone手机拍摄的照片为HEIC格式,建议转成JPG、JPEG、PNG、BMP等格式,再进行标注。方法:下载CopyTrans HEIC进行转换
- Cursor的使用:参考【Cursor最直观教程】手把手教小白如何8分钟用Cursor完成AI微信小程序的开发上线
- 白嫖教程(目前可能某些原因白嫖不了了,可以去某宝或某多搜索一下相关的东西,半白嫖也算嫖):普通人也可以看的 AI 编程指南 | Cursor 教程|Cursor 使用技巧和思路|如何免费使用 Cursor|AI 编程
- 自动标注:参考超强免费的中文YOLO自动标注工具~
十二、参考视频及资料
最后
- AIGC率到底应该怎么降?
网上很多人说利用ai来降ai,但本人越降越高,所以放弃了该方法。若ai率很高,那么查重率应该很低,这两者需要有一个权衡,也就是可以通过提高查重率来降低ai率,本人是一段一段用自己的话来转述ai的话,同时引用文献进去,穿插到ai的话中,也要调整ai的句式结构,加些口语化的词这样。若是字数足够的话,直接删除ai率较高的段落是一种简单的降ai方法。(还有一种方法,但博主没实践过,就是通过往论文中添加代码从而增加论文字数,而代码很难增加查重率和ai率,由此降低ai率,理论上可行,但博主没实践过)
毕设闲暇之余或标图片期间,无聊可以看易中天教授、王立群教授、毕淑敏作家等所讲的百家讲坛,尤其推荐 易中天 教授,讲得十分生动有趣,十分有意思。
学习资料:YouTube CCTV百家讲坛官方频道
- 最近在追 《棋士》,很好看。但我感觉:世界上只有一种病——穷病。
- 《漫长的季节》 也不错,之前没看,现在补上。


















 2272
2272

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











